

Applying OLAP Pre-Aggregation Techniques to ... - Jacobs University
Applying OLAP Pre-Aggregation Techniques to ... - Jacobs University
Applying OLAP Pre-Aggregation Techniques to ... - Jacobs University

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
84 5. <strong>Pre</strong>-<strong>Aggregation</strong> Support Beyond Basic Aggregate Operations<br />
approach, but it is considered negligible since approximations are good enough for<br />
many applications. In our approach, when two or more pre-aggregates qualify for<br />
computing a given scaling operation, we pick the pre-aggregate with the closest scale<br />
vec<strong>to</strong>r value <strong>to</strong> the one defined in the scaling operation.<br />
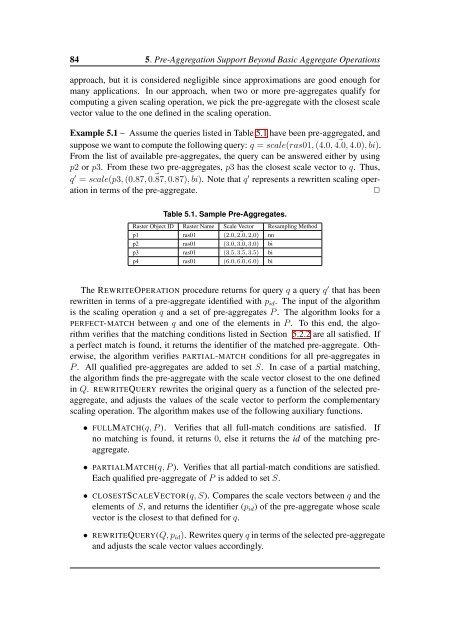
Example 5.1 – Assume the queries listed in Table 5.1 have been pre-aggregated, and<br />
suppose we want <strong>to</strong> compute the following query: q = scale(ras01, (4.0, 4.0, ⃗ 4.0), bi).<br />
From the list of available pre-aggregates, the query can be answered either by using<br />
p2 or p3. From these two pre-aggregates, p3 has the closest scale vec<strong>to</strong>r <strong>to</strong> q. Thus,<br />
q ′ = scale(p3, (0.87, 0.87, ⃗ 0.87), bi). Note that q ′ represents a rewritten scaling operation<br />
in terms of the pre-aggregate.<br />
✷<br />
Table 5.1. Sample <strong>Pre</strong>-Aggregates.<br />
Raster Object ID Raster Name Scale Vec<strong>to</strong>r Resampling Method<br />
p1 ras01 (2.0, 2.0, ⃗ 2.0) nn<br />
p2 ras01 (3.0, 3.0, ⃗ 3.0) bi<br />
p3 ras01 (3.5, 3.5, ⃗ 3.5) bi<br />
p4 ras01 (6.0, 6.0, ⃗ 6.0) bi<br />
The REWRITEOPERATION procedure returns for query q a query q ′ that has been<br />
rewritten in terms of a pre-aggregate identified with p id . The input of the algorithm<br />
is the scaling operation q and a set of pre-aggregates P . The algorithm looks for a<br />
PERFECT-MATCH between q and one of the elements in P . To this end, the algorithm<br />
verifies that the matching conditions listed in Section 5.2.2 are all satisfied. If<br />
a perfect match is found, it returns the identifier of the matched pre-aggregate. Otherwise,<br />
the algorithm verifies PARTIAL-MATCH conditions for all pre-aggregates in<br />
P . All qualified pre-aggregates are added <strong>to</strong> set S. In case of a partial matching,<br />
the algorithm finds the pre-aggregate with the scale vec<strong>to</strong>r closest <strong>to</strong> the one defined<br />
in Q. REWRITEQUERY rewrites the original query as a function of the selected preaggregate,<br />
and adjusts the values of the scale vec<strong>to</strong>r <strong>to</strong> perform the complementary<br />
scaling operation. The algorithm makes use of the following auxiliary functions.<br />
• FULLMATCH(q, P ). Verifies that all full-match conditions are satisfied. If<br />
no matching is found, it returns 0, else it returns the id of the matching preaggregate.<br />
• PARTIALMATCH(q, P ). Verifies that all partial-match conditions are satisfied.<br />
Each qualified pre-aggregate of P is added <strong>to</strong> set S.<br />
• CLOSESTSCALEVECTOR(q, S). Compares the scale vec<strong>to</strong>rs between q and the<br />
elements of S, and returns the identifier (p id ) of the pre-aggregate whose scale<br />
vec<strong>to</strong>r is the closest <strong>to</strong> that defined for q.<br />
• REWRITEQUERY(Q, p id ). Rewrites query q in terms of the selected pre-aggregate<br />
and adjusts the scale vec<strong>to</strong>r values accordingly.













