

Cost-Based Optimization of Integration Flows - Datenbanken ...
Cost-Based Optimization of Integration Flows - Datenbanken ...
Cost-Based Optimization of Integration Flows - Datenbanken ...
- No tags were found...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
5 Multi-Flow <strong>Optimization</strong><br />
reached, where the message rate is too high. For example, consider a message rate <strong>of</strong><br />
R = 20 msg /s, this break-even point occurs at ≈ 422,000 distinct partitions in the queue.<br />
Side Effects <strong>of</strong> <strong>Optimization</strong> Techniques<br />
Putting it all together, we conducted an additional experiment in order to evaluate the<br />
influences between MFO, vectorization, and the other cost-based optimization techniques.<br />
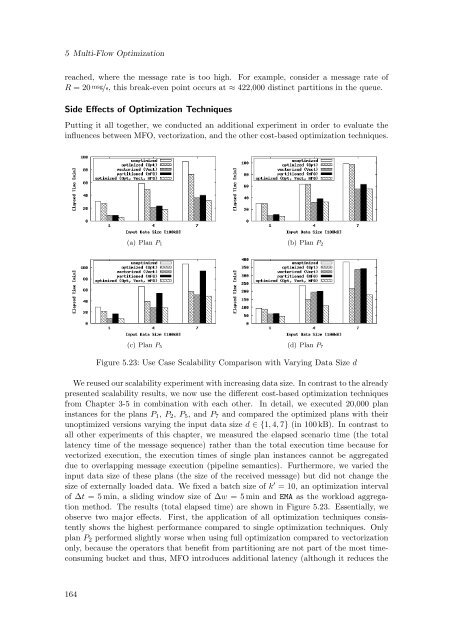
(a) Plan P 1 (b) Plan P 2<br />
(c) Plan P 5 (d) Plan P 7<br />
Figure 5.23: Use Case Scalability Comparison with Varying Data Size d<br />
We reused our scalability experiment with increasing data size. In contrast to the already<br />
presented scalability results, we now use the different cost-based optimization techniques<br />
from Chapter 3-5 in combination with each other. In detail, we executed 20,000 plan<br />
instances for the plans P 1 , P 2 , P 5 , and P 7 and compared the optimized plans with their<br />
unoptimized versions varying the input data size d ∈ {1, 4, 7} (in 100 kB). In contrast to<br />
all other experiments <strong>of</strong> this chapter, we measured the elapsed scenario time (the total<br />
latency time <strong>of</strong> the message sequence) rather than the total execution time because for<br />
vectorized execution, the execution times <strong>of</strong> single plan instances cannot be aggregated<br />
due to overlapping message execution (pipeline semantics). Furthermore, we varied the<br />
input data size <strong>of</strong> these plans (the size <strong>of</strong> the received message) but did not change the<br />
size <strong>of</strong> externally loaded data. We fixed a batch size <strong>of</strong> k ′ = 10, an optimization interval<br />
<strong>of</strong> ∆t = 5 min, a sliding window size <strong>of</strong> ∆w = 5 min and EMA as the workload aggregation<br />
method. The results (total elapsed time) are shown in Figure 5.23. Essentially, we<br />
observe two major effects. First, the application <strong>of</strong> all optimization techniques consistently<br />
shows the highest performance compared to single optimization techniques. Only<br />
plan P 2 performed slightly worse when using full optimization compared to vectorization<br />
only, because the operators that benefit from partitioning are not part <strong>of</strong> the most timeconsuming<br />
bucket and thus, MFO introduces additional latency (although it reduces the<br />
164








