

improving music mood classification using lyrics, audio and social tags
improving music mood classification using lyrics, audio and social tags
improving music mood classification using lyrics, audio and social tags

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
conclusively made. Therefore, the answer to research question 3 would be: the lyric-based<br />
system outperformed the <strong>audio</strong>-based system in terms of average accuracy across all 18 <strong>mood</strong><br />
categories in the experiment dataset, but their difference was just shy of being accepted as<br />
statistically significant.<br />
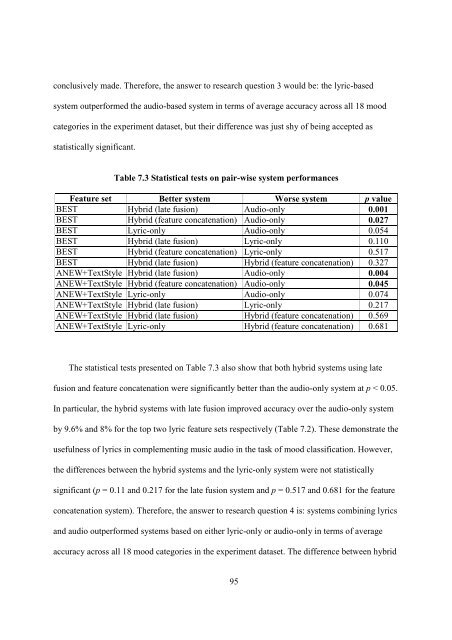
Table 7.3 Statistical tests on pair-wise system performances<br />
Feature set Better system Worse system p value<br />
BEST Hybrid (late fusion) Audio-only 0.001<br />
BEST Hybrid (feature concatenation) Audio-only 0.027<br />
BEST Lyric-only Audio-only 0.054<br />
BEST Hybrid (late fusion) Lyric-only 0.110<br />
BEST Hybrid (feature concatenation) Lyric-only 0.517<br />
BEST Hybrid (late fusion) Hybrid (feature concatenation) 0.327<br />
ANEW+TextStyle Hybrid (late fusion) Audio-only 0.004<br />
ANEW+TextStyle Hybrid (feature concatenation) Audio-only 0.045<br />
ANEW+TextStyle Lyric-only Audio-only 0.074<br />
ANEW+TextStyle Hybrid (late fusion) Lyric-only 0.217<br />
ANEW+TextStyle Hybrid (late fusion) Hybrid (feature concatenation) 0.569<br />
ANEW+TextStyle Lyric-only Hybrid (feature concatenation) 0.681<br />
The statistical tests presented on Table 7.3 also show that both hybrid systems <strong>using</strong> late<br />
fusion <strong>and</strong> feature concatenation were significantly better than the <strong>audio</strong>-only system at p < 0.05.<br />
In particular, the hybrid systems with late fusion improved accuracy over the <strong>audio</strong>-only system<br />
by 9.6% <strong>and</strong> 8% for the top two lyric feature sets respectively (Table 7.2). These demonstrate the<br />
usefulness of <strong>lyrics</strong> in complementing <strong>music</strong> <strong>audio</strong> in the task of <strong>mood</strong> <strong>classification</strong>. However,<br />
the differences between the hybrid systems <strong>and</strong> the lyric-only system were not statistically<br />
significant (p = 0.11 <strong>and</strong> 0.217 for the late fusion system <strong>and</strong> p = 0.517 <strong>and</strong> 0.681 for the feature<br />
concatenation system). Therefore, the answer to research question 4 is: systems combining <strong>lyrics</strong><br />
<strong>and</strong> <strong>audio</strong> outperformed systems based on either lyric-only or <strong>audio</strong>-only in terms of average<br />
accuracy across all 18 <strong>mood</strong> categories in the experiment dataset. The difference between hybrid<br />
95













