Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
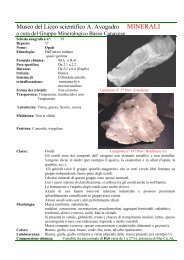
Viviamo in un mondo avaro, baby! 81<br />
”1”2”3<br />
Come si comporta la regexpr? Facciamo una completa analisi della logica usata per<br />
tentare il match. Mano a mano che procediamo nella simulazione della logica della<br />
regexpr, “taglieremo” per così dire le parti di testo che hanno fallito definitivamente il<br />
match.<br />
Il primo tentativo avviene sul primo carattere di virgolette in posizione 1. Il match su<br />
quel carattere è positivo in quanto il primo carattere della stringa deve essere un carattere<br />
di virgolette. Quindi si procede al carattere successivo. La seconda virgoletta non è però<br />
accettabile in quanto il carattere successivo può essere qualsiasi tranne la virgoletta stessa.<br />
Il motore che esegue la ricerca decide che questa via è definitivamente infruttuosa e<br />
ne tenta un’altra. Scartato il primo carattere, prova ripartendo dal secondo; la stringa<br />
rimanente risulta così essere:<br />
”2”3<br />
secondo tentativo<br />
Questo è prevedibilmente positivo sul primo carattere (ossia quello in posizione 2), ma<br />
nuovamente il secondo carattere (in posizione 3) non soddisfa il match per lo stesso motivo<br />
per il quale il carattere in posizione 2 non lo soddisfaceva al tentativo precedente.<br />
Nuovamente si decide che questa strada non può portare ad alcun match e si intraprende<br />
un terzo tentativo. Quest’ultimo risulta ancora più breve.<br />
”3<br />
terzo tentativo<br />
La terza virgoletta è conforme al match ma dopo di essa non segue più alcun carattere.<br />
Questo determina il fallimento definitivo anche di questo tentativo e per conseguenza<br />
dell’intera regexpr sulla stringa.<br />
Ammettiamo ora di voler sperimentare come si comporti la regexpr dopo una breve<br />
plastica. Diciamo che il punto di domanda diventa un asterisco, con il seguente risultato:<br />
/"[^"]*"/<br />
Riesaminiamo il processo di ricerca a partire da zero. La stringa è sempre costituita da<br />
tre virgolette in sequenza:<br />
”1”2”3<br />
Tentando con il primo carattere anche questa regexpr leggermente differente ha successo.<br />
È già a partire dal secondo carattere che si ha una notevole differenza di comportamento.<br />
Il secondo carattere può essere tanto un carattere qualsiasi purché differente da una<br />
virgoletta, quanto una virgoletta. Attenzione: la ridondanza è solo apparente. C’è infatti<br />
sostanziale differenza fra incontrare una virgoletta e un altro carattere. Una virgoletta<br />
chiuderebbe il match, mentre un altro carattere no, consentendo di cercare un ulteriore<br />
carattere diverso da una virgoletta.<br />
In sostanza la regexpr al secondo carattere di virgolette (in questo caso) è già<br />
soddisfatta. Questo comporta che la porzione di testo riscontrata viene ritornata come<br />
esito della ricerca e la riga viene abbandonata. Infatti una regexpr non tenta mai<br />
autonomamente un secondo match su una riga che ne ha già prodotto uno. 10<br />
Se il carattere in posizione 2 fosse stato un altro (es. una lettera c) il match non si<br />
sarebbe concluso lì, ma sarebbe proseguito sino al terzo carattere, risultando nella stringa<br />
"c". Non pensate mai tuttavia che se una stringa contiene un match più ricco (contenente<br />
più caratteri) le regexpr lo preferiscano ad uno più povero. Non è questo lo scopo<br />
10 A meno che questo non venga esplicitamente richiesto.<br />
“Opzioni ed altre meraviglie”<br />
Si veda a proposito il paragrafo