

Performance Analysis and Optimization of the Hurricane File System ...
Performance Analysis and Optimization of the Hurricane File System ...
Performance Analysis and Optimization of the Hurricane File System ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
CHAPTER 7. MACROBENCHMARK 74<br />
avg # cycles per processor<br />
6e+10<br />
4e+10<br />
2e+10<br />
0e+00<br />
2 4 6 8 10 12<br />
# processors<br />
Unoptimized<br />
Optimized<br />
Optimized 2<br />
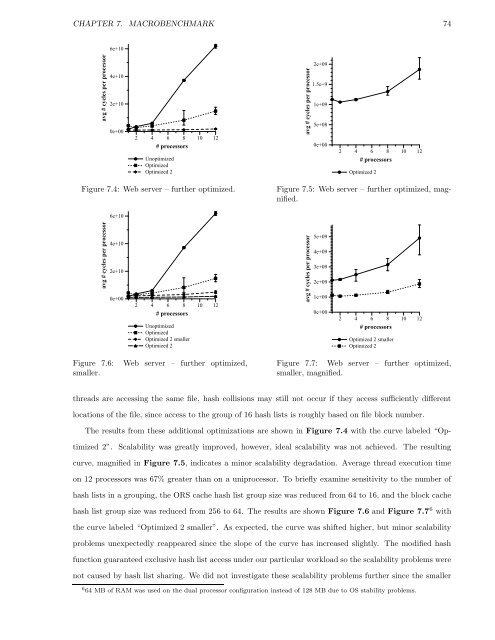
Figure 7.4: Web server – fur<strong>the</strong>r optimized.<br />
avg # cycles per processor<br />
6e+10<br />
4e+10<br />
2e+10<br />
0e+00<br />
2 4 6 8 10 12<br />
# processors<br />
Unoptimized<br />
Optimized<br />
Optimized 2 smaller<br />
Optimized 2<br />
Figure 7.6: Web server – fur<strong>the</strong>r optimized,<br />
smaller.<br />
avg # cycles per processor<br />
2e+09<br />
1.5e+9<br />
1e+09<br />
5e+08<br />
0e+00<br />
2 4 6 8 10 12<br />
# processors<br />
Optimized 2<br />
Figure 7.5: Web server – fur<strong>the</strong>r optimized, magnified.<br />
avg # cycles per processor<br />
5e+09<br />
4e+09<br />
3e+09<br />
2e+09<br />
1e+09<br />
0e+00<br />
2 4 6 8 10 12<br />
# processors<br />
Optimized 2 smaller<br />
Optimized 2<br />
Figure 7.7: Web server – fur<strong>the</strong>r optimized,<br />
smaller, magnified.<br />
threads are accessing <strong>the</strong> same file, hash collisions may still not occur if <strong>the</strong>y access sufficiently different<br />
locations <strong>of</strong> <strong>the</strong> file, since access to <strong>the</strong> group <strong>of</strong> 16 hash lists is roughly based on file block number.<br />
The results from <strong>the</strong>se additional optimizations are shown in Figure 7.4 with <strong>the</strong> curve labeled “Op-<br />
timized 2”. Scalability was greatly improved, however, ideal scalability was not achieved. The resulting<br />
curve, magnified in Figure 7.5, indicates a minor scalability degradation. Average thread execution time<br />
on 12 processors was 67% greater than on a uniprocessor. To briefly examine sensitivity to <strong>the</strong> number <strong>of</strong><br />
hash lists in a grouping, <strong>the</strong> ORS cache hash list group size was reduced from 64 to 16, <strong>and</strong> <strong>the</strong> block cache<br />
hash list group size was reduced from 256 to 64. The results are shown Figure 7.6 <strong>and</strong> Figure 7.7 6 with<br />
<strong>the</strong> curve labeled “Optimized 2 smaller”. As expected, <strong>the</strong> curve was shifted higher, but minor scalability<br />
problems unexpectedly reappeared since <strong>the</strong> slope <strong>of</strong> <strong>the</strong> curve has increased slightly. The modified hash<br />
function guaranteed exclusive hash list access under our particular workload so <strong>the</strong> scalability problems were<br />
not caused by hash list sharing. We did not investigate <strong>the</strong>se scalability problems fur<strong>the</strong>r since <strong>the</strong> smaller<br />
6 64 MB <strong>of</strong> RAM was used on <strong>the</strong> dual processor configuration instead <strong>of</strong> 128 MB due to OS stability problems.











