- Page 1 and 2:
July 2007 Volume 10 Number 3
- Page 3 and 4:
Advertisements Educational Technolo
- Page 5 and 6:
Distinguishing between games and si
- Page 7 and 8:
“sometimes” is less demanding t
- Page 9 and 10:
Figure 2. From generic skill to lea
- Page 11 and 12:
The large window on the left presen
- Page 13 and 14:
define competencies of individual a
- Page 15 and 16:
competency is composed of a single
- Page 17 and 18:
Generic Skills Classes 1 2 3 Receiv
- Page 19 and 20:
Figure 6. Extension of the competen
- Page 21 and 22:
Competency scale By combining the g
- Page 23 and 24:
activities, and resources present i
- Page 25 and 26:
Conclusion The importance given to
- Page 27 and 28:
Ainsworth, S. (2007). Using a Singl
- Page 29 and 30:
different instruction. For example,
- Page 31 and 32:
Author-focused studies Studies 1 an
- Page 33 and 34:
egression showed that students were
- Page 35 and 36:
REDEEM is now a senior citizen in t
- Page 37 and 38:
Chieu, V. M. (2007). An Operational
- Page 39 and 40:
When students discuss with peers, t
- Page 41 and 42:
COFALE as a learning environment an
- Page 43 and 44:
COFALE supports a set of predefined
- Page 45 and 46:
Tom is asked to prepare a list of g
- Page 47 and 48:
45-minute-long lecture and 2-hour-l
- Page 49 and 50:
as an easy-to-use technological mea
- Page 51 and 52:
Spiro, R. J., & Jehng, J. C. (1990)
- Page 53 and 54:
learning settings. However, such a
- Page 55 and 56: introduced in the LOCO-Cite ontolog
- Page 57 and 58: ‘virtual subsection’) of the LO
- Page 59 and 60: Accordingly, TANGRAM provides stude
- Page 61 and 62: learning environment is to define t
- Page 63 and 64: Acknowledgment This work is support
- Page 65 and 66: Dron, J. (2007). Designing the Unde
- Page 67 and 68: wikis and blogs (or at least, colle
- Page 69 and 70: The darker side of social software
- Page 71 and 72: for the beetles, whose guts act as
- Page 73 and 74: The principle of sociability The pr
- Page 75 and 76: Bonabeau, E., Dorigo, M., & Theraul
- Page 77 and 78: Klamma, R., Chatti, M. A., Duval, E
- Page 79 and 80: We perceive adaptivity and personal
- Page 81 and 82: Mixed-method evaluation approach tr
- Page 83 and 84: Garden of Knowledge - with a commun
- Page 85 and 86: equirements for collaborative adapt
- Page 87 and 88: Law, E. L.-C., & Hvannberg, E. T. (
- Page 89 and 90: Wang, T. I., Tsai, K. H., Lee, M. C
- Page 91 and 92: 2.3 Recommendation Model Survey In
- Page 93 and 94: Figure 1. The portion of the concep
- Page 95 and 96: STEP4: Associated with concepts in
- Page 97 and 98: A modified TF-IDF approach is used
- Page 99 and 100: P(CK j x LOM ) = k NW max ∀ T∈
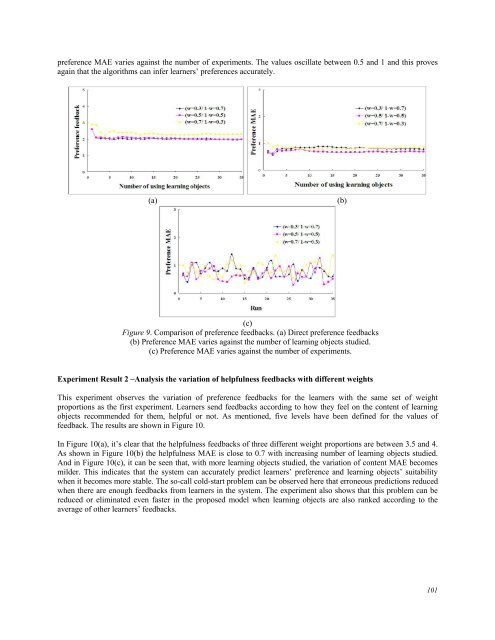
- Page 101 and 102: 4.2.2 Correlation-based algorithm I
- Page 103 and 104: content feedback, it can be intuiti
- Page 105: 66% improvement in average, and, wh
- Page 109 and 110: index.aspx. ADL-2 (2001). Advanced
- Page 111 and 112: Wolpers, M., Najjar, J., Verbert, K
- Page 113 and 114: activity is taking place. For examp
- Page 115 and 116: Figure 2: The CAM schema elements (
- Page 117 and 118: • Context: the context element ca
- Page 119 and 120: 4.1 Generation of Attention Metadat
- Page 121 and 122: addition, such keywords can be extr
- Page 123 and 124: Action related data, data about sea
- Page 125 and 126: Braun, S., & Schmidt, A. (2006). Do
- Page 127 and 128: El-Bishouty, M. M., Ogata, H., & Ya
- Page 129 and 130: collaboration (Ogata, et al., 1999)
- Page 131 and 132: In case of LOI value is equal or cl
- Page 133 and 134: Also, the learner can click on an e
- Page 135 and 136: System Evaluation An experiment was
- Page 137 and 138: In the fifth phase, 89% of the stud
- Page 139 and 140: Fischer, G., & Konomi, S. (2005). I
- Page 141 and 142: application for specific needs, whi
- Page 143 and 144: (4) Multimedia: The truth is that e
- Page 145 and 146: Program Company Price OS 6 eZediaMX
- Page 147 and 148: Program Text editor Text import for
- Page 149 and 150: Program Sound Formats Image Formats
- Page 151 and 152: Program Image Painting Export Scrip
- Page 153 and 154: Program Effects Needs player 5 Easy
- Page 155 and 156: Program WYSIWYG Design Interactivit
- Page 157 and 158:
the grades awarded to the programs
- Page 159 and 160:
Grade Image formats Sound formats V
- Page 161 and 162:
Figure 3. Adequacy of image formats
- Page 163 and 164:
Animating objects, pictures, etc.,
- Page 165 and 166:
Educational overview Having taken m
- Page 167 and 168:
In summary, the final outcome is th
- Page 169 and 170:
Developing the Interactivity Survey
- Page 171 and 172:
technique. be treated as a desired
- Page 173 and 174:
55. A lecture in which student lear
- Page 175 and 176:
specific conclusions that researche
- Page 177 and 178:
Discussion and conclusion Although
- Page 179 and 180:
Juwah, C. (2003). Using peer assess
- Page 181 and 182:
Publish results Set a few goals for
- Page 183 and 184:
familiarity with computer terms, ex
- Page 185 and 186:
provide a framework for the integra
- Page 187 and 188:
tool themselves, and then gauge its
- Page 189 and 190:
associated with the effective use o
- Page 191 and 192:
portrayed as even more time-consumi
- Page 193 and 194:
Clarke, B. (2001). Corporate curric
- Page 195 and 196:
Neal, E. (1998). Using technology i
- Page 197 and 198:
Yearwood, J., & Stranieri, A. (2007
- Page 199 and 200:
entertaining (Neuhauser 1993). The
- Page 201 and 202:
in being addressed with the sequent
- Page 203 and 204:
The GAAM represents reasoning to a
- Page 205 and 206:
Other situations have more serious
- Page 207 and 208:
Figure 6. NARRATE phase screen afte
- Page 209 and 210:
The narration at Step 10 informs th
- Page 211 and 212:
very large degree of free-will has
- Page 213 and 214:
Rumelhart, D. E. (1975). Notes on a
- Page 215 and 216:
The School of Business at Universit
- Page 217 and 218:
Authentic assessment and OBOW exams
- Page 219 and 220:
iii. The assessment asks the studen
- Page 221 and 222:
world problems in relation to the s
- Page 223 and 224:
Herrington, J., & Herrington, A. (1
- Page 225 and 226:
services required by most clients i
- Page 227 and 228:
Wisdom. J. P., White, N., Goldsmith
- Page 229 and 230:
Work outside the U.S. has also prom
- Page 231 and 232:
of the Telecommunication Act, and t
- Page 233 and 234:
Parent-advocate respondents also re
- Page 235 and 236:
school administrators may be persua
- Page 237 and 238:
of legal requirements for accessibl
- Page 239 and 240:
Thus, while we have reason to belie
- Page 241 and 242:
underlying structure of the two pri
- Page 243 and 244:
still not familiar with its use; in
- Page 245 and 246:
Table 3: An Analysis of Different V
- Page 247 and 248:
of males. Secondly, as far as age w
- Page 249 and 250:
Conclusion This study examined the
- Page 251 and 252:
Sandholtz, J. H., Ringstaff, C., &
- Page 253 and 254:
The design and validation of a text
- Page 255 and 256:
Predetermined goal of a game The pr
- Page 257 and 258:
A true, precise and valid model “
- Page 259 and 260:
Bain, C., & Newton, C. (2003). Art
- Page 261 and 262:
Prensky, M. (2005). Adopt and Adapt
- Page 263 and 264:
opportunities based on studying dif
- Page 265 and 266:
The game -called Chase the Cheese-
- Page 267 and 268:
another token. Other tokens further
- Page 269 and 270:
The system is organized in differen
- Page 271 and 272:
“to produce a single product or p
- Page 273 and 274:
(e.g., cheese) or loses the game (a
- Page 275 and 276:
collaboration is not an easy task.
- Page 277 and 278:
Collazos, C., Ortega, M., Bravo, C.
- Page 279 and 280:
Soller, A., & Lesgold, A. (2000). K
- Page 281 and 282:
Is the usual hierarchical organizat
- Page 283 and 284:
The final step 7 in the procedure i
- Page 285 and 286:
This methodology is summarised in F
- Page 287 and 288:
‘IsBasisOf’, ‘HasConstraint
- Page 289 and 290:
The presented results are a reflect
- Page 291 and 292:
‘HasExample’, and ‘HasFurther
- Page 293 and 294:
DCMI (2003). DCMI Metadata Terms, R
- Page 295 and 296:
Literature review Astronomy educati
- Page 297 and 298:
Systems of type I provide different
- Page 299 and 300:
night. To prevent students from get
- Page 301 and 302:
Figures 2-5 display screenshots of
- Page 303 and 304:
Results of the study reveal the imp
- Page 305 and 306:
vertical axis leads to the disappea
- Page 307 and 308:
Dede, C., Salzman, M., Loftin, R. B
- Page 309 and 310:
Trumper, R. (2000). University stud
- Page 311 and 312:
ased on pre-defined adaptation rule
- Page 313 and 314:
Therefore, the higher-level items o
- Page 315 and 316:
common prefix with the existing pa
- Page 317 and 318:
later should be omitted (presented
- Page 319 and 320:
5.1 The Average Length of each Sequ
- Page 321 and 322:
Recall 6. Discussion 0.8 0.7 0.6 0.
- Page 323 and 324:
easily take lessons in a good learn
- Page 325 and 326:
Laborda, J. G., & Royo, T. M. (2007
- Page 327 and 328:
Chapter 8, Online reference tools,
- Page 329 and 330:
Kenyon, D. M., & Malabonga, V. (200
- Page 331 and 332:
and concise manner (e.g. Weeding =
- Page 333:
stream are chapters 7 and 8 which f