- Seite 1:
Ein kleiner Überblick überNeurona
- Seite 5 und 6:
VorwörtchenDiese Arbeit ist urspr
- Seite 7 und 8:
dkriesel.comStils sind, bin ich (zu
- Seite 9 und 10:
dkriesel.comKapitelübergreifende m
- Seite 11 und 12:
InhaltsverzeichnisVorwörtchenvIVon
- Seite 13 und 14:
dkriesel.comInhaltsverzeichnis4.6 B
- Seite 15 und 16:
dkriesel.comInhaltsverzeichnis10.2
- Seite 17:
Teil IVon der Biologie zur Formalis
- Seite 20 und 21:
Kapitel 1 Einleitung, Motivation un
- Seite 22 und 23:
Kapitel 1 Einleitung, Motivation un
- Seite 24 und 25:
Kapitel 1 Einleitung, Motivation un
- Seite 26 und 27:
Kapitel 1 Einleitung, Motivation un
- Seite 28 und 29:
Kapitel 1 Einleitung, Motivation un
- Seite 31 und 32:
Kapitel 2Biologische Neuronale Netz
- Seite 33 und 34:
dkriesel.com2.1 Das Nervensystem vo
- Seite 35 und 36:
dkriesel.com2.2 Das Neuron2.2 Neuro
- Seite 37 und 38:
dkriesel.com2.2 Das Neuronge von De
- Seite 39 und 40:
dkriesel.com2.2 Das NeuronZellinner
- Seite 41 und 42:
dkriesel.com2.2 Das Neuronerreicht
- Seite 43 und 44:
dkriesel.com2.3 RezeptorzellenSchal
- Seite 45 und 46:
dkriesel.com2.3 Rezeptorzellen2.3.3
- Seite 47 und 48:
dkriesel.com2.4 Neuronenmengen in L
- Seite 49 und 50:
dkriesel.com2.5 Technische Neuronen
- Seite 51 und 52:
Kapitel 3Bausteine künstlicher Neu
- Seite 53 und 54:
dkriesel.com3.2 Bestandteile Neuron
- Seite 55 und 56:
dkriesel.com3.2 Bestandteile Neuron
- Seite 57 und 58:
dkriesel.com3.3 Verschiedene Netzto
- Seite 59 und 60:
dkriesel.com3.3 Verschiedene Netzto
- Seite 61 und 62: dkriesel.com3.4 Das Biasneuron3.3.3
- Seite 63 und 64: dkriesel.com3.6 Aktivierungsreihenf
- Seite 65 und 66: dkriesel.com3.7 Ein- und Ausgabe vo
- Seite 67 und 68: Kapitel 4Gedanken zum Training Neur
- Seite 69 und 70: dkriesel.com4.1 Paradigmen des Lern
- Seite 71 und 72: dkriesel.com4.2 Trainingsmuster und
- Seite 73 und 74: dkriesel.com4.3 Umgang mit Training
- Seite 75 und 76: dkriesel.com4.4 Lernkurve und Fehle
- Seite 77 und 78: dkriesel.com4.5 Gradientenbasierte
- Seite 79 und 80: dkriesel.com4.6 Beispielproblemstel
- Seite 81 und 82: dkriesel.com4.6 Beispielproblemstel
- Seite 83 und 84: dkriesel.com4.7 Hebbsche LernregelG
- Seite 85: Teil IIÜberwacht lernendeNetzparad
- Seite 88 und 89: Kapitel 5 Das Perceptrondkriesel.co
- Seite 90 und 91: Kapitel 5 Das Perceptrondkriesel.co
- Seite 92 und 93: Kapitel 5 Das Perceptrondkriesel.co
- Seite 94 und 95: Kapitel 5 Das Perceptron543210dkrie
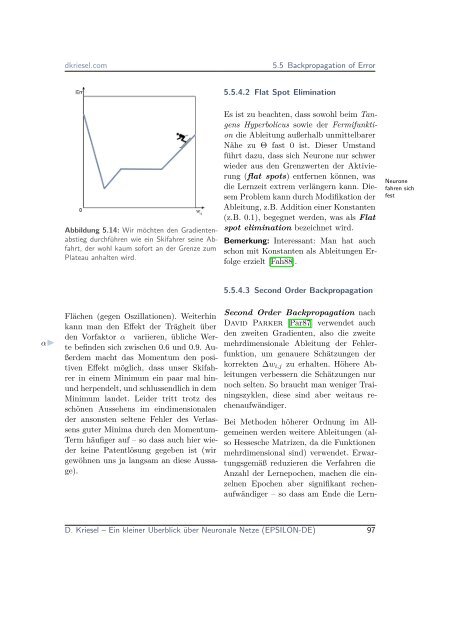
- Seite 96 und 97: Kapitel 5 Das Perceptrondkriesel.co
- Seite 98 und 99: Kapitel 5 Das Perceptrondkriesel.co
- Seite 100 und 101: Kapitel 5 Das Perceptrondkriesel.co
- Seite 102 und 103: Kapitel 5 Das Perceptrondkriesel.co
- Seite 104 und 105: Kapitel 5 Das Perceptrondkriesel.co
- Seite 106 und 107: Kapitel 5 Das Perceptrondkriesel.co
- Seite 108 und 109: Kapitel 5 Das Perceptrondkriesel.co
- Seite 110 und 111: Kapitel 5 Das Perceptrondkriesel.co
- Seite 114 und 115: Kapitel 5 Das Perceptrondkriesel.co
- Seite 116 und 117: Kapitel 5 Das Perceptrondkriesel.co
- Seite 119 und 120: Kapitel 6Radiale BasisfunktionenRBF
- Seite 121 und 122: dkriesel.com6.1 Bestandteile und Au
- Seite 123 und 124: dkriesel.com6.2 Informationsverarbe
- Seite 125 und 126: dkriesel.com6.2 Informationsverarbe
- Seite 127 und 128: dkriesel.com6.2 Informationsverarbe
- Seite 129 und 130: dkriesel.com6.3 Training von RBF-Ne
- Seite 131 und 132: dkriesel.com6.3 Training von RBF-Ne
- Seite 133 und 134: dkriesel.com6.4 Wachsende RBF-Netze
- Seite 135: dkriesel.com6.5 Gegenüberstellung
- Seite 138 und 139: Kapitel 7 Rückgekoppelte Netze (ba
- Seite 140 und 141: Kapitel 7 Rückgekoppelte Netze (ba
- Seite 142 und 143: Kapitel 7 Rückgekoppelte Netze (ba
- Seite 144 und 145: Kapitel 7 Rückgekoppelte Netze (ba
- Seite 146 und 147: Kapitel 8 Hopfieldnetzedkriesel.com
- Seite 148 und 149: Kapitel 8 Hopfieldnetzedkriesel.com
- Seite 150 und 151: Kapitel 8 Hopfieldnetzedkriesel.com
- Seite 152 und 153: Kapitel 8 Hopfieldnetzedkriesel.com
- Seite 154 und 155: Kapitel 8 Hopfieldnetzedkriesel.com
- Seite 156 und 157: Kapitel 9 Learning Vector Quantizat
- Seite 158 und 159: Kapitel 9 Learning Vector Quantizat
- Seite 161: Teil IIIUnüberwacht lernendeNetzpa
- Seite 164 und 165:
Kapitel 10 Self Organizing Feature
- Seite 166 und 167:
Kapitel 10 Self Organizing Feature
- Seite 168 und 169:
Kapitel 10 Self Organizing Feature
- Seite 170 und 171:
Kapitel 10 Self Organizing Feature
- Seite 172 und 173:
Kapitel 10 Self Organizing Feature
- Seite 174 und 175:
Kapitel 10 Self Organizing Feature
- Seite 176 und 177:
Kapitel 10 Self Organizing Feature
- Seite 178 und 179:
Kapitel 10 Self Organizing Feature
- Seite 180 und 181:
Kapitel 10 Self Organizing Feature
- Seite 182 und 183:
Kapitel 10 Self Organizing Feature
- Seite 184 und 185:
Kapitel 11 Adaptive Resonance Theor
- Seite 186 und 187:
Kapitel Kapitel 11 11 Adaptive Reso
- Seite 189 und 190:
Anhang AExkurs: Clusteranalyse und
- Seite 191 und 192:
dkriesel.comA.3 ε-Nearest Neighbou
- Seite 193 und 194:
dkriesel.comA.4 Der Silhouettenkoef
- Seite 195 und 196:
dkriesel.comA.5 Regional and Online
- Seite 197 und 198:
dkriesel.comA.5 Regional and Online
- Seite 199:
dkriesel.comA.5 Regional and Online
- Seite 202 und 203:
Anhang B Exkurs: Neuronale Netze zu
- Seite 204 und 205:
Anhang B Exkurs: Neuronale Netze zu
- Seite 206 und 207:
Anhang B Exkurs: Neuronale Netze zu
- Seite 208 und 209:
Anhang B Exkurs: Neuronale Netze zu
- Seite 210 und 211:
Anhang B Exkurs: Neuronale Netze zu
- Seite 212 und 213:
Anhang C Exkurs: Reinforcement Lear
- Seite 214 und 215:
Anhang C Exkurs: Reinforcement Lear
- Seite 216 und 217:
Anhang C Exkurs: Reinforcement Lear
- Seite 218 und 219:
Anhang C Exkurs: Reinforcement Lear
- Seite 220 und 221:
Anhang C Exkurs: Reinforcement Lear
- Seite 222 und 223:
Anhang C Exkurs: Reinforcement Lear
- Seite 224 und 225:
Anhang C Exkurs: Reinforcement Lear
- Seite 226 und 227:
Anhang C Exkurs: Reinforcement Lear
- Seite 228 und 229:
Anhang C Exkurs: Reinforcement Lear
- Seite 231 und 232:
Literaturverzeichnis[And72]James A.
- Seite 233 und 234:
dkriesel.comLiteraturverzeichnis[Ko
- Seite 235:
dkriesel.comLiteraturverzeichnis[WG
- Seite 238 und 239:
Abbildungsverzeichnisdkriesel.com5.
- Seite 241:
Tabellenverzeichnis1.1 Vergleich Ge
- Seite 244 und 245:
Indexdkriesel.comBestärkendes Lern
- Seite 246 und 247:
Indexdkriesel.comLearning Vector Qu
- Seite 248 und 249:
Indexdkriesel.comPeriode . . . . .
- Seite 250:
Indexdkriesel.comThalamus . . . . .