

Cost-Based Optimization of Integration Flows - Datenbanken ...
Cost-Based Optimization of Integration Flows - Datenbanken ...
Cost-Based Optimization of Integration Flows - Datenbanken ...
- No tags were found...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
5.5 Experimental Evaluation<br />
the waiting time was adjusted according to the increased message rate, which led to<br />
throughput improvements such that the optimized plan was able to process much higher<br />
message rates 16 . Due to the lower bound <strong>of</strong> relative execution times, also the optimized<br />
plan cannot cope with the increased message rate after a certain point. However, we<br />
observe a slower degradation <strong>of</strong> the average latency due to more messages per batch,<br />
decreasing relative execution time and thus, increased throughput.<br />
<strong>Optimization</strong> Overhead<br />
In addition to the end-to-end comparison, which already included all optimization overheads,<br />
we now investigate the runtime overhead in more detail. Most importantly, the<br />
partitioned enqueue operation depends on the selectivity <strong>of</strong> partitioning attributes. Therefore,<br />
we analyzed the overhead <strong>of</strong> the (hash) partition tree compared to the commonly used<br />
transient message queue (no partitioning) with and without serialized external behavior.<br />
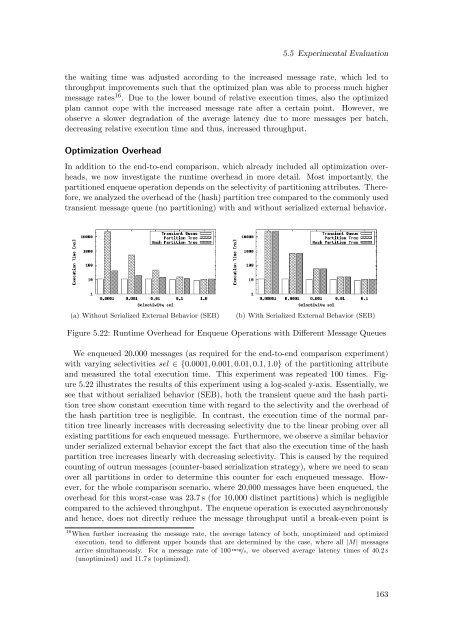
(a) Without Serialized External Behavior (SEB)<br />
(b) With Serialized External Behavior (SEB)<br />
Figure 5.22: Runtime Overhead for Enqueue Operations with Different Message Queues<br />
We enqueued 20,000 messages (as required for the end-to-end comparison experiment)<br />
with varying selectivities sel ∈ {0.0001, 0.001, 0.01, 0.1, 1.0} <strong>of</strong> the partitioning attribute<br />
and measured the total execution time. This experiment was repeated 100 times. Figure<br />
5.22 illustrates the results <strong>of</strong> this experiment using a log-scaled y-axis. Essentially, we<br />
see that without serialized behavior (SEB), both the transient queue and the hash partition<br />
tree show constant execution time with regard to the selectivity and the overhead <strong>of</strong><br />
the hash partition tree is negligible. In contrast, the execution time <strong>of</strong> the normal partition<br />
tree linearly increases with decreasing selectivity due to the linear probing over all<br />
existing partitions for each enqueued message. Furthermore, we observe a similar behavior<br />
under serialized external behavior except the fact that also the execution time <strong>of</strong> the hash<br />
partition tree increases linearly with decreasing selectivity. This is caused by the required<br />
counting <strong>of</strong> outrun messages (counter-based serialization strategy), where we need to scan<br />
over all partitions in order to determine this counter for each enqueued message. However,<br />
for the whole comparison scenario, where 20,000 messages have been enqueued, the<br />
overhead for this worst-case was 23.7 s (for 10,000 distinct partitions) which is negligible<br />
compared to the achieved throughput. The enqueue operation is executed asynchronously<br />
and hence, does not directly reduce the message throughput until a break-even point is<br />
16 When further increasing the message rate, the average latency <strong>of</strong> both, unoptimized and optimized<br />
execution, tend to different upper bounds that are determined by the case, where all |M| messages<br />
arrive simultaneously. For a message rate <strong>of</strong> 100 msg /s, we observed average latency times <strong>of</strong> 40.2 s<br />
(unoptimized) and 11.7 s (optimized).<br />
163








