

Performance Analysis and Optimization of the Hurricane File System ...
Performance Analysis and Optimization of the Hurricane File System ...
Performance Analysis and Optimization of the Hurricane File System ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
CHAPTER 6. MICROBENCHMARKS – OTHER FUNDAMENTAL OPERATIONS 57<br />
avg # cycles per processor<br />
4e+09<br />
3e+09<br />
2e+09<br />
1e+09<br />
0e+00<br />
2 4 6 8 10 12<br />
# processors<br />
Unoptimized 200 pool<br />
Optimized<br />
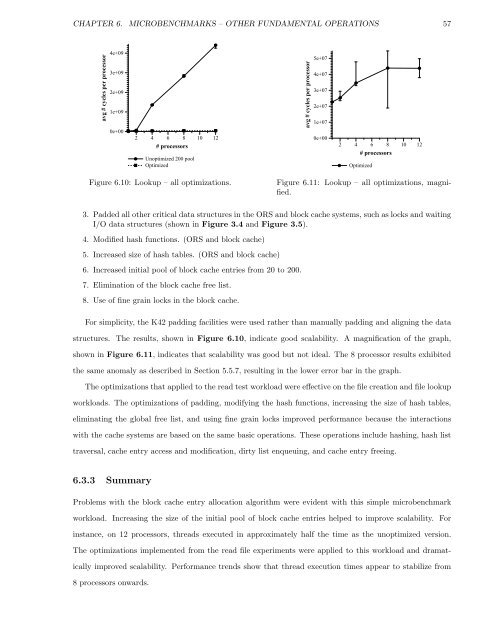
Figure 6.10: Lookup – all optimizations.<br />
avg # cycles per processor<br />
5e+07<br />
4e+07<br />
3e+07<br />
2e+07<br />
1e+07<br />
0e+00<br />
2 4 6 8 10 12<br />
# processors<br />
Optimized<br />
Figure 6.11: Lookup – all optimizations, magnified.<br />
3. Padded all o<strong>the</strong>r critical data structures in <strong>the</strong> ORS <strong>and</strong> block cache systems, such as locks <strong>and</strong> waiting<br />
I/O data structures (shown in Figure 3.4 <strong>and</strong> Figure 3.5).<br />
4. Modified hash functions. (ORS <strong>and</strong> block cache)<br />
5. Increased size <strong>of</strong> hash tables. (ORS <strong>and</strong> block cache)<br />
6. Increased initial pool <strong>of</strong> block cache entries from 20 to 200.<br />
7. Elimination <strong>of</strong> <strong>the</strong> block cache free list.<br />
8. Use <strong>of</strong> fine grain locks in <strong>the</strong> block cache.<br />
For simplicity, <strong>the</strong> K42 padding facilities were used ra<strong>the</strong>r than manually padding <strong>and</strong> aligning <strong>the</strong> data<br />
structures. The results, shown in Figure 6.10, indicate good scalability. A magnification <strong>of</strong> <strong>the</strong> graph,<br />
shown in Figure 6.11, indicates that scalability was good but not ideal. The 8 processor results exhibited<br />
<strong>the</strong> same anomaly as described in Section 5.5.7, resulting in <strong>the</strong> lower error bar in <strong>the</strong> graph.<br />
The optimizations that applied to <strong>the</strong> read test workload were effective on <strong>the</strong> file creation <strong>and</strong> file lookup<br />
workloads. The optimizations <strong>of</strong> padding, modifying <strong>the</strong> hash functions, increasing <strong>the</strong> size <strong>of</strong> hash tables,<br />
eliminating <strong>the</strong> global free list, <strong>and</strong> using fine grain locks improved performance because <strong>the</strong> interactions<br />
with <strong>the</strong> cache systems are based on <strong>the</strong> same basic operations. These operations include hashing, hash list<br />
traversal, cache entry access <strong>and</strong> modification, dirty list enqueuing, <strong>and</strong> cache entry freeing.<br />
6.3.3 Summary<br />
Problems with <strong>the</strong> block cache entry allocation algorithm were evident with this simple microbenchmark<br />
workload. Increasing <strong>the</strong> size <strong>of</strong> <strong>the</strong> initial pool <strong>of</strong> block cache entries helped to improve scalability. For<br />
instance, on 12 processors, threads executed in approximately half <strong>the</strong> time as <strong>the</strong> unoptimized version.<br />
The optimizations implemented from <strong>the</strong> read file experiments were applied to this workload <strong>and</strong> dramat-<br />
ically improved scalability. <strong>Performance</strong> trends show that thread execution times appear to stabilize from<br />
8 processors onwards.











