- Page 2 and 3:
A COMPARATIVE LEXICAL STUDY OF QUR'
- Page 4 and 5:
A COMPARATIVE LEXICAL STUDY OF QUR'
- Page 6 and 7:
(The Holy Qwr^ 30:22)
- Page 8 and 9:
CONTENTS Acknowledgements ix Abbrev
- Page 10 and 11:
ACKNOWLEDGEMENTS In the course of t
- Page 12 and 13:
AA ace. act. adj. adv. af. Akk. Amh
- Page 14 and 15:
Lex. Syr Brockelmann, Lexicon Syria
- Page 16 and 17:
INTRODUCTION Aim and scope of this
- Page 18 and 19:
INTRODUCTION 6 then discussed from
- Page 20 and 21:
Qur'anic Arabic (QA) INTRODUCTION 5
- Page 22 and 23:
INTRODUCTION 7 etc., a lexical item
- Page 24 and 25:
INTRODUCTION y Jastrow, A Dictionar
- Page 26 and 27:
INTRODUCTION 11
- Page 28 and 29:
INTRODUCTION 13 It should be noted
- Page 30 and 31:
INTRODUCTION 15 Moreover, Semitic r
- Page 32 and 33:
CHAPTER ONE PAST LEXICAL STUDIES 1.
- Page 34 and 35:
PAST LEXICAL STUDIES 19 1.2 Jewish
- Page 36 and 37:
PAST LEXICAL STUDIES 21 brought for
- Page 38 and 39:
PAST LEXICAL STUDIES 23 did not hes
- Page 40 and 41:
PAST LEXICAL STUDIES 25 when applyi
- Page 42 and 43:
PAST LEXICAL STUDIES 27 Reference h
- Page 44 and 45:
CHAPTER TWO THE QUR'ANIC TEXT 2.1 '
- Page 46 and 47:
THE QUR'ANIC TEXT 31 II had overcom
- Page 48 and 49:
THE QUR'ANIC TEXT 33 and Palmyra th
- Page 50 and 51:
THE QUR'ANIC TEXT 35 itance, made s
- Page 52 and 53:
THE QUR'ANIC TEXT 37 advent of Isla
- Page 54 and 55:
THE QURANIC TEXT 39 geneity in Arab
- Page 56 and 57:
THE QUR'ANIC TEXT 41 the possibilit
- Page 58 and 59:
THE QUR'ANIC TEXT 43 nessed regular
- Page 60 and 61:
THE QUR'ANIC TEXT 45 Among Western
- Page 62 and 63:
THE QUR'ANIC TEXT 47 scholars adopt
- Page 64 and 65:
THE QUR'ANIC TEXT 49 vocabulary. In
- Page 66 and 67:
THE QUR'ANIC TEXT 51 This is due to
- Page 68 and 69:
THE QUR'ANIC TEXT 53 in the Qur'dn
- Page 70 and 71:
THE QJJR'ANIC TEXT 55 unequivocally
- Page 72 and 73:
THE QJJR'ANIC TEXT 57 semantics of
- Page 74 and 75:
THE QUR'ANIC TEXT 59 around 35 loan
- Page 76 and 77:
THE QUR'ANIC TEXT 61 sible. This do
- Page 78 and 79:
THE QUR'ANIC TEXT 63 lives of milli
- Page 80 and 81:
THE LEXICAL CORPUS 65 the lexical c
- Page 82 and 83:
Arab. 'a* interrog. part. 'BD 'abad
- Page 84 and 85:
3 TL *atl 'tamarisks' 3 TM 3 itm 'a
- Page 86 and 87:
Ph. Ph. Ug. Ug. Akk. Akk. idu 'hire
- Page 88 and 89:
Aram. "sur BA 'band, bond'; OA 3 sr
- Page 90 and 91:
Aram. Aram. Heb. Heb. Ph. Ph. Ug. U
- Page 92 and 93:
'LH 'ilah* 'a deity, God' 3 LW 'aid
- Page 94 and 95:
'ML } aml 'hope' 'MM J umm 'a mothe
- Page 96 and 97:
J NS 'ins* 'mankind, human beings,
- Page 98 and 99:
Arab. 3 au> 'or, either, whether, u
- Page 100 and 101:
Arab. 'iy 'y ea s verily' 5 YD 'ayy
- Page 102 and 103:
Arab. bi- 'in, by, at, with, to, in
- Page 104 and 105:
Aram. Aram. b'has 'to stir; search,
- Page 106 and 107:
Syr. Syr. badwaya 'nomad' Aram. Ara
- Page 108 and 109:
BRS 'abras 'leprous' BRQ barq 'ligh
- Page 110 and 111:
BSR basar* 'man, men, human beings'
- Page 112 and 113:
B C TR batara 'to scatter abroad; t
- Page 114 and 115:
Ph. Ph. bqr 'cattle' Ug. Ug. bqr 'r
- Page 116 and 117:
Syr. b'la c 'to swallow up, devour'
- Page 118 and 119:
BHL 'ibtahala 'to invoke (the wrath
- Page 120 and 121:
Aram. byn Sf. 'between'; beyney 'be
- Page 122 and 123:
Aram. Aram. Heb. Heb. Ph. Ph. Ug. U
- Page 124 and 125:
TMM tamma 'to be entire, complete,
- Page 126 and 127:
Heb. Heb. Ph. Ph. Ug. Ug. Akk. Akk.
- Page 128 and 129:
Aram. sm Sf. 'there'; tamma BA 'the
- Page 130 and 131:
TYB tayyibat 'women who left their
- Page 132 and 133:
GBH gibah* 'a forehead' GBY gaba (d
- Page 134 and 135:
Syr. guda 'a hedge, mound' Syr. Ara
- Page 136 and 137:
GRR garra 'to dra\v, drag' GRZ guru
- Page 138 and 139:
Heb. Heb. Ph. Ph. Ug. Ug. Akk. Akk.
- Page 140 and 141:
Heb. galas 'to sit, sit up; (possib
- Page 142 and 143:
GNB ganb 'side'; ganaba 'to turn as
- Page 144 and 145:
Ug. Ug. Akk. Akk. GWB gdba (w) 'to
- Page 146 and 147:
Aram. gaw BA 'midst' Aram. Heb. gew
- Page 148 and 149:
Syr. Syr. Aram. Aram. Heb. Heb. Ph.
- Page 150 and 151:
Syr. Syr. Aram. Aram. Heb. Heb. Ph.
- Page 152 and 153:
Syr. h e rat 'to dig out, hollow ou
- Page 154 and 155:
Syr. harrep Pa. 'to sharpen'; harpd
- Page 156 and 157:
Ug. Ug. Akk. Akk. HSS 'ahassa 'to p
- Page 158 and 159:
HSY 3 ahsd 'to number, calculate; k
- Page 160 and 161:
HFZ hafiza 'to keep, guard, take ca
- Page 162 and 163:
HLQM hulqum 'the throat' HLL holla
- Page 164 and 165:
Syr. } hmr 'ruber' (< Arab.) Syr. h
- Page 166 and 167:
HWG haga 'a necessity; thing, matte
- Page 168 and 169:
Aram. Aram. Heb. Heb. Ph. Ph. Ug. U
- Page 170 and 171:
Aram. Aram. hwh Sf. 'a snake'; hewy
- Page 172 and 173:
Syr. bfbat 'to beat down, cudgel, b
- Page 174 and 175:
HRG haraga* ( to go out, forth' HRR
- Page 176 and 177:
Heb. Heb. Ph. Ph. Ug. Ug. Akk. Akk.
- Page 178 and 179:
Heb. hatah 'to miss (a goal or way)
- Page 180 and 181:
Heb. heled 'duration; world' Heb. '
- Page 182 and 183:
HMD hdmid 'extinct; dead' HMR humur
- Page 184 and 185:
HWL hdl 'maternal uncle' HWL hazvzv
- Page 186 and 187:
D'B dab 'a state, custom, manner, w
- Page 188 and 189:
Heb. Heb. Ph. Ph. Ug. Ug. Akk. Akk.
- Page 190 and 191:
Syr. Syr. Aram. Aram. dsy pa. and a
- Page 192 and 193:
Syr. d e la 'to draw water'; dawld
- Page 194 and 195:
DHW } adha 'more grievous' ( } isab
- Page 196 and 197:
Arab, da, 'this; that' (dem. pron.)
- Page 198 and 199:
DRY dara (y) 'to snatch away; scatt
- Page 200 and 201:
DHB dahab 'gold' (husn wa-naddrd) D
- Page 202 and 203:
R'S ra's 'a head' R'F rauf 'compass
- Page 204 and 205:
RTL rattala 'to repeat w. distinct
- Page 206 and 207:
RHB rahuba 'to be ample, spacious'
- Page 208 and 209:
Aram. Aram. Heb. Heb. Ph. Ph. Ug. U
- Page 210 and 211:
Aram. rqy Sf. 'to please'; f'd 'to
- Page 212 and 213:
RFD rifd 'a gift' RFRF rafraf 'a pi
- Page 214 and 215:
Heb. Heb. Ph. Ph. Ug. Ug. Akk. Akk.
- Page 216 and 217:
Heb. romah 'a spear, lance' Heb. Ph
- Page 218 and 219:
Syr. ruwdhd 'ease, solace' Syr. ruh
- Page 220 and 221:
RY C rf 'a high hill' RYN rdna 'to
- Page 222 and 223:
Aram. zuah 'to remove, turn away' A
- Page 224 and 225:
ZLQ 'azlaqa 'to cause to slip or fa
- Page 226 and 227:
Ug. Ug. Akk. Akk. ZHQ zahaqa 'to va
- Page 228 and 229:
sa- sa- an adverb prefixed to the a
- Page 230 and 231:
Aram, /pa' 'to overflow'; af. 'to g
- Page 232 and 233:
SHR sahar* 'the early dawn' SHQ sah
- Page 234 and 235:
ESA ESA Syr. sarb'ta 'generation, f
- Page 236 and 237:
STH sataha 'to spread out' STW sata
- Page 238 and 239:
Ug. Ug. Akk. saparu 'schicken, schr
- Page 240 and 241:
ESA ESA Syr. Syr. Aram. Aram. Heb.
- Page 242 and 243:
SLM saldm* 'safety'; salim 'one who
- Page 244 and 245:
Ug. sm Ug. Akk. sumu Akk. SNN sinn
- Page 246 and 247:
Heb. saw 1 'emptiness; vanity'; 'de
- Page 248 and 249:
SYH saha(y) 'to run backwards and S
- Page 250 and 251:
Aram. sitwa Aram. tfngta 'net, net-
- Page 252 and 253:
Heb. sarad 'to escape' Heb. Ph. Ph.
- Page 254 and 255:
Aram. Aram. sftar BA 'side' Heb. He
- Page 256 and 257:
Syr. Syr. Aram. Aram. Heb. Heb. Ph.
- Page 258 and 259:
SKL sakl 'a similitude, likeness' S
- Page 260 and 261:
SHD sahida 'to be present at; bear
- Page 262 and 263:
SWY sawan 'scalp' SY' saa(d) 'to wi
- Page 264 and 265:
SBB sabba* 'to pour' ?BH sabb aha '
- Page 266 and 267:
Ph. Ph. Ug. Ug. Akk. Akk. SDD sadda
- Page 268 and 269:
Ug. Ug. Akk. Akk. sarahu 'schreien,
- Page 270 and 271:
Aram. fer 'to disregard, shame, cur
- Page 272 and 273:
Syr. salbuba 'tibia' also 'a reed f
- Page 274 and 275:
Ug. Ug. Akk. Akk. SHR Sahara* 'to d
- Page 276 and 277:
SYD 'istada 'to hunt' SYR sara (y)*
- Page 278 and 279:
Syr. sah 'to glow, strike, beat (as
- Page 280 and 281:
DLL dalla* 'to err; wander away, go
- Page 282 and 283:
DYF dayyafa 'to entertain a guest'
- Page 284 and 285:
TRF tarf 'an eye, glance, sight of
- Page 286 and 287:
TFL tifl 'a very young child, infan
- Page 288 and 289:
TMN 'itmaanna 'to be quite; rest se
- Page 290 and 291:
ESA ESA tyb h. 'to be well-disposed
- Page 292 and 293:
Syr. tallel 'to cover, overshadow,
- Page 294 and 295:
C B 5 c aba } a 'to be solicitous a
- Page 296 and 297:
Heb. Heb. Ph, Ph. Ug. Ug. Akk. Akk.
- Page 298 and 299:
Syr. Syr. Aram. Aram. Heb. 'adasa '
- Page 300 and 301:
C RR ma'arra 'a crime' C RS c ars '
- Page 302 and 303:
C ZL c azala 'to remove, set aside'
- Page 304 and 305:
C SB Arab. Ge. ESA Syr. asib c asab
- Page 306 and 307:
C DW c idin obi. PI. of 'idda 'a se
- Page 308 and 309:
Aram. ca qab 'to trace, espy'; c iq
- Page 310 and 311:
Syr. Aram. Heb. Ph. Ug. Akk. C LW A
- Page 312 and 313:
Heb. Ph. Ug. Akk. Arab. c an Ge. ES
- Page 314 and 315:
ESA Syr. Aram. c ugyd Heb. c ugd Ph
- Page 317 and 318:
GBR Arab. Ge. ESA Syr. Aram. Heb. P
- Page 319 and 320:
Ug. Akk. aribu 'Rabe, Krahe' GRF 'i
- Page 321 and 322:
GSB Arab. Ge. ESA Syr. Aram. Heb. P
- Page 323 and 324:
Ug. Akk. Akk. 3 aglaf GLF Arab. Ge.
- Page 325 and 326:
GMD 'agmada 'to connive at the paym
- Page 327 and 328:
Ph. Ug- Akk. GWY gawd (y)* Arab. Ge
- Page 329 and 330:
Arab. fa- Ge. ESA Syr. Aram. Heb. P
- Page 331 and 332:
Syr. Aram. Heb. Ph. Ug. Akk. FTW Ar
- Page 333 and 334:
FRG Arab. Ge. ESA Syr. Aram. Heb. P
- Page 335 and 336:
FR C Arab. Ge. ESA Syr. Aram. Heb.
- Page 337 and 338:
Syr. Aram. Heb. Ph. Ug. Akk. FSR Ar
- Page 339 and 340:
Ph. Ug. Akk. FDD Arab. Ge. ESA Syr.
- Page 341 and 342:
Arab. Ge. ESA Syr. Aram. Heb. Ph. U
- Page 343 and 344:
Syr. p e lan 'so and so, a certain
- Page 345 and 346:
FWQ fawqa 'over, above'; 'afaqa 'to
- Page 347 and 348:
QBH Arab. Ge. ESA Syr. Aram. Heb. P
- Page 349 and 350:
Syr. Aram. Heb. Ph. Ug- Akk. Arab.
- Page 351 and 352:
Ph. Ug. Akk. QDF Arab. Ge. ESA Syr.
- Page 353 and 354:
QRD qarada* Arab. Ge. qarada ESA Sy
- Page 355 and 356:
Heb. Ph. Ug. Akk. QSD Arab. Ge. ESA
- Page 357 and 358:
Syr. Aram. Heb. Ph. Ug. Akk. or Ara
- Page 359 and 360:
Ph. Ug. Akk. QLD Arab. Ge. ESA Syr.
- Page 361 and 362:
Heb. Ph. Ug. Akk. QNT Arab. Ge. ESA
- Page 363 and 364:
Aram, qasta Heb. qeset Ph. qst Ug.
- Page 365 and 366:
Arab. Ge. ESA Syr. Aram. Heb. Ph. U
- Page 367 and 368:
Heb. Ph. Ug- Akk. KDY Arab. Ge. ESA
- Page 369 and 370:
KSF kisf* 'a segment, a piece cut o
- Page 371 and 372:
Aram. Heb. Ph. Ug. Akk. KFF Arab. G
- Page 373 and 374:
KLL kail Arab. Ge. ESA Syr. Aram. H
- Page 375 and 376:
Heb. Ph. Ug- Akk. KNN Arab. Ge. ESA
- Page 377 and 378:
Syr. Syr. w Aram. Aram. ^ Heb. kid
- Page 379 and 380:
Syr. Aram. Heb. Ph. Ug. Akk. LET Ar
- Page 381 and 382:
LHQ lahiqa* 'to overtake, reach, at
- Page 383 and 384:
LSN Arab. Ge. ESA Syr. Aram. Heb. P
- Page 385 and 386:
LFZ Arab. Ge. ESA Syr. Aram. Heb. P
- Page 387 and 388:
Ug. Akk. Arab. Ge. ESA Syr. Aram. H
- Page 389 and 390:
LHW Arab. Ge. ESA Syr. Aram. Heb. P
- Page 391 and 392:
LYL layl 'a night' LYN lana (y) 'to
- Page 393 and 394:
MTY Arab. Ge. ESA Syr. Aram. Heb. P
- Page 395 and 396:
Ph. Ug- Akk. MR' Arab. Ge. ESA Syr.
- Page 397 and 398:
Aram. Heb. Ph. Ug. Akk. MZQ Arab. G
- Page 399 and 400:
Syr. Aram. Heb. Ph. Ug- Akk. MDY ma
- Page 401 and 402:
MKT makata 'to delay, tarry, abide,
- Page 403 and 404:
Ph. Ph. Ug. Ug. mn(m) 'who(ever)? w
- Page 405 and 406:
Aram. Aram. Heb. mohal NH 'a thin s
- Page 407 and 408:
MYL mala (y) 'to turn away, aside,
- Page 409 and 410:
Syr. Syr. ifbd 'to flow (as water)'
- Page 411 and 412:
NHT nahata 'to scrape, carve' NHR n
- Page 413 and 414:
NDY nddd 'to call to, upon, invoke,
- Page 415 and 416:
Ug. Ug. Akk. Akk. nasahu 'ausreisse
- Page 417 and 418:
Aram. Heb. Ph. Ug. Akk. NST Arab. G
- Page 419 and 420:
Ph. Ug. Akk. NTF Arab. Ge. ESA Syr.
- Page 421 and 422:
Syr. Aram. Heb. Ph. Ug. Akk. NFH Ar
- Page 423 and 424:
Aram, n'paq BA. 'to go or come out'
- Page 425 and 426:
NKB nakaba* 'to turn aside' Arab. G
- Page 427 and 428:
Ug. Akk. NMM Arab. Ge. ESA Syr. Ara
- Page 429 and 430:
Heb. n'*aqa NH ' Qongnecked] camel'
- Page 431 and 432:
Syr. Aram. Heb. Ph. Akk. HGR Arab.
- Page 433 and 434:
Syr. Aram. Heb. Ph. Ug. Akk. HZL Ar
- Page 435 and 436:
Aram. Heb. Ph. Ug. Akk. HLL Arab. G
- Page 437 and 438:
Ph. Ug. Akk. HN 5 Arab. Ge. ESA Syr
- Page 439 and 440:
Syr. Aram. Heb. Ph. Ug- Akk. HYL Ar
- Page 441 and 442:
Aram. Heb. Ph. Ug. Akk. WTD 'awtad
- Page 443 and 444:
WGS 'awgasa 'to conceive in the min
- Page 445 and 446:
Heb. Ph. Ug- Akk. WDY Arab. Ge. ESA
- Page 447 and 448:
Syr. Aram. Heb. Ph. Ug- Akk. WZ C A
- Page 449 and 450:
Arab. Ge. ESA snt Syr. sentd Aram.
- Page 451 and 452:
Syr. Aram. Heb. Ph. Ug. Akk. WT' Ar
- Page 453 and 454:
WFD Arab. Ge. ESA Syr. Aram. Heb. P
- Page 455 and 456:
Aram. Heb. yaqcf 'to be dislocated,
- Page 457 and 458:
WLY Arab. Ge. ESA Syr. Aram. Heb. P
- Page 459 and 460:
Arab, yd O! (voc.) Ge. ye, yu inter
- Page 461 and 462:
Aram. Heb. Ph. Ug. Akk. YN C Arab.
- Page 463 and 464:
(cont.) 1 24 25 26 27 28 29 30 31 3
- Page 465 and 466:
(cont.) 76 77 78 79 80 81 82 83 84
- Page 467 and 468:
(cont.) 128 129 130 131 132 133 134
- Page 469 and 470:
(cont.) 180 181 182 183 184 185 186
- Page 471 and 472:
(cont.) 230 231 232 233 234 235 236
- Page 473 and 474:
(cant.) 1 2 3 4 5 6 7 8 9 10 11 12
- Page 475 and 476:
(cont.) 333 334 335 336 337 338 339
- Page 477 and 478:
(cont.) 385 386 387 388 389 390 391
- Page 479 and 480:
(cont.) 437 438 439 440 441 442 443
- Page 481 and 482:
(cont.) 488 489 490 491 492 493 494
- Page 483 and 484:
(cont.) 540 541 542 543 544 545 546
- Page 485 and 486:
(cont.) 1 2 3 4 5 6 7 8 9 10 11 12
- Page 487 and 488:
(com.) 1 2 3 4 5 6 7 8 9 10 11 12 1
- Page 489 and 490:
(cont.) 695 696 697 698 699 700 701
- Page 491 and 492:
(cont.) 747 748 749 750 751 752 753
- Page 493 and 494:
799 800 801 802 803 804 805 806 807
- Page 495 and 496:
850 851 852 853 854 855 856 857 858
- Page 497 and 498:
(cont.) 901 902 903 904 905 906 907
- Page 499 and 500:
(cont.) 951 952 953 954 955 956 957
- Page 501 and 502:
(cont.) 1002 1003 1004 1005 1006 10
- Page 503 and 504:
(cont.) 1054 1055 1056 1057 1058 10
- Page 505 and 506:
1105 1106 1107 1108 1109 1110 1111
- Page 507 and 508:
1156 1157 1158 1159 1160 1161 1162
- Page 509 and 510:
(cont.) 1207 1208 1209 1210 1211 12
- Page 511 and 512:
1259 1260 1261 1262 1263 1264 1265
- Page 513 and 514:
(cont.) 1310 1311 1312 1313 1314 13
- Page 515 and 516:
(cont.) \ 1361 1362 1363 1364 1365
- Page 517 and 518:
(cont.) 1412 1413 1414 1415 1416 14
- Page 519 and 520:
(cont.) 1464 1465 1466 1467 1468 14
- Page 521 and 522:
(cont.) 1515 1516 1517 1518 1519 15
- Page 523 and 524:
(cont.) 1 2 3 4 5 6 7 8 9 10 11 12
- Page 525 and 526: (cont.) 1618 1619 1620 1621 1622 16
- Page 527 and 528: (cont.) 1669 1670 1671 1672 1673 16
- Page 529 and 530: CHAPTER FOUR DIACHRONIC SEMANTIC OB
- Page 531 and 532: 516 CHAPTER FOUR not always possibl
- Page 533 and 534: 518 CHAPTER FOUR iv. baata - 2: 213
- Page 535 and 536: 520 CHAPTER FOUR xv. rid 3 'a helpe
- Page 537 and 538: 522 CHAPTER FOUR b. 'to be superior
- Page 539 and 540: 524 CHAPTER FOUR a. X. 'to elicit,
- Page 541 and 542: 526 CHAPTER FOUR a. 'to join, come
- Page 543 and 544: 528 CHAPTER FOUR ii. Arab, 'alf (cf
- Page 545 and 546: 530 CHAPTER FOUR and specialized. O
- Page 547 and 548: 532 CHAPTER FOUR adaptation). 43 In
- Page 549 and 550: 534 CHAPTER FOUR xxxiv. Arab, sarib
- Page 551 and 552: 536 CHAPTER FOUR xlviii. Arab, say
- Page 553 and 554: 538 CHAPTER FOUR Ixi. Arab.farasa (
- Page 555 and 556: 540 CHAPTER FOUR 'woman' bridge the
- Page 557 and 558: 542 CHAPTER FOUR Ixxxiii. Arab, har
- Page 559 and 560: 544 CHAPTER FOUR ii. Arab. 3 amara
- Page 561 and 562: 546 CHAPTER FOUR xii. Arab, rafat
- Page 563 and 564: 548 CHAPTER FOUR xxii. Arab, sahida
- Page 565 and 566: 550 CHAPTER FOUR xxx. Arab, 'istafa
- Page 567 and 568: 552 CHAPTER FOUR non conobbero 1'ar
- Page 569 and 570: 554 CHAPTER FOUR most probably deno
- Page 571 and 572: 556 CHAPTER FOUR of evidence from o
- Page 573 and 574: 558 CHAPTER FOUR xx. Arab, 'afsah -
- Page 575: 560 CHAPTER FOUR must not be underm
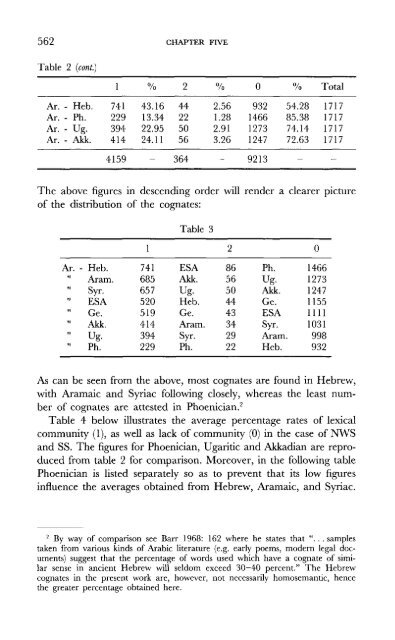
- Page 579 and 580: 564 CHAPTER FIVE 5.3 Distribution b
- Page 581 and 582: 566 Table 7 (cont.} 4. 5. 6. 7. 8.
- Page 583 and 584: 568 CHAPTER FIVE 1 . Only in SS H 2
- Page 585 and 586: Distr. 1 2 Al 4 3 A2 7 3 A3 4 3 A4
- Page 587 and 588: 572 CHAPTER FIVE 5.4.1 Distribution
- Page 589 and 590: 574 CHAPTER FIVE this Common Semiti
- Page 591 and 592: 576 CHAPTER FIVE (27%) belong to se
- Page 593 and 594: CHAPTER SIX SUMMARY AND CONCLUSIONS
- Page 595 and 596: 580 CHAPTER SIX 1200 B.C., 10 the s
- Page 597 and 598: 582 CHAPTER SIX interest to this wo
- Page 599 and 600: 584 CHAPTER SIX precariousness of a
- Page 601 and 602: 586 CHAPTER SIX is still shrouded i
- Page 603 and 604: 588 CHAPTER SIX NWS in sub-domain D
- Page 605 and 606: 590 CHAPTER SIX component of its le
- Page 607 and 608: 592 APPENDIX 'afaka CDG 9 is not co
- Page 609 and 610: 594 APPENDIX bada(y) Cf. Ge. 'abda
- Page 611 and 612: 596 APPENDIX hugga The SS cognates
- Page 613 and 614: 598 APPENDIX halaqa Perhaps related
- Page 615 and 616: 600 APPENDIX ricflradiyalradda Thes
- Page 617 and 618: 602 APPENDIX confirmed. A possible
- Page 619 and 620: 604 APPENDIX sarqfa The cognates co
- Page 621 and 622: 606 APPENDIX c attala The NWS cogna
- Page 623 and 624: 608 APPENDIX Arabic encompasses mos
- Page 625 and 626: 610 APPENDIX kabba In Arab. KBB/KBK
- Page 627 and 628:
612 APPENDIX according to Brauner,
- Page 629 and 630:
614 APPENDIX nasiya The sense 'to n
- Page 631 and 632:
616 APPENDIX and recognized it' (LA
- Page 633 and 634:
618 BIBLIOGRAPHY Biella, J.C. 1982
- Page 635 and 636:
620 BIBLIOGRAPHY Diakonoff, I.M. 19
- Page 637 and 638:
622 BIBLIOGRAPHY Held, M. 1965 "Stu
- Page 639 and 640:
624 BIBLIOGRAPHY Lyons, J. 1963 Str
- Page 641 and 642:
626 BIBLIOGRAPHY 1969a "Hebrew Bibl
- Page 643 and 644:
This page intentionally left blank
- Page 645 and 646:
630 INDEX OF ARABIC LEXICAL ITEMS '
- Page 647 and 648:
632 INDEX OF ARABIC LEXICAL ITEMS h
- Page 649 and 650:
634 INDEX OF ARABIC LEXICAL ITEMS d
- Page 651 and 652:
636 INDEX OF ARABIC LEXICAL ITEMS '
- Page 653 and 654:
638 INDEX OF ARABIC LEXICAL ITEMS t
- Page 655 and 656:
640 INDEX OF ARABIC LEXICAL ITEMS f
- Page 657 and 658:
642 INDEX OF ARABIC LEXICAL ITEMS '
- Page 659 and 660:
644 INDEX OF ARABIC LEXICAL ITEMS n
- Page 661 and 662:
'Abu Bakr, 44, 46 n. 94 Abyssinian,
- Page 663 and 664:
648 GENERAL INDEX compatibility con
- Page 665 and 666:
650 GENERAL INDEX primary and secon
- Page 667 and 668:
652 GENERAL INDEX Sprachraum contin
- Page 669 and 670:
1/2/2/2. Boyce, M. A History of ^pr
- Page 671 and 672:
Band 33 Gessel, B.H.L. van. Onomast