

improving music mood classification using lyrics, audio and social tags
improving music mood classification using lyrics, audio and social tags
improving music mood classification using lyrics, audio and social tags

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
then compared to the feature concatenation hybrid system, as well as the systems based on lyriconly<br />
<strong>and</strong> <strong>audio</strong>-only.<br />
7.2.2 Best Hybrid Method<br />
Since the best lyric feature set was Content + FW + GI + ANEW + Affect-lex + TextStyle<br />
(denoted as “BEST” thereafter), <strong>and</strong> the second best feature set, ANEW + TextStyle was very<br />
interesting; each of the two lyric feature sets was combined with the <strong>audio</strong>-based system<br />
described in Section 7.1. For the late fusion method, an experiment was conducted to determine<br />
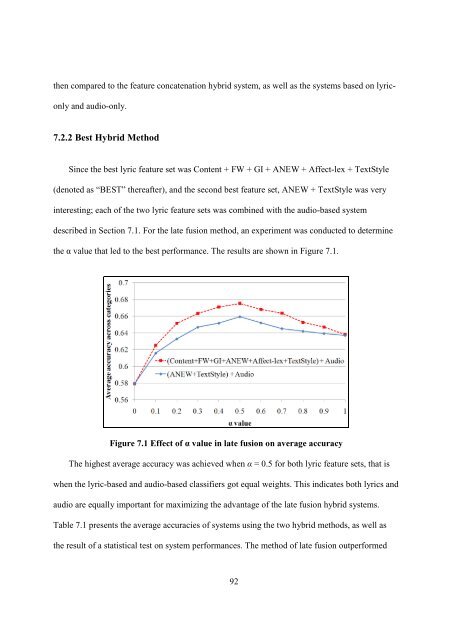
the α value that led to the best performance. The results are shown in Figure 7.1.<br />
Figure 7.1 Effect of α value in late fusion on average accuracy<br />
The highest average accuracy was achieved when α = 0.5 for both lyric feature sets, that is<br />
when the lyric-based <strong>and</strong> <strong>audio</strong>-based classifiers got equal weights. This indicates both <strong>lyrics</strong> <strong>and</strong><br />
<strong>audio</strong> are equally important for maximizing the advantage of the late fusion hybrid systems.<br />
Table 7.1 presents the average accuracies of systems <strong>using</strong> the two hybrid methods, as well as<br />
the result of a statistical test on system performances. The method of late fusion outperformed<br />
92













