

improving music mood classification using lyrics, audio and social tags
improving music mood classification using lyrics, audio and social tags
improving music mood classification using lyrics, audio and social tags

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
lengths extracted from the song tracks. Almost all of the <strong>audio</strong> clips were extracted from the<br />
middle of the songs, as the middle part is deemed as most representative for the whole song<br />
(Silla, Kaestner, & Koerich, 2007). There were very few songs whose middle parts contain<br />
significant amounts of silence, in which case the <strong>audio</strong> clips were extracted from the beginning<br />
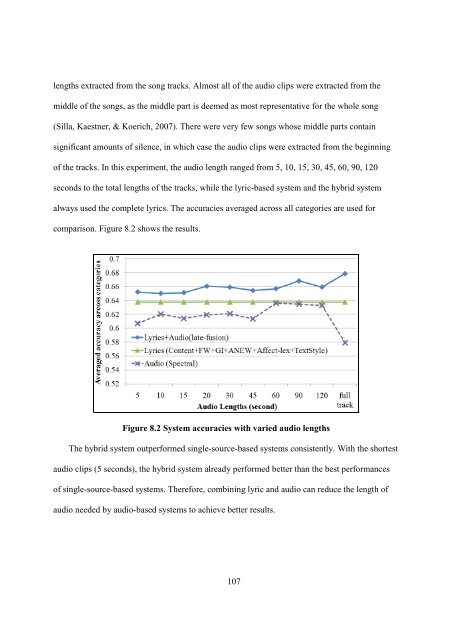
of the tracks. In this experiment, the <strong>audio</strong> length ranged from 5, 10, 15, 30, 45, 60, 90, 120<br />
seconds to the total lengths of the tracks, while the lyric-based system <strong>and</strong> the hybrid system<br />
always used the complete <strong>lyrics</strong>. The accuracies averaged across all categories are used for<br />
comparison. Figure 8.2 shows the results.<br />
Figure 8.2 System accuracies with varied <strong>audio</strong> lengths<br />
The hybrid system outperformed single-source-based systems consistently. With the shortest<br />
<strong>audio</strong> clips (5 seconds), the hybrid system already performed better than the best performances<br />
of single-source-based systems. Therefore, combining lyric <strong>and</strong> <strong>audio</strong> can reduce the length of<br />
<strong>audio</strong> needed by <strong>audio</strong>-based systems to achieve better results.<br />
107













