

Performance Analysis and Optimization of the Hurricane File System ...
Performance Analysis and Optimization of the Hurricane File System ...
Performance Analysis and Optimization of the Hurricane File System ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
CHAPTER 5. MICROBENCHMARKS – READ OPERATION 38<br />
avg # cycles per processor<br />
8e+07<br />
6e+07<br />
4e+07<br />
2e+07<br />
0e+00<br />
avg # cycles per processor<br />
4e+07<br />
3e+07<br />
2e+07<br />
1e+07<br />
0e+00<br />
2 4 6 8 10 12<br />
# processors<br />
Unoptimized<br />
Baseline<br />
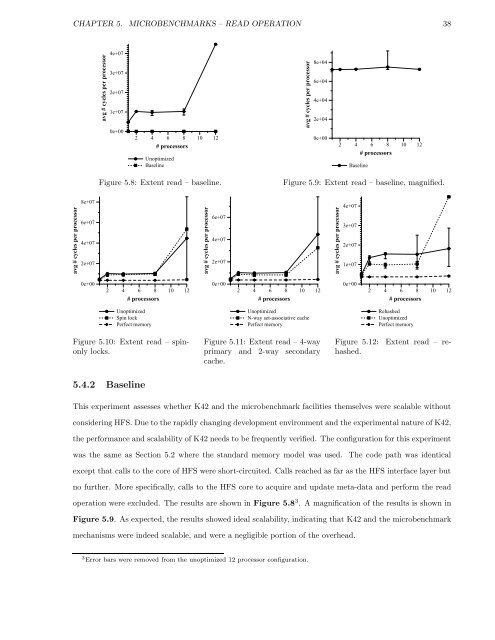
Figure 5.8: Extent read – baseline.<br />
2 4 6 8 10 12<br />
# processors<br />
Unoptimized<br />
Spin lock<br />
Perfect memory<br />
Figure 5.10: Extent read – spinonly<br />
locks.<br />
5.4.2 Baseline<br />
avg # cycles per processor<br />
6e+07<br />
4e+07<br />
2e+07<br />
0e+00<br />
avg # cycles per processor<br />
8e+04<br />
6e+04<br />
4e+04<br />
2e+04<br />
0e+00<br />
2 4 6 8 10 12<br />
# processors<br />
Unoptimized<br />
N-way set-associative cache<br />
Perfect memory<br />
Figure 5.11: Extent read – 4-way<br />
primary <strong>and</strong> 2-way secondary<br />
cache.<br />
2 4 6 8 10 12<br />
# processors<br />
Baseline<br />
Figure 5.9: Extent read – baseline, magnified.<br />
avg # cycles per processor<br />
4e+07<br />
3e+07<br />
2e+07<br />
1e+07<br />
0e+00<br />
2 4 6 8 10 12<br />
# processors<br />
Rehashed<br />
Unoptimized<br />
Perfect memory<br />
Figure 5.12: Extent read – rehashed.<br />
This experiment assesses whe<strong>the</strong>r K42 <strong>and</strong> <strong>the</strong> microbenchmark facilities <strong>the</strong>mselves were scalable without<br />
considering HFS. Due to <strong>the</strong> rapidly changing development environment <strong>and</strong> <strong>the</strong> experimental nature <strong>of</strong> K42,<br />
<strong>the</strong> performance <strong>and</strong> scalability <strong>of</strong> K42 needs to be frequently verified. The configuration for this experiment<br />
was <strong>the</strong> same as Section 5.2 where <strong>the</strong> st<strong>and</strong>ard memory model was used. The code path was identical<br />
except that calls to <strong>the</strong> core <strong>of</strong> HFS were short-circuited. Calls reached as far as <strong>the</strong> HFS interface layer but<br />
no fur<strong>the</strong>r. More specifically, calls to <strong>the</strong> HFS core to acquire <strong>and</strong> update meta-data <strong>and</strong> perform <strong>the</strong> read<br />
operation were excluded. The results are shown in Figure 5.8 3 . A magnification <strong>of</strong> <strong>the</strong> results is shown in<br />
Figure 5.9. As expected, <strong>the</strong> results showed ideal scalability, indicating that K42 <strong>and</strong> <strong>the</strong> microbenchmark<br />
mechanisms were indeed scalable, <strong>and</strong> were a negligible portion <strong>of</strong> <strong>the</strong> overhead.<br />
3 Error bars were removed from <strong>the</strong> unoptimized 12 processor configuration.











