

Embedded Computing Design - OpenSystems Media
Embedded Computing Design - OpenSystems Media
Embedded Computing Design - OpenSystems Media

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
silicon resources of an FPGA lead to<br />
staggering performance gains – while the<br />
fastest general purpose can deliver up to<br />
5 billion MAC/s (multiply-accumulate<br />
per second), leading FPGA devices can<br />
deliver more than 500 billion MAC/s –<br />
that’s more than 100x faster. What’s more,<br />
channelized applications such as those<br />
common to wireless communications<br />
naturally lend themselves to parallel implementations<br />
in FPGAs. Growth rates<br />
in processing speed requirements versus<br />
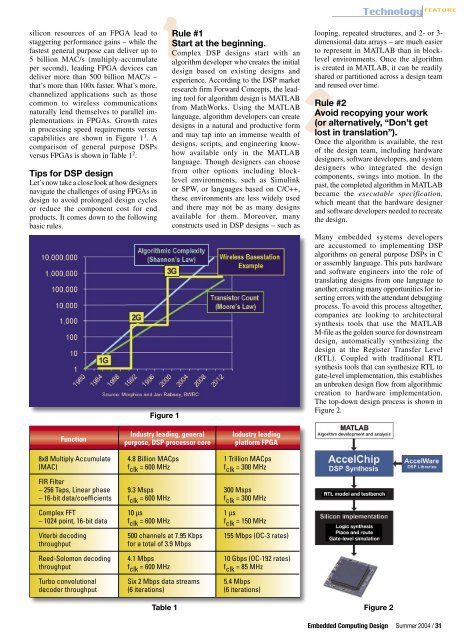
capabilities are shown in Figure 1 1 . A<br />
comparison of general purpose DSPs<br />
versus FPGAs is shown in Table 1 2 .<br />
Tips for DSP design<br />
Let’s now take a close look at how designers<br />
navigate the challenges of using FPGAs in<br />
design to avoid prolonged design cycles<br />
or reduce the component cost for end<br />
products. It comes down to the following<br />
basic rules.<br />
1<br />
Figure 1<br />
Rule #1<br />
Start at the beginning.<br />
Complex DSP designs start with an<br />
algorithm developer who creates the initial<br />
design based on existing designs and<br />
experience. According to the DSP market<br />
research firm Forward Concepts, the leading<br />
tool for algorithm design is MATLAB<br />
from MathWorks. Using the MATLAB<br />
language, algorithm developers can create<br />
designs in a natural and productive form<br />
and may tap into an immense wealth of<br />
designs, scripts, and engineering knowhow<br />
available only in the MATLAB<br />
language. Though designers can choose<br />
from other options including blocklevel<br />
environments, such as Simulink<br />
or SPW, or languages based on C/C++,<br />
these environments are less widely used<br />
and there may not be as many designs<br />
available for them. Moreover, many<br />
constructs used in DSP designs – such as<br />
looping, repeated structures, and 2- or 3-<br />
dimensional data arrays – are much easier<br />
to represent in MATLAB than in blocklevel<br />
environments. Once the algorithm<br />
is created in MATLAB, it can be readily<br />
shared or partitioned across a design team<br />
and reused over time.<br />
2<br />
Rule #2<br />
Avoid recopying your work<br />
(or alternatively, “Don’t get<br />
lost in translation”).<br />
Once the algorithm is available, the rest<br />
of the design team, including hardware<br />
designers, software developers, and system<br />
designers who integrated the design<br />
components, swings into motion. In the<br />
past, the completed algorithm in MATLAB<br />
became the executable specification,<br />
which meant that the hardware designer<br />
and software developers needed to recreate<br />
the design.<br />
Many embedded systems developers<br />
are accustomed to implementing DSP<br />
algorithms on general purpose DSPs in C<br />
or assembly language. This puts hardware<br />
and software engineers into the role of<br />
translating designs from one language to<br />
another, creating many opportunities for inserting<br />
errors with the attendant debugging<br />
process. To avoid this process altogether,<br />
companies are looking to architectural<br />
synthesis tools that use the MATLAB<br />
M-file as the golden source for downstream<br />
design, automatically synthesizing the<br />
design at the Register Transfer Level<br />
(RTL). Coupled with traditional RTL<br />
synthesis tools that can synthesize RTL to<br />
gate-level implementation, this establishes<br />
an unbroken design flow from algorithmic<br />
creation to hardware implementation.<br />
The top-down design process is shown in<br />
Figure 2.<br />
Function<br />
Industry leading, general<br />
purpose, DSP processor core<br />
Industry leading<br />
platform FPGA<br />
8x8 Multiply Accumulate 4.8 Billion MACps 1 Trillion MACps<br />
(MAC) f clk = 600 MHz f clk = 300 MHz<br />
FIR Filter<br />
– 256 Taps, Linear phase 9.3 Msps 300 Msps<br />
– 16-bit data/coefficients f clk = 600 MHz f clk = 300 MHz<br />
Complex FFT 10 µs 1 µs<br />
– 1024 point, 16-bit data f clk = 600 MHz f clk = 150 MHz<br />
Viterbi decoding 500 channels at 7.95 Kbps 155 Mbps (OC-3 rates)<br />
throughput<br />
for a total of 3.9 Mbps<br />
Reed-Solomon decoding 4.1 Mbps 10 Gbps (OC-192 rates)<br />
throughput f clk = 600 MHz f clk = 85 MHz<br />
Turbo convolutional Six 2 Mbps data streams 5.4 Mbps<br />
decoder throughput (6 iterations) (6 iterations)<br />
Table 1<br />
Figure 2<br />
<strong>Embedded</strong> <strong>Computing</strong> <strong>Design</strong> Summer 2004 / 31













