

PDFlib Text Extraction Toolkit (TET) Manual
PDFlib Text Extraction Toolkit (TET) Manual
PDFlib Text Extraction Toolkit (TET) Manual

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
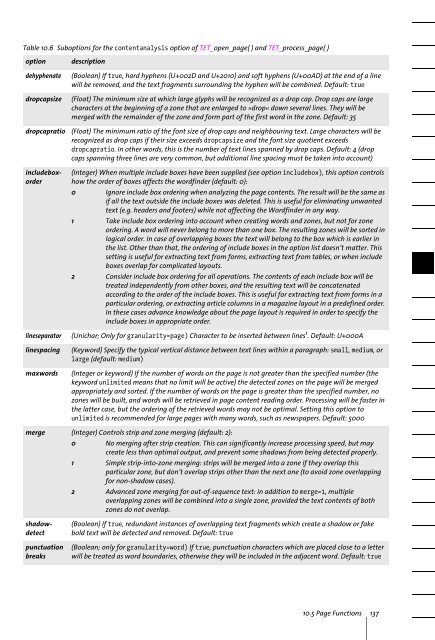
Table 10.6 Suboptions for the contentanalysis option of <strong>TET</strong>_open_page( ) and <strong>TET</strong>_process_page( )<br />
option<br />
dehyphenate<br />
dropcapsize<br />
dropcapratio<br />
lineseparator<br />
linespacing<br />
maxwords<br />
description<br />
(Boolean) If true, hard hyphens (U+002D and U+2010) and soft hyphens (U+00AD) at the end of a line<br />
will be removed, and the text fragments surrounding the hyphen will be combined. Default: true<br />
(Float) The minimum size at which large glyphs will be recognized as a drop cap. Drop caps are large<br />
characters at the beginning of a zone that are enlarged to »drop« down several lines. They will be<br />
merged with the remainder of the zone and form part of the first word in the zone. Default: 35<br />
(Float) The minimum ratio of the font size of drop caps and neighbouring text. Large characters will be<br />
recognized as drop caps if their size exceeds dropcapsize and the font size quotient exceeds<br />
dropcapratio. In other words, this is the number of text lines spanned by drop caps. Default: 4 (drop<br />
caps spanning three lines are very common, but additional line spacing must be taken into account)<br />
(Integer) When multiple include boxes have been supplied (see option includebox), this option controls<br />
how the order of boxes affects the wordfinder (default: 0):<br />
0 Ignore include box ordering when analyzing the page contents. The result will be the same as<br />
if all the text outside the include boxes was deleted. This is useful for eliminating unwanted<br />
text (e.g. headers and footers) while not affecting the Wordfinder in any way.<br />
1 Take include box ordering into account when creating words and zones, but not for zone<br />
ordering. A word will never belong to more than one box. The resulting zones will be sorted in<br />
logical order. In case of overlapping boxes the text will belong to the box which is earlier in<br />
the list. Other than that, the ordering of include boxes in the option list doesn’t matter. This<br />
setting is useful for extracting text from forms, extracting text from tables, or when include<br />
boxes overlap for complicated layouts.<br />
2 Consider include box ordering for all operations. The contents of each include box will be<br />
treated independently from other boxes, and the resulting text will be concatenated<br />
according to the order of the include boxes. This is useful for extracting text from forms in a<br />
particular ordering, or extracting article columns in a magazine layout in a predefined order.<br />
In these cases advance knowledge about the page layout is required in order to specify the<br />
include boxes in appropriate order.<br />
(Unichar; Only for granularity=page) Character to be inserted between lines 1 . Default: U+000A<br />
(Keyword) Specify the typical vertical distance between text lines within a paragraph: small, medium, or<br />
large (default: medium)<br />
(Integer or keyword) If the number of words on the page is not greater than the specified number (the<br />
keyword unlimited means that no limit will be active) the detected zones on the page will be merged<br />
appropriately and sorted. If the number of words on the page is greater than the specified number, no<br />
zones will be built, and words will be retrieved in page content reading order. Processing will be faster in<br />
the latter case, but the ordering of the retrieved words may not be optimal. Setting this option to<br />
unlimited is recommended for large pages with many words, such as newspapers. Default: 5000<br />
merge (Integer) Controls strip and zone merging (default: 2):<br />
0 No merging after strip creation. This can significantly increase processing speed, but may<br />
create less than optimal output, and prevent some shadows from being detected properly.<br />
1 Simple strip-into-zone merging: strips will be merged into a zone if they overlap this<br />
particular zone, but don’t overlap strips other than the next one (to avoid zone overlapping<br />
for non-shadow cases).<br />
2 Advanced zone merging for out-of-sequence text: in addition to merge=1, multiple<br />
overlapping zones will be combined into a single zone, provided the text contents of both<br />
zones do not overlap.<br />
includeboxorder<br />
shadowdetect<br />
punctuation<br />
breaks<br />
(Boolean) If true, redundant instances of overlapping text fragments which create a shadow or fake<br />
bold text will be detected and removed. Default: true<br />
(Boolean; only for granularity=word) If true, punctuation characters which are placed close to a letter<br />
will be treated as word boundaries, otherwise they will be included in the adjacent word. Default: true<br />
10.5 Page Functions 137













