

PhD thesis - School of Informatics - University of Edinburgh
PhD thesis - School of Informatics - University of Edinburgh
PhD thesis - School of Informatics - University of Edinburgh

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Chapter 3. Tracking English Inclusions in German 96<br />
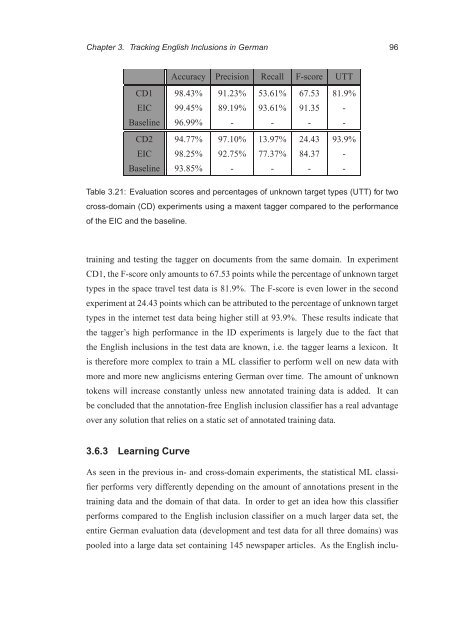
Accuracy Precision Recall F-score UTT<br />
CD1 98.43% 91.23% 53.61% 67.53 81.9%<br />
EIC 99.45% 89.19% 93.61% 91.35 -<br />
Baseline 96.99% - - - -<br />
CD2 94.77% 97.10% 13.97% 24.43 93.9%<br />
EIC 98.25% 92.75% 77.37% 84.37 -<br />
Baseline 93.85% - - - -<br />
Table 3.21: Evaluation scores and percentages <strong>of</strong> unknown target types (UTT) for two<br />
cross-domain (CD) experiments using a maxent tagger compared to the performance<br />
<strong>of</strong> the EIC and the baseline.<br />
training and testing the tagger on documents from the same domain. In experiment<br />
CD1, the F-score only amounts to 67.53 points while the percentage <strong>of</strong> unknown target<br />
types in the space travel test data is 81.9%. The F-score is even lower in the second<br />
experiment at 24.43 points which can be attributed to the percentage <strong>of</strong> unknown target<br />
types in the internet test data being higher still at 93.9%. These results indicate that<br />
the tagger’s high performance in the ID experiments is largely due to the fact that<br />
the English inclusions in the test data are known, i.e. the tagger learns a lexicon. It<br />
is therefore more complex to train a ML classifier to perform well on new data with<br />
more and more new anglicisms entering German over time. The amount <strong>of</strong> unknown<br />
tokens will increase constantly unless new annotated training data is added. It can<br />
be concluded that the annotation-free English inclusion classifier has a real advantage<br />
over any solution that relies on a static set <strong>of</strong> annotated training data.<br />
3.6.3 Learning Curve<br />
As seen in the previous in- and cross-domain experiments, the statistical ML classi-<br />
fier performs very differently depending on the amount <strong>of</strong> annotations present in the<br />
training data and the domain <strong>of</strong> that data. In order to get an idea how this classifier<br />
performs compared to the English inclusion classifier on a much larger data set, the<br />
entire German evaluation data (development and test data for all three domains) was<br />
pooled into a large data set containing 145 newspaper articles. As the English inclu-













