- Page 2 and 3:
ContentsPrefacexviiContributorsI Th
- Page 5 and 6:
viii15 We live in exciting times 15
- Page 7 and 8:
x24.6 Open areas for research . . .
- Page 9 and 10:
xii36 Buried treasures 405Michael A
- Page 11 and 12:
xiv45.3 Multi-phase inference . . .
- Page 14 and 15:
PrefaceStatistics is the science of
- Page 16:
PrefacexixPart V comprises seven ar
- Page 19 and 20:
xxiiNancy FlournoyUniversity of Mis
- Page 22:
Part IThe history of COPSS
- Page 25 and 26:
4 A brief history of COPSSOnchiota
- Page 27 and 28:
6 A brief history of COPSSThe items
- Page 29 and 30:
8 A brief history of COPSSTABLE 1.1
- Page 31 and 32:
10 A brief history of COPSSwomen of
- Page 33 and 34:
12 A brief history of COPSSTABLE 1.
- Page 35 and 36:
14 A brief history of COPSSTABLE 1.
- Page 37 and 38:
16 A brief history of COPSS1.4.3 Ge
- Page 39 and 40:
18 A brief history of COPSSTABLE 1.
- Page 41 and 42:
20 A brief history of COPSSFor more
- Page 44 and 45:
2Reminiscences of the Columbia Univ
- Page 46 and 47:
I. Olkin 25Bechhofer, Allan Birnbau
- Page 48 and 49:
I. Olkin 27Milton Sobel was the tea
- Page 50 and 51:
3AcareerinstatisticsHerman Chernoff
- Page 52 and 53:
H. Chernoff 31given three-day basic
- Page 54 and 55:
H. Chernoff 33Savage tried to defen
- Page 56 and 57:
H. Chernoff 35In working on an arti
- Page 58 and 59:
H. Chernoff 37measure the loss as t
- Page 60 and 61:
H. Chernoff 39ReferencesAlbert, A.E
- Page 62 and 63:
4“. . . how wonderful the field o
- Page 64 and 65:
D.R. Brillinger 43He went on to be
- Page 66 and 67:
D.R. Brillinger 45Tukey wrote many
- Page 68:
D.R. Brillinger 4718. Personal comm
- Page 71 and 72:
50 Unorthodox journey to statistics
- Page 73 and 74:
52 Unorthodox journey to statistics
- Page 75 and 76:
54 Unorthodox journey to statistics
- Page 77 and 78:
56 Unorthodox journey to statistics
- Page 80 and 81:
6Statistics before and after my COP
- Page 82 and 83:
P.J. Bickel 616.3.1 Imperial Colleg
- Page 84 and 85:
P.J. Bickel 63make. This was first
- Page 86 and 87:
P.J. Bickel 65We eventually develop
- Page 88 and 89:
P.J. Bickel 67school interest, biol
- Page 90 and 91:
P.J. Bickel 69ReferencesBean, D., B
- Page 92:
P.J. Bickel 71Meinshausen, N., Bick
- Page 95 and 96:
74 Accidental biostatistics profess
- Page 97 and 98:
76 Accidental biostatistics profess
- Page 99 and 100:
78 Accidental biostatistics profess
- Page 101 and 102:
80 Accidental biostatistics profess
- Page 103 and 104:
82 Accidental biostatistics profess
- Page 105 and 106:
84 Passion for statisticsme is its
- Page 107 and 108:
86 Passion for statisticsTheir Biom
- Page 109 and 110:
88 Passion for statisticsthe first
- Page 111 and 112:
90 Passion for statisticsIn my expe
- Page 113 and 114:
92 Passion for statistics8.5 Job an
- Page 115 and 116:
94 Passion for statisticsperiod. An
- Page 117 and 118:
96 Passion for statisticsNeyman, J.
- Page 119 and 120:
98 Reflections on a statistical car
- Page 121 and 122:
100 Reflections on a statistical ca
- Page 123 and 124:
102 Reflections on a statistical ca
- Page 125 and 126:
104 Reflections on a statistical ca
- Page 127 and 128:
106 Reflections on a statistical ca
- Page 129 and 130:
108 Reflections on a statistical ca
- Page 131 and 132:
110 Science mixes it up with statis
- Page 133 and 134:
112 Science mixes it up with statis
- Page 135 and 136:
114 Science mixes it up with statis
- Page 138 and 139:
11Lessons from a twisted career pat
- Page 140 and 141:
J.S. Rosenthal 119My math professor
- Page 142 and 143:
J.S. Rosenthal 121contrary, it null
- Page 144 and 145:
J.S. Rosenthal 123of statistical re
- Page 146 and 147:
J.S. Rosenthal 125be open to whatev
- Page 148:
J.S. Rosenthal 12711.4 Final though
- Page 151 and 152:
130 Promoting equityand fellowship
- Page 153 and 154:
132 Promoting equityevaluate such e
- Page 155 and 156:
134 Promoting equityfor equity. But
- Page 157 and 158:
136 Promoting equityAssistant Secre
- Page 160:
Part IIIPerspectives on the fieldan
- Page 163 and 164:
142 Statistics in service to the na
- Page 165 and 166:
144 Statistics in service to the na
- Page 167 and 168:
146 Statistics in service to the na
- Page 169 and 170:
148 Statistics in service to the na
- Page 171 and 172:
150 Statistics in service to the na
- Page 173 and 174:
152 Statistics in service to the na
- Page 175 and 176:
154 Where are the majors? ArtBachel
- Page 177 and 178:
156 Where are the majors?References
- Page 179 and 180:
158 Exciting timesCritically, Efron
- Page 181 and 182:
160 Exciting timesIn general I find
- Page 183 and 184:
162 Exciting timesI entered the Uni
- Page 185 and 186:
164 Exciting times15.3.3 Joining th
- Page 187 and 188:
166 Exciting timesvariability of a
- Page 189 and 190:
168 Exciting timesHabemma, J.D.F.,
- Page 192 and 193:
16The bright future of applied stat
- Page 194 and 195:
R.A. Irizarry 173FIGURE 16.1Illustr
- Page 196 and 197:
R.A. Irizarry 17516.4 The bright fu
- Page 198 and 199:
17The road travelled: From statisti
- Page 200 and 201:
N. Chatterjee 179the Kaplan-Meyer e
- Page 202 and 203:
N. Chatterjee 18117.4 Genome-wide a
- Page 204 and 205:
N. Chatterjee 183by any means. I ju
- Page 206 and 207:
N. Chatterjee 185right information
- Page 208:
N. Chatterjee 187The risk of cancer
- Page 211 and 212:
190 Journey into genetics and genom
- Page 213 and 214:
192 Journey into genetics and genom
- Page 215 and 216:
194 Journey into genetics and genom
- Page 217 and 218:
196 Journey into genetics and genom
- Page 219 and 220:
198 Journey into genetics and genom
- Page 221 and 222:
200 Journey into genetics and genom
- Page 224 and 225:
19Reflections on women in statistic
- Page 226 and 227:
M.E. Thompson 205Pearson in England
- Page 228 and 229:
M.E. Thompson 207TABLE 19.1The 14 C
- Page 230 and 231:
M.E. Thompson 209time series, the s
- Page 232 and 233:
M.E. Thompson 211the founding Chair
- Page 234 and 235:
M.E. Thompson 21319.7 The current s
- Page 236:
M.E. Thompson 215Yarmie, A. (2003).
- Page 239 and 240:
218 “The whole women thing”seem
- Page 241 and 242:
220 “The whole women thing”of t
- Page 243 and 244:
222 “The whole women thing”on a
- Page 245 and 246:
224 “The whole women thing”20.5
- Page 247 and 248:
226 “The whole women thing”Ifin
- Page 249 and 250:
228 “The whole women thing”Lond
- Page 251 and 252:
230 Reflections on diversityas a st
- Page 253 and 254:
232 Reflections on diversityall of
- Page 255 and 256:
234 Reflections on diversityforce m
- Page 258 and 259:
22Why does statistics have two theo
- Page 260 and 261:
D.A.S. Fraser 23922.2 65 years and
- Page 262 and 263:
D.A.S. Fraser 241function is taken
- Page 264 and 265:
D.A.S. Fraser 24322.4 Inference for
- Page 266 and 267:
D.A.S. Fraser 245that record the ef
- Page 268 and 269:
D.A.S. Fraser 247variable that give
- Page 270 and 271:
D.A.S. Fraser 249simple scalar case
- Page 272 and 273:
D.A.S. Fraser 251DiCiccio, T.J. and
- Page 274 and 275:
23Conditioning is the issueJames O.
- Page 276 and 277:
J.O. Berger 255Pedagogical example:
- Page 278 and 279:
J.O. Berger 257The SRP does not say
- Page 280 and 281:
J.O. Berger 25923.5 Conditional fre
- Page 282 and 283:
J.O. Berger 261conditional error pr
- Page 284 and 285:
J.O. Berger 263others). If x is the
- Page 286 and 287:
J.O. Berger 265How does a frequenti
- Page 288 and 289:
24Statistical inference from aDemps
- Page 290 and 291:
A.P. Dempster 269tion is simply une
- Page 292 and 293:
A.P. Dempster 271As the world of st
- Page 294 and 295:
A.P. Dempster 273when the X i are a
- Page 296 and 297:
A.P. Dempster 27524.5 Nonparametric
- Page 298 and 299:
A.P. Dempster 277can easily happen
- Page 300 and 301:
A.P. Dempster 279ReferencesBorel,
- Page 302 and 303:
25Nonparametric BayesDavid B. Dunso
- Page 304 and 305:
D.B. Dunson 283troduced, providing
- Page 306 and 307:
D.B. Dunson 285els in spatial stati
- Page 308 and 309:
D.B. Dunson 287methods as also prov
- Page 310 and 311:
D.B. Dunson 289ing background, and
- Page 312:
D.B. Dunson 291Murray, J.S., Dunson
- Page 315 and 316:
294 Choosing default methodsimagine
- Page 317 and 318:
296 Choosing default methods(a) mat
- Page 319 and 320:
298 Choosing default methodspartial
- Page 321 and 322:
300 Choosing default methodsdirecti
- Page 324 and 325:
27Serial correlation and Durbin-Wat
- Page 326 and 327:
T.W. Anderson 305The characteristic
- Page 328 and 329:
T.W. Anderson 307Consider the seria
- Page 330 and 331:
28Anon-asymptoticwalkinprobabilitya
- Page 332 and 333:
P. Massart 311(at least for discret
- Page 334 and 335:
P. Massart 31328.2.2 Non-asymptopia
- Page 336 and 337:
P. Massart 315where P = sµ. In oth
- Page 338 and 339:
P. Massart 317Hence by Talagrand’
- Page 340 and 341:
P. Massart 319ReferencesAkaike, H.
- Page 342:
P. Massart 321Talagrand, M. (1995).
- Page 345 and 346:
324 The present’s futuredata. In
- Page 347 and 348:
326 The present’s futureTABLE 29.
- Page 349 and 350:
328 The present’s future124356981
- Page 351 and 352:
330 The present’s futuremethod, t
- Page 353 and 354:
332 The present’s futureFIGURE 29
- Page 355 and 356:
334 The present’s futureIchino, M
- Page 357 and 358:
336 Lessons in biostatistics30.2 It
- Page 359 and 360:
338 Lessons in biostatisticsprognos
- Page 361 and 362:
340 Lessons in biostatisticstime fo
- Page 363 and 364:
342 Lessons in biostatisticsmeaning
- Page 365 and 366:
344 Lessons in biostatistics75% to
- Page 367 and 368: 346 Lessons in biostatisticshistolo
- Page 370 and 371: 31AvignetteofdiscoveryNancy Flourno
- Page 372 and 373: N. Flournoy 351FIGURE 31.1Incidence
- Page 374 and 375: N. Flournoy 353FIGURE 31.3Mean resp
- Page 376 and 377: N. Flournoy 355FIGURE 31.4Kaplan-Me
- Page 378 and 379: N. Flournoy 357As the study proceed
- Page 380 and 381: 32Statistics and public health rese
- Page 382 and 383: R.L. Prentice 36132.2 Public health
- Page 384 and 385: R.L. Prentice 363from urinary excre
- Page 386 and 387: R.L. Prentice 36532.5 Clinical tria
- Page 388: R.L. Prentice 367Kaplan, E.L. and M
- Page 391 and 392: 370 Statistics in a new erative eff
- Page 393 and 394: 372 Statistics in a new eraular com
- Page 395 and 396: 374 Statistics in a new erajoint de
- Page 397 and 398: 376 Statistics in a new eraof the n
- Page 399 and 400: 378 Statistics in a new eraLai, T.L
- Page 402 and 403: 34Meta-analyses: Heterogeneity can
- Page 404 and 405: N.M. Laird 383into the sum of a “
- Page 406 and 407: N.M. Laird 385are “approximately
- Page 408 and 409: N.M. Laird 387included in the major
- Page 410: N.M. Laird 389Yusuf, S., Peto, R.,
- Page 413 and 414: 392 Good health: Statistical challe
- Page 415 and 416: 394 Good health: Statistical challe
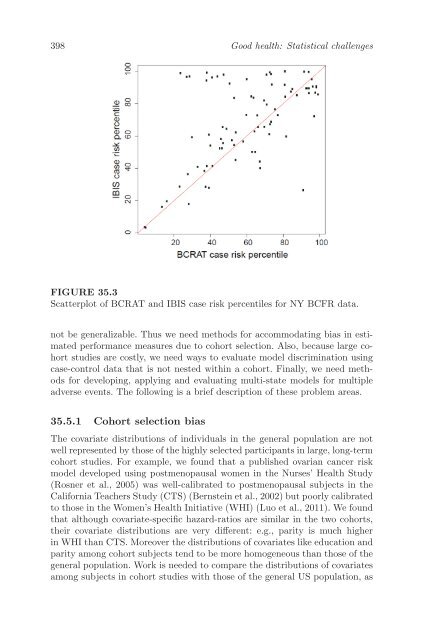
- Page 417: 396 Good health: Statistical challe
- Page 421 and 422: 400 Good health: Statistical challe
- Page 423 and 424: 402 Good health: Statistical challe
- Page 425 and 426: 404 Good health: Statistical challe
- Page 427 and 428: 406 Buried treasuresmeasurement tec
- Page 429 and 430: 408 Buried treasuresIn a most rewar
- Page 431 and 432: 410 Buried treasureslems different
- Page 434 and 435: 37Survey sampling: Past controversi
- Page 436 and 437: R.J. Little 41537.2 Probability or
- Page 438 and 439: R.J. Little 417for the “design-ba
- Page 440 and 441: R.J. Little 419estimate of variance
- Page 442 and 443: R.J. Little 421Example 2 continued
- Page 444 and 445: R.J. Little 42337.3.4 The design-mo
- Page 446 and 447: R.J. Little 42537.5 ConclusionsI am
- Page 448 and 449: R.J. Little 427Isaki, C.T. and Full
- Page 450 and 451: 38Environmental informatics: Uncert
- Page 452 and 453: N. Cressie 431and conquer” strate
- Page 454 and 455: N. Cressie 433In the last 20 years,
- Page 456 and 457: N. Cressie 435Once the satellite ha
- Page 458 and 459: N. Cressie 437FIGURE 38.1Locations
- Page 460 and 461: N. Cressie 439regional and seasonal
- Page 462 and 463: N. Cressie 441ciated with the spati
- Page 464 and 465: N. Cressie 443is the set of all pix
- Page 466 and 467: N. Cressie 445challenge is to devel
- Page 468 and 469:
N. Cressie 447Gourdji, S.M., Muelle
- Page 470:
N. Cressie 449Wikle, C.K., Milliff,
- Page 473 and 474:
452 Statistical geneticsTABLE 39.1T
- Page 475 and 476:
454 Statistical geneticsStewart, 19
- Page 477 and 478:
456 Statistical geneticslocidata
- Page 479 and 480:
458 Statistical geneticssufficientl
- Page 481 and 482:
460 Statistical geneticsBrown, M.D.
- Page 483 and 484:
462 Statistical geneticsLange, K. a
- Page 485 and 486:
464 Statistical geneticsThompson, E
- Page 487 and 488:
466 Targeted learningods for nonpar
- Page 489 and 490:
468 Targeted learningdenote the obs
- Page 491 and 492:
470 Targeted learningSuch an estima
- Page 493 and 494:
472 Targeted learningliterature pro
- Page 495 and 496:
474 Targeted learninglihood estimat
- Page 497 and 498:
476 Targeted learning40.6 Some spec
- Page 499 and 500:
478 Targeted learningmemory challen
- Page 501 and 502:
480 Targeted learningvan der Laan,
- Page 503 and 504:
482 Ah-ha momentwe have just seen.
- Page 505 and 506:
484 Ah-ha momentthe data is unchang
- Page 507 and 508:
486 Ah-ha momentis well defined and
- Page 509 and 510:
488 Ah-ha momentit was something of
- Page 511 and 512:
490 Ah-ha momentdefines a Euclidean
- Page 513 and 514:
492 Ah-ha momentparticipate in the
- Page 515 and 516:
494 Ah-ha momentLee, Y., Wahba, G.,
- Page 518 and 519:
42In praise of sparsity and convexi
- Page 520 and 521:
R.J. Tibshirani 499TABLE 42.1Asampl
- Page 522 and 523:
R.J. Tibshirani 501CancerEpithelial
- Page 524 and 525:
R.J. Tibshirani 503that the error v
- Page 526:
R.J. Tibshirani 505Tibshirani, R.J.
- Page 529 and 530:
508 Features of Big Dataproblems en
- Page 531 and 532:
510 Features of Big Datalearning st
- Page 533 and 534:
512 Features of Big Data1210(a)p =
- Page 535 and 536:
514 Features of Big Data25002000150
- Page 537 and 538:
516 Features of Big DataAs an illus
- Page 539 and 540:
518 Features of Big Datafor some gi
- Page 541 and 542:
520 Features of Big Data43.7.3 Prop
- Page 543 and 544:
522 Features of Big DataBühlmann,
- Page 546 and 547:
44Rise of the machinesLarry A. Wass
- Page 548 and 549:
L.A. Wasserman 527if an idea requir
- Page 550 and 551:
L.A. Wasserman 529●●●● ●
- Page 552 and 553:
L.A. Wasserman 531●●●●●
- Page 554 and 555:
L.A. Wasserman 533FIGURE 44.4Simula
- Page 556 and 557:
L.A. Wasserman 53544.7 Education an
- Page 558 and 559:
45Atrioofinferenceproblemsthatcould
- Page 560 and 561:
X.-L. Meng 539it is directly rooted
- Page 562 and 563:
X.-L. Meng 541exactly, but this doe
- Page 564 and 565:
X.-L. Meng 543That is, when we do n
- Page 566 and 567:
X.-L. Meng 545(a) For what classes
- Page 568 and 569:
X.-L. Meng 547subsequent analysts c
- Page 570 and 571:
X.-L. Meng 549can prove only that (
- Page 572 and 573:
X.-L. Meng 551In general, “What t
- Page 574 and 575:
X.-L. Meng 553vironmental progress
- Page 576 and 577:
X.-L. Meng 555which will be compare
- Page 578 and 579:
X.-L. Meng 557(a) Given partial kno
- Page 580 and 581:
X.-L. Meng 559AcknowledgementsThe m
- Page 582 and 583:
X.-L. Meng 561Knuth, D. (1997). The
- Page 584:
Part VAdvice for the nextgeneration
- Page 587 and 588:
566 Inspiration, aspiration, ambiti
- Page 589 and 590:
568 Inspiration, aspiration, ambiti
- Page 592 and 593:
47Personal reflections on the COPSS
- Page 594 and 595:
R.J. Carroll 573them is, by definit
- Page 596 and 597:
R.J. Carroll 575(Carroll, 2003). In
- Page 598 and 599:
R.J. Carroll 57747.8 After the Pres
- Page 600:
R.J. Carroll 579Carroll, R.J., Spie
- Page 603 and 604:
582 Publishing without perishingthe
- Page 605 and 606:
584 Publishing without perishingbeg
- Page 607 and 608:
586 Publishing without perishingme,
- Page 609 and 610:
588 Publishing without perishingalr
- Page 611 and 612:
590 Publishing without perishingpor
- Page 614 and 615:
49Converting rejections into positi
- Page 616 and 617:
D.B. Rubin 595This pair of submissi
- Page 618 and 619:
D.B. Rubin 597There are several les
- Page 620 and 621:
D.B. Rubin 599very sound article, w
- Page 622 and 623:
D.B. Rubin 60149.8 ConclusionIhaveb
- Page 624:
D.B. Rubin 603Rubin, D.B. (1972). A
- Page 627 and 628:
606 Importance of mentorstwice as t
- Page 629 and 630:
608 Importance of mentorsexperiment
- Page 631 and 632:
610 Importance of mentorsposition a
- Page 633 and 634:
612 Importance of mentors50.7 The t
- Page 636 and 637:
51Never ask for or give advice, mak
- Page 638 and 639:
T. Speed 617overly generous. Perhap
- Page 640:
T. Speed 619and for finding enjoyme
- Page 643:
622 Thirteen rules3. Waste a lot of