HIGH-PERFORMANCE COMPUTINGApplicationCompilerMiddlewareOperating systemProtocolInterconnectPlatformConfiguring the test environmentThe test environment was based on a cluster comprising 32 <strong>Dell</strong><strong>Power</strong>Edge 3250 servers interconnected with nonblocking GigabitEthernet and Myricom Myrinet. The Gigabit Ethernet interconnectcomprised one Myricom M3-E128 switch enclosure populated with16 Myrinet M3-SW16-8E switch line cards, each having 8 GigabitEthernet ports (at 1 Gbps link speed) for 128 ports total. The Myrinetinterconnect comprised one Myricom M3-E128 switch enclosurepopulated with 16 Myrinet M3-SW16-8F switch line cards, eachhaving 8 fiber ports (at 2 Gbps link speed) for 128 ports total.Each <strong>Power</strong>Edge 3250 was configured with two Intel ®Itanium®2processors running at 1.3 GHz with 3 MB of level 3 (L3) cache and4 GB of double data rate (DDR) RAM operating on a 400 MHz frontsidebus. Each <strong>Power</strong>Edge 3250 had an Intel ®E8870 chip set ScalableNode Controller (SNC), which accommodates up to eight registeredDDR dual in-line memory modules (DIMMs). The operating system wasRed Hat ®Enterprise Linux®AS 2.1 with kernel version 2.4.18-e.37smp.Intel ®Fortran and C++ Compilers 7.1 (Build 20030909) were usedto link STAR-CD V3.150A.012 with MPICH 1.2.4 and MPICH-GM1.2.5..10. Figure 1 shows the architectural stack of the computationaltest environment.Measuring application efficiencyThe efficiency in parallel applications is usually measured by speedup.The speedup of an application on a cluster with N processors is definedas t 1 / t N, where t 1 is the execution time of the application running onone processor and t N is the execution time of the application runningacross N processors. In theory, the maximum speedup of a parallelsimulation with N processors isSTAR-CD V3.150A.012Intel Fortran and C++ Compilers 7.1MPICH 1.2.4 and MPICH-GM 1.2.5..10Red Hat Enterprise Linux AS 2.1, kernel 2.4.18-e.37smpTCP/IP, GM-2Gigabit Ethernet, MyrinetFigure 1. Architectural stack of the computational test environment<strong>Dell</strong> <strong>Power</strong>Edge 3250 servers in a 32-node clusterN—that is, the program runsN timesfaster than it would on a single processor. However, in reality, as thenumber of processors increases, application speedup is usually lessthan N. The disparity between theoretical and actual performance canbe attributed to factors that include increasing parallel job initiation,interprocessor communication, file I/O, and network contention.Running test casesCD adapco Group provides a suite of six test cases selected to demonstratethe versatility and robustness of STAR-CD in CFD solutionsand the relative performance of the application on different hardwareplatforms and different processor configurations. 2 CD adapco Groupselected these test cases to be industry representative, categorizingthem as small, medium, and large. Figure 2 lists benchmark namesand brief descriptions of the data sets used in this study.In this study, the small (Engine block) and the large (A-class)test cases were used to perform the analysis and draw the conclusionsregarding the application performance and sensitivity todifferent hardware configurations. Each test case was performedon 1, 2, 4, 8, 16, and 32 processors to help assess the scalabilityof the application in different hardware configurations, such asusing two processors versus one processor on each node, usingthe local file system versus NFS, and using Gigabit Ethernet versusMyrinet interconnects. All the benchmark runs were conductedusing the double-precision version of the code and the conjugategradient solver.When running the application over the Myrinet interconnectusing MPICH-GM 1.2.5..10, testers had to make sure that theRAMFILES and TURBO environment variables were properly passedto each node because the mpirun shell script does not handle thistask the same way that MPICH 1.2.4 does. Initially, benchmarkruns using Gigabit Ethernet were much faster than the runs usingMyrinet. By setting the RAMFILES and TURBO environmentvariables, <strong>Dell</strong> engineers enabled STAR-CD to use a solver codeoptimized for Itanium 2 architecture and RAMFILES—resulting inimproved application performance with the Myrinet interconnect.Comparing the performance of the local file system versus NFSSome applications perform several file I/O operations during execution,while other applications do most of the I/O at the end ofthe simulation and still other applications do very little I/O at all.Direct (local) or remote (NFS) access to the file system can affectthe application’s performance because file I/O is usually slowerthan other operations such as computation and communication. Toobserve the performance impact of NFS compared to the local filesystem, <strong>Dell</strong> engineers ran the Engine block and A-class test cases inClass Benchmark Cells Mesh DescriptionSmall Engine block 156,739 Hexahedral Engine cooling in automobileengine blockLarge A-class 5,914,426 Hybrid Turbulent flow aroundA-class carFigure 2. STAR-CD benchmarks used in the <strong>Dell</strong> test2For more information about STAR-CD benchmarks and data sets, visit www.cd-adapco.com/support/bench/315/index.htm.124POWER SOLUTIONS Reprinted from <strong>Dell</strong> <strong>Power</strong> <strong>Solutions</strong>, February 2005. Copyright © 2005 <strong>Dell</strong> Inc. All rights reserved. February 2005
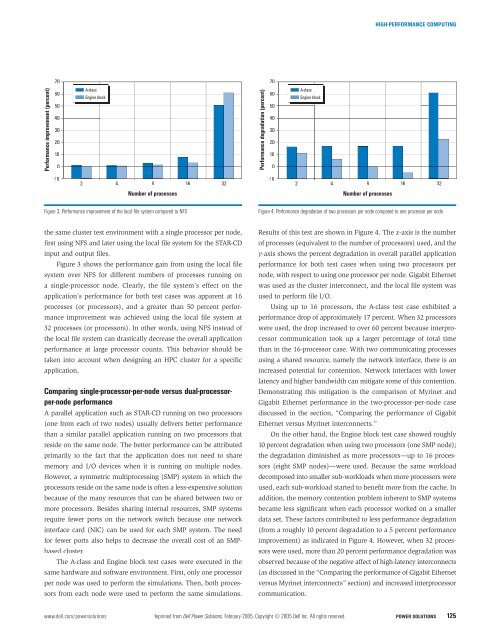
HIGH-PERFORMANCE COMPUTING7070Performance improvement (percent)6050403020100A-classEngine blockPerformance degradation (percent)6050403020100A-classEngine block-102 4 8 16 32-102 4 8 16 32Number of processesNumber of processesFigure 3. Performance improvement of the local file system compared to NFSFigure 4. Performance degradation of two processors per node compared to one processor per nodethe same cluster test environment with a single processor per node,first using NFS and later using the local file system for the STAR-CDinput and output files.Figure 3 shows the performance gain from using the local filesystem over NFS for different numbers of processes running ona single-processor node. Clearly, the file system’s effect on theapplication’s performance for both test cases was apparent at 16processes (or processors), and a greater than 50 percent performanceimprovement was achieved using the local file system at32 processes (or processors). In other words, using NFS instead ofthe local file system can drastically decrease the overall applicationperformance at large processor counts. This behavior should betaken into account when designing an HPC cluster for a specificapplication.Comparing single-processor-per-node versus dual-processorper-nodeperformanceA parallel application such as STAR-CD running on two processors(one from each of two nodes) usually delivers better performancethan a similar parallel application running on two processors thatreside on the same node. The better performance can be attributedprimarily to the fact that the application does not need to sharememory and I/O devices when it is running on multiple nodes.However, a symmetric multiprocessing (SMP) system in which theprocessors reside on the same node is often a less-expensive solutionbecause of the many resources that can be shared between two ormore processors. Besides sharing internal resources, SMP systemsrequire fewer ports on the network switch because one networkinterface card (NIC) can be used for each SMP system. The needfor fewer ports also helps to decrease the overall cost of an SMPbasedcluster.The A-class and Engine block test cases were executed in thesame hardware and software environment. First, only one processorper node was used to perform the simulations. Then, both processorsfrom each node were used to perform the same simulations.Results of this test are shown in Figure 4. The x-axis is the numberof processes (equivalent to the number of processors) used, and they-axis shows the percent degradation in overall parallel applicationperformance for both test cases when using two processors pernode, with respect to using one processor per node. Gigabit Ethernetwas used as the cluster interconnect, and the local file system wasused to perform file I/O.Using up to 16 processors, the A-class test case exhibited aperformance drop of approximately 17 percent. When 32 processorswere used, the drop increased to over 60 percent because interprocessorcommunication took up a larger percentage of total timethan in the 16-processor case. With two communicating processesusing a shared resource, namely the network interface, there is anincreased potential for contention. Network interfaces with lowerlatency and higher bandwidth can mitigate some of this contention.Demonstrating this mitigation is the comparison of Myrinet andGigabit Ethernet performance in the two-processor-per-node casediscussed in the section, “Comparing the performance of GigabitEthernet versus Myrinet interconnects.”On the other hand, the Engine block test case showed roughly10 percent degradation when using two processors (one SMP node);the degradation diminished as more processors—up to 16 processors(eight SMP nodes)—were used. Because the same workloaddecomposed into smaller sub-workloads when more processors wereused, each sub-workload started to benefit more from the cache. Inaddition, the memory contention problem inherent to SMP systemsbecame less significant when each processor worked on a smallerdata set. These factors contributed to less performance degradation(from a roughly 10 percent degradation to a 5 percent performanceimprovement) as indicated in Figure 4. However, when 32 processorswere used, more than 20 percent performance degradation wasobserved because of the negative affect of high-latency interconnects(as discussed in the “Comparing the performance of Gigabit Ethernetversus Myrinet interconnects” section) and increased interprocessorcommunication.www.dell.com/powersolutions Reprinted from <strong>Dell</strong> <strong>Power</strong> <strong>Solutions</strong>, February 2005. Copyright © 2005 <strong>Dell</strong> Inc. All rights reserved. POWER SOLUTIONS 125