

Cost-Based Optimization of Integration Flows - Datenbanken ...
Cost-Based Optimization of Integration Flows - Datenbanken ...
Cost-Based Optimization of Integration Flows - Datenbanken ...
- No tags were found...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
5.2 Horizontal Queue Partitioning<br />
as the monitored average value selectivities sel(ba 1 ) = 1/3 and sel(ba 2 ) = 1/10. This<br />
results in two possible partitioning schemes with maximum partition numbers <strong>of</strong> |ba 1 , ba 2 | =<br />
3 + 3 · 10 = 33 and |ba 2 , ba 1 | = 10 + 10 · 3 = 40. Thus, we select (ba 1 , ba 2 ) as the best<br />
partitioning scheme because sel(ba 1 ) ≥ sel(ba 2 ). For a given message subsequence, this<br />
results in three instead <strong>of</strong> ten plan instances.<br />
Having minimized the total number <strong>of</strong> partitions, we minimized the overhead <strong>of</strong> queue<br />
maintenance and more importantly maximized the number <strong>of</strong> messages per top-level partition,<br />
which reduces the number <strong>of</strong> required plan instances. The result is the optimal<br />
partitioning scheme with regard to relative execution time and thus message throughput.<br />
5.2.3 Plan Rewriting Algorithm<br />
With regard to executing hierarchical message partitions, only slight changes <strong>of</strong> physical<br />
operator implementations are necessary. All other changes are made on logical level when<br />
rewriting a plan P to P ′ during the initial deployment or during periodical re-optimization.<br />
For the purpose <strong>of</strong> plan rewriting, several integration flow meta model extensions are required.<br />
First, the message meta model is extended in such a way that an abstract message<br />
can be either an atomic message or a message partition, where the latter is described by a<br />
partitioning attribute ba i as well as the type and the values <strong>of</strong> this partitioning attribute.<br />
In addition, the message partition can be a node partition, which references child partitions,<br />
or a leaf partition, which references atomic messages. All operators that benefit from<br />
partitioning (e.g., Invoke, Assign, or Switch) are modified accordingly, while all other<br />
operators transparently split the incoming message partition into all atomic messages, are<br />
executed for each message, and then they repartition the messages after execution. Second,<br />
the flow meta model is extended by two additional operators that are described in<br />
Table 5.1. They represent inverse functionalities as shown in Figure 5.8.<br />
<strong>Based</strong> on these two additional operators, the logical plan rewriting is realized with the<br />
so-called split and merge approach. From a macroscopic view, a plan receives the toplevel<br />
partition, dequeued from the partition tree. Then, we can execute all operators that<br />
benefit from the top-level partitioning attribute. Just before an operator that benefits<br />
from a lower-level partition attribute, we need to insert a PSplit operator that splits the<br />
top-level partition into the 1/sel(ba 2 ) subpartitions (worst case) as well as an Iteration<br />
operator (foreach) that iterates over these subpartitions. The sequence <strong>of</strong> operators that<br />
benefit from this granularity are used as iteration body. After this iteration, we insert a<br />
PMerge operator in order to merge the resulting partitions back to the top-level partition if<br />
required (e.g., if a subsequent operator benefit from higher level partitioning attributes).<br />
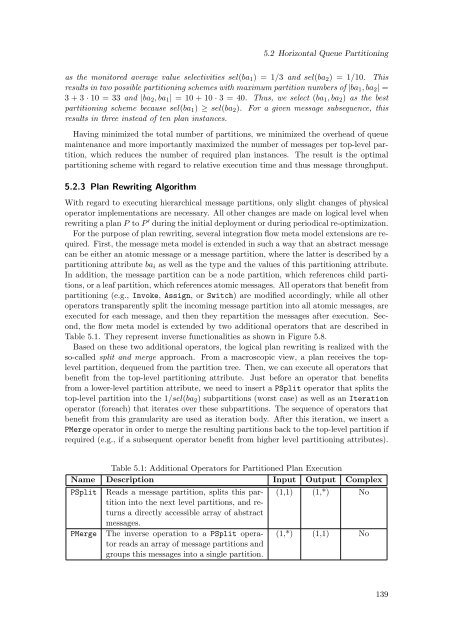
Table 5.1: Additional Operators for Partitioned Plan Execution<br />
Name Description Input Output Complex<br />
PSplit<br />
PMerge<br />
Reads a message partition, splits this partition<br />
into the next level partitions, and returns<br />
a directly accessible array <strong>of</strong> abstract<br />
messages.<br />
The inverse operation to a PSplit operator<br />
reads an array <strong>of</strong> message partitions and<br />
groups this messages into a single partition.<br />
(1,1) (1,*) No<br />
(1,*) (1,1) No<br />
139








