

PDFlib Text Extraction Toolkit (TET) Manual
PDFlib Text Extraction Toolkit (TET) Manual
PDFlib Text Extraction Toolkit (TET) Manual

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
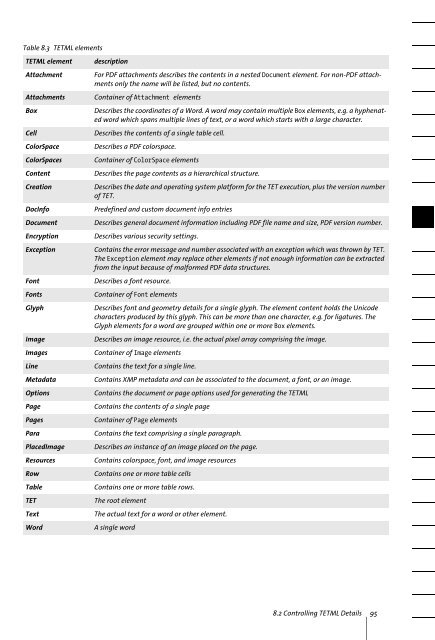
Table 8.3 <strong>TET</strong>ML elements<br />
<strong>TET</strong>ML element<br />
Attachment<br />
Attachments<br />
Box<br />
Cell<br />
ColorSpace<br />
ColorSpaces<br />
Content<br />
Creation<br />
DocInfo<br />
Document<br />
Encryption<br />
Exception<br />
Font<br />
Fonts<br />
Glyph<br />
Image<br />
Images<br />
Line<br />
Metadata<br />
Options<br />
Page<br />
Pages<br />
Para<br />
PlacedImage<br />
Resources<br />
Row<br />
Table<br />
<strong>TET</strong><br />
<strong>Text</strong><br />
Word<br />
description<br />
For PDF attachments describes the contents in a nested Document element. For non-PDF attachments<br />
only the name will be listed, but no contents.<br />
Container of Attachment elements<br />
Describes the coordinates of a Word. A word may contain multiple Box elements, e.g. a hyphenated<br />
word which spans multiple lines of text, or a word which starts with a large character.<br />
Describes the contents of a single table cell.<br />
Describes a PDF colorspace.<br />
Container of ColorSpace elements<br />
Describes the page contents as a hierarchical structure.<br />
Describes the date and operating system platform for the <strong>TET</strong> execution, plus the version number<br />
of <strong>TET</strong>.<br />
Predefined and custom document info entries<br />
Describes general document information including PDF file name and size, PDF version number.<br />
Describes various security settings.<br />
Contains the error message and number associated with an exception which was thrown by <strong>TET</strong>.<br />
The Exception element may replace other elements if not enough information can be extracted<br />
from the input because of malformed PDF data structures.<br />
Describes a font resource.<br />
Container of Font elements<br />
Describes font and geometry details for a single glyph. The element content holds the Unicode<br />
characters produced by this glyph. This can be more than one character, e.g. for ligatures. The<br />
Glyph elements for a word are grouped within one or more Box elements.<br />
Describes an image resource, i.e. the actual pixel array comprising the image.<br />
Container of Image elements<br />
Contains the text for a single line.<br />
Contains XMP metadata and can be associated to the document, a font, or an image.<br />
Contains the document or page options used for generating the <strong>TET</strong>ML<br />
Contains the contents of a single page<br />
Container of Page elements<br />
Contains the text comprising a single paragraph.<br />
Describes an instance of an image placed on the page.<br />
Contains colorspace, font, and image resources<br />
Contains one or more table cells<br />
Contains one or more table rows.<br />
The root element<br />
The actual text for a word or other element.<br />
A single word<br />
8.2 Controlling <strong>TET</strong>ML Details 95













