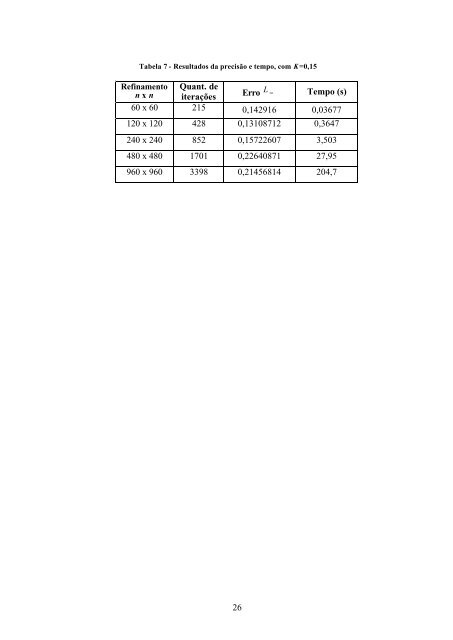
Tabela 7 - Resultados da precisão e tempo, com K=0,15 Refinamento n x n Quant. de iterações Erro L ∞ Tempo (s) 60 x 60 215 0,142916 0,03677 120 x 120 428 0,13108712 0,3647 240 x 240 852 0,15722607 3,503 480 x 480 1701 0,22640871 27,95 960 x 960 3398 0,21456814 204,7 26
CAPÍTULO 3 APLICAÇÕES PARALELAS APLICAÇÕES PARALELAS Uma aplicação paralela tem por objetivo diminuir o tempo de execução de um trabalho pela sua divisão em vários pedaços ou unidades de processamento, chamadas de tarefas. Estas são executadas em vários processadores, tirando proveito da maior capacidade de processamento e da maior quantidade de memória disponível. Um ambiente paralelo pode ser formado por um supercomputador ou por várias estações de trabalho ou PCs, que compõem um “cluster”. Uma das vantagens do “cluster” é a possibilidade de alocar vários processadores a um custo muito menor que o de um supercomputador. A ligação de vários “clusters” dispersos geograficamente é chamada de “grid”. A desvantagem é que a comunicação entre os processadores é dependente da latência da rede, sendo bem mais lenta que no caso de um supercomputador, cujos processadores estão ligados a um barramento de dados. Há uma tendência em chamar de processamento distribuído o ambiente formado por várias máquinas independentes ligadas em rede, não necessariamente ocupando o mesmo local físico. Quando o ambiente é composto de um supercomputador paralelo, o processamento é chamado de processamento paralelo. O tempo de execução é reduzido pela distribuição da carga pelos diversos processadores disponíveis. Idealmente, o tempo de execução de um código paralelo é proporcional a 1/N, onde N é a quantidade de processadores. No entanto, as comunicações e o desbalanceamento da carga aumentam o tempo de processamento. Esse aumento estabelece uma perda de eficiência. Talvez a maior diferença para o programador em relação à aplicação seqüencial é a possibilidade de perda do determinismo. Isto é, uma aplicação paralela pode nem sempre se comportar de modo determinístico. O comportamento da rede pode alterar a ordem de obtenção de recursos pelos processadores, e condições de “deadlock” podem ocorrer, alterando o comportamento do programa paralelo sem que o código tenha sido alterado (o “deadlock” ocorre com um conjunto de processos e recursos não-preemptíveis, onde um ou mais processos desse conjunto está aguardando a liberação de um recurso por um outro processo que, por sua vez, aguarda a liberação de outro recurso alocado ou dependente do primeiro processo). Isto é, para a mesma entrada, com mesmo programa e mesmos dados, a mesma saída não é garantidamente obtida, o que caracteriza um comportamento probabilístico. Por isso, o programador precisa tomar cuidados para garantir que este tipo de comportamento não ocorra. 27
- Page 1 and 2: Universidade Federal Fluminense MAU
- Page 3 and 4: PARALELIZAÇÃO DA RESOLUÇÃO DE E
- Page 5 and 6: Resumo Este trabalho propõe estuda
- Page 7 and 8: 1. Métodos Numéricos 2. Solução
- Page 9 and 10: SUMÁRIO CAPÍTULO 1 INTRODUÇÃO .
- Page 11 and 12: 6.6 - DESEMPENHO DO PARTICIONADOR P
- Page 13 and 14: Figura 41 - Processo de refinamento
- Page 15 and 16: CAPÍTULO 1 INTRODUÇÃO INTRODUÇ
- Page 17 and 18: CAPÍTULO 2 EQUAÇÕES DIFERENCIAIS
- Page 19 and 20: onde u é a solução, g é uma fun
- Page 21 and 22: aceitável em todo o domínio. Téc
- Page 23 and 24: 2.5 - MÉTRICAS A seguir estão def
- Page 25 and 26: Discretização Partindo das expans
- Page 27 and 28: u t i, j ( ) ( ) ( ) ( ) ( ) ( )
- Page 29 and 30: 2.6.1.3.2 - Formulação implícita
- Page 31 and 32: método Hopscotch com processamento
- Page 33 and 34: no quadrado unitário [ ≤ , x ≤
- Page 35 and 36: Com o intuito de pesquisar qual o m
- Page 37 and 38: K (60 x 60) Quant. de iterações T
- Page 39: t = 1,25s 25 t = 1,50s Figura 15 -
- Page 43 and 44: 3.1.3 - Escalabilidade A escalabili
- Page 45 and 46: ) Máquinas MIMD: Essas máquinas e
- Page 47 and 48: Figura 18 - Exemplo de uma “fat-t
- Page 49 and 50: Figura 20 - Exemplo de particioname
- Page 51 and 52: oeste noroeste sudoeste Figura 24 -
- Page 53 and 54: MPI_Buffer_attach: Cria um “buffe
- Page 55 and 56: Eficiência 1,2 1 0,8 0,6 0,4 0,2 0
- Page 57 and 58: As figuras 29 e 30 a seguir apresen
- Page 59 and 60: Tamanho domínio 240 x 240 480 x 48
- Page 61 and 62: CAPÍTULO 4 O REFINAMENTO ADAPTATIV
- Page 63 and 64: efinamento inicial, as regiões pod
- Page 65 and 66: é a seguinte: Figura 38 - Um domí
- Page 67 and 68: Figura 42 - Comunicação entre fra
- Page 69 and 70: do domínio entre os processadores
- Page 71 and 72: elementos, pontos ou linha de matri
- Page 73 and 74: 5.1.5 - Metaheurísticas Uma metahe
- Page 75 and 76: apresentados vários projetos que t
- Page 77 and 78: uscam minimizar o perímetro das pa
- Page 79 and 80: 5.4 - IMPLEMENTAÇÃO DO REFINAMENT
- Page 81 and 82: onde G é o ganho obtido por balanc
- Page 83 and 84: ) É calculado, usando a fórmula (
- Page 85 and 86: Figura 48 - Exemplo de subdivisão
- Page 87 and 88: 6.3 - TRÁFEGO DAS FRANJAS A cada i
- Page 89 and 90: seguir Inicializa montaEstrutura va
- Page 91 and 92:
As referências [7, 56] indicam alg
- Page 93 and 94:
Tabela 12 - Comparação entre os p
- Page 95 and 96:
lim2[a][b][c], ndeForam[a][b][c], q
- Page 97 and 98:
i) Rotina distribui Executa duas fu
- Page 99 and 100:
) Rotina verificaErro Calcula a nor
- Page 101 and 102:
A figura 62 a seguir é um exemplo
- Page 103 and 104:
As figuras 63 e 64 a seguir apresen
- Page 105 and 106:
Índice de desbalanceamento (ID) 0,
- Page 107 and 108:
q Tabela 18 - Ganho para o balancea
- Page 109 and 110:
desenvolvido aqui foi projetado. O
- Page 111 and 112:
Pode ser observado, comparando com
- Page 113 and 114:
Ganho 12 10 8 6 4 2 0 Ganho (Eq. da
- Page 115 and 116:
CAPÍTULO 7 CONCLUSÕES CONCLUSÕES
- Page 117 and 118:
APÊNDICE A Uma breve descrição d
- Page 119 and 120:
metis-4.0> pmetis Graphs/4elt.graph
- Page 121 and 122:
APÊNDICE B Uma breve descrição d
- Page 123 and 124:
Assignment output file: `a' (normal
- Page 125 and 126:
APÊNDICE C Uma breve descrição d
- Page 127 and 128:
APÊNDICE D Ambiente dos Testes Os
- Page 129 and 130:
[13] Brown, D.; Henshaw, W.; Quinla
- Page 131 and 132:
[39] Gustafson, J. L., Reevaluating
- Page 133 and 134:
198-206, hospedado no sítio http:/
- Page 135 and 136:
National Research Institute for Mat