

PhD thesis - School of Informatics - University of Edinburgh
PhD thesis - School of Informatics - University of Edinburgh
PhD thesis - School of Informatics - University of Edinburgh

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Chapter 4. System Extension to a New Language 113<br />
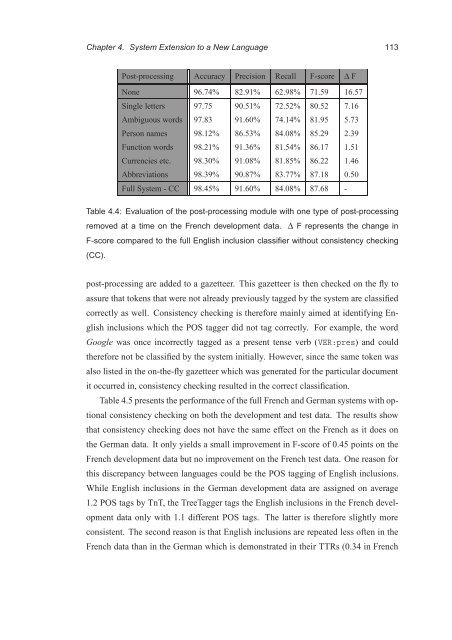
Post-processing Accuracy Precision Recall F-score Δ F<br />
None 96.74% 82.91% 62.98% 71.59 16.57<br />
Single letters 97.75 90.51% 72.52% 80.52 7.16<br />
Ambiguous words 97.83 91.60% 74.14% 81.95 5.73<br />
Person names 98.12% 86.53% 84.08% 85.29 2.39<br />
Function words 98.21% 91.36% 81.54% 86.17 1.51<br />
Currencies etc. 98.30% 91.08% 81.85% 86.22 1.46<br />
Abbreviations 98.39% 90.87% 83.77% 87.18 0.50<br />
Full System - CC 98.45% 91.60% 84.08% 87.68 -<br />
Table 4.4: Evaluation <strong>of</strong> the post-processing module with one type <strong>of</strong> post-processing<br />
removed at a time on the French development data. Δ F represents the change in<br />
F-score compared to the full English inclusion classifier without consistency checking<br />
(CC).<br />
post-processing are added to a gazetteer. This gazetteer is then checked on the fly to<br />
assure that tokens that were not already previously tagged by the system are classified<br />
correctly as well. Consistency checking is therefore mainly aimed at identifying En-<br />
glish inclusions which the POS tagger did not tag correctly. For example, the word<br />
Google was once incorrectly tagged as a present tense verb (VER:pres) and could<br />
therefore not be classified by the system initially. However, since the same token was<br />
also listed in the on-the-fly gazetteer which was generated for the particular document<br />
it occurred in, consistency checking resulted in the correct classification.<br />
Table 4.5 presents the performance <strong>of</strong> the full French and German systems with op-<br />
tional consistency checking on both the development and test data. The results show<br />
that consistency checking does not have the same effect on the French as it does on<br />
the German data. It only yields a small improvement in F-score <strong>of</strong> 0.45 points on the<br />
French development data but no improvement on the French test data. One reason for<br />
this discrepancy between languages could be the POS tagging <strong>of</strong> English inclusions.<br />
While English inclusions in the German development data are assigned on average<br />
1.2 POS tags by TnT, the TreeTagger tags the English inclusions in the French devel-<br />
opment data only with 1.1 different POS tags. The latter is therefore slightly more<br />
consistent. The second reason is that English inclusions are repeated less <strong>of</strong>ten in the<br />
French data than in the German which is demonstrated in their TTRs (0.34 in French













