

PhD thesis - School of Informatics - University of Edinburgh
PhD thesis - School of Informatics - University of Edinburgh
PhD thesis - School of Informatics - University of Edinburgh

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Chapter 3. Tracking English Inclusions in German 69<br />
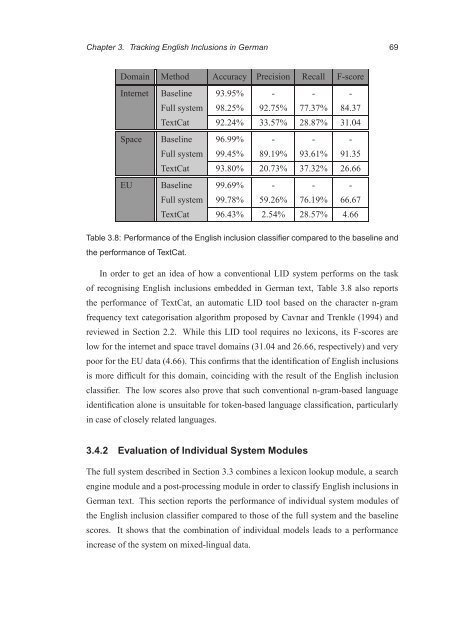
Domain Method Accuracy Precision Recall F-score<br />
Internet Baseline 93.95% - - -<br />
Full system 98.25% 92.75% 77.37% 84.37<br />
TextCat 92.24% 33.57% 28.87% 31.04<br />
Space Baseline 96.99% - - -<br />
Full system 99.45% 89.19% 93.61% 91.35<br />
TextCat 93.80% 20.73% 37.32% 26.66<br />
EU Baseline 99.69% - - -<br />
Full system 99.78% 59.26% 76.19% 66.67<br />
TextCat 96.43% 2.54% 28.57% 4.66<br />
Table 3.8: Performance <strong>of</strong> the English inclusion classifier compared to the baseline and<br />
the performance <strong>of</strong> TextCat.<br />
In order to get an idea <strong>of</strong> how a conventional LID system performs on the task<br />
<strong>of</strong> recognising English inclusions embedded in German text, Table 3.8 also reports<br />
the performance <strong>of</strong> TextCat, an automatic LID tool based on the character n-gram<br />
frequency text categorisation algorithm proposed by Cavnar and Trenkle (1994) and<br />
reviewed in Section 2.2. While this LID tool requires no lexicons, its F-scores are<br />
low for the internet and space travel domains (31.04 and 26.66, respectively) and very<br />
poor for the EU data (4.66). This confirms that the identification <strong>of</strong> English inclusions<br />
is more difficult for this domain, coinciding with the result <strong>of</strong> the English inclusion<br />
classifier. The low scores also prove that such conventional n-gram-based language<br />
identification alone is unsuitable for token-based language classification, particularly<br />
in case <strong>of</strong> closely related languages.<br />
3.4.2 Evaluation <strong>of</strong> Individual System Modules<br />
The full system described in Section 3.3 combines a lexicon lookup module, a search<br />
engine module and a post-processing module in order to classify English inclusions in<br />
German text. This section reports the performance <strong>of</strong> individual system modules <strong>of</strong><br />
the English inclusion classifier compared to those <strong>of</strong> the full system and the baseline<br />
scores. It shows that the combination <strong>of</strong> individual models leads to a performance<br />
increase <strong>of</strong> the system on mixed-lingual data.













