UVOD U EKONOMETRIJU
uvod u ekonometriju - Fakultet ekonomije i turizma "Dr. Mijo MirkoviÄ"
uvod u ekonometriju - Fakultet ekonomije i turizma "Dr. Mijo MirkoviÄ"
- No tags were found...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Sveučilište Jurja Dobrile u Puli<br />
Odjel za ekonomiju i turizam<br />
„Dr. Mijo Mirković“<br />
Alen Belullo<br />
<strong>UVOD</strong> U <strong>EKONOMETRIJU</strong>
Sveučilište Jurja Dobrile u Puli<br />
Odjel za ekonomiju i turizam<br />
„Dr. Mijo Mirković“<br />
<strong>UVOD</strong> U <strong>EKONOMETRIJU</strong><br />
Sveučilišni udžbenik<br />
Autor: Doc. dr. sc. Alen Belullo
Copyright © Belullo, Alen<br />
Nakladnik:<br />
Sveučilište Jurja Dobrile u Puli<br />
Odjel za ekonomiju i turizam<br />
„Dr. Mijo Mirković“<br />
Za nakladnika:<br />
Prof. dr. sc. Robert Matijašić, rektor<br />
Recenzenti:<br />
Dr. sc. Goran Buturac<br />
Prof. dr. sc. Ante Rozga<br />
Lektura:<br />
Marija Belullo, prof.<br />
Objavljivanje ove knjige odobrio je Senat Sveučilišta Jurja Dobrile u Puli<br />
odlukom Klasa: 003-08/11-02/70-01, Ur. broj: 380/11-01/-1 od 15. prosinca<br />
2011. godine sukladno Zaključku Povjerenstva za izdavačku djelatnost<br />
Sveučilišta Jurja Dobrile u Puli od 28. studenog 2011. godine.<br />
<strong>UVOD</strong> U <strong>EKONOMETRIJU</strong>/ Alen Belullo. – Pula:<br />
Sveučilište Jurja Dobrile u Puli, Odjel za ekonomiju i<br />
turizam „Dr. Mijo Mirković“, 2011.<br />
Bibliografija.<br />
ISBN 978-953-7498-50-4<br />
1. Belullo, A.
Sadrµzaj<br />
Predgovor<br />
iii<br />
1 Uvod u regresijsku analizu 1<br />
1.1 Pojam ekonometrije . . . . . . . . . . . . . . . . . . . . . . . 1<br />
1.2 Koraci u ekonometrijskoj analizi . . . . . . . . . . . . . . . . 2<br />
1.2.1 Odre†ivanje teorije ili hipoteze . . . . . . . . . . . . . 2<br />
1.2.2 Speci…kacija matematiµckog modela . . . . . . . . . . . 2<br />
1.2.3 Speci…kacija ekonometrijskog modela . . . . . . . . . . 3<br />
1.2.4 Prikupljanje podataka . . . . . . . . . . . . . . . . . . 5<br />
1.2.5 Procjena ekonometrijskog modela . . . . . . . . . . . . 9<br />
1.2.6 Testiranje hipoteza . . . . . . . . . . . . . . . . . . . . 10<br />
1.2.7 Prognoziranje i predvi†anje . . . . . . . . . . . . . . . 10<br />
1.3 Regresijska funkcija populacije i regresijska funkcija uzorka . 11<br />
2 Parametri modela dobiveni metodom najmanjih kvadrata 18<br />
2.1 Procjena parametara . . . . . . . . . . . . . . . . . . . . . . . 18<br />
2.2 Svojstva regresijskog pravca . . . . . . . . . . . . . . . . . . . 26<br />
2.3 Svojstva procjenitelja . . . . . . . . . . . . . . . . . . . . . . 28<br />
3 Pokazatelji kvalitete regresije 32<br />
3.1 Koe…cijent determinacije . . . . . . . . . . . . . . . . . . . . . 33<br />
3.2 Znaµcajnost procjenitelja . . . . . . . . . . . . . . . . . . . . . 39<br />
3.2.1 Standardna greška procjenitelja . . . . . . . . . . . . . 39<br />
3.2.2 Testiranje hipoteza nad procjeniteljima . . . . . . . . 42<br />
A Izvodi i dokazi 57<br />
A.1 Izvod parametara modela s jednom nezavisnom varijablom<br />
metodom najmanjih kvadrata . . . . . . . . . . . . . . . . . . 57<br />
B Matematika 59<br />
B.1 Neka svojstva operatora zbrajanja P . . . . . . . . . . . . . . 59<br />
i
C Statistika 61<br />
C.1 Distribucije vjerojatnosti izvedene iz normalne distribucije . . 61<br />
D Podaci 62<br />
D.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62<br />
E Statistiµcke tablice 63<br />
ii
Predgovor<br />
Ovaj udµzbenik nastaje iz potrebe da studenti lakše shvate teorijske pretpostavke<br />
na kojima se temelji metoda najmanjih kvadrata. Cilj je bio napisati<br />
rad koji polazi od osnovnih ekonometrijskih pojmova, tj. namijenjen je µcitatelju<br />
koji nema nikakvog predznanja iz tog podruµcja, ali je ipak pisan u<br />
strogoj matematiµckoj formi, kako bi se izbjegle zamke nedoreµcenosti, u koje<br />
upadaju mnogi udµzbenici iz ekonometrije, pisani za poµcetnu razinu. Kako<br />
ne bi prosjeµcnom µcitatelju opterećivali tekst sloµzeniji matematiµcki dokazi<br />
i osnove teorije distribucije vjerojatnosti, dani su u dodacima. Matematiµcka<br />
notacija konzistentna je kroz cijeli rad (npr. populacijske vrijednosti<br />
su uvijek oznaµcene grµckim alfabetom, dok vrijednosti uzoraka uvijek latinskom<br />
abecedom, velikim podebljanim slovima oznaµcene su matrice, malim<br />
podebljanim slovima vektori, nepodebljani izrazi su skalari, varijable u devijacijskoj<br />
formi su uvijek prikazane tildom itd.).<br />
U knjizi se nadalje, zbog potreba poopćavanja, paralelno koristi obiµcna<br />
algebra, karakteristiµcna za poµcetniµcke udµzbenika, i matriµcna algebra, karakteristiµcna<br />
za napredne udµzbenike iz ekonometrije. Na taj se naµcin pokušao<br />
premostiti jaz, koji postoji izme†u poµcetnih udµzbenika i naprednih udµzbenika<br />
iz ekonometrije, tj. da se zorno prikaµze na koji se naµcin mogu poopćiti<br />
«obiµcne» jednadµzbe kojima se prikazuju jednostavniji modeli (npr. modeli s<br />
jednom nezavisnom varijablom) putem matriµcnog zapisa istih ekonometrijskih<br />
izraza koji vrijede za sloµzenije modele (npr. s k 1 nezavisnih varijabli).<br />
Na taj se naµcin moµze dobiti dojam elegancije i kompaktnosti matriµcnog zapisa,<br />
a korištenjem matriµcno orijentiranih softwarea brzo i e…kasno rješavati<br />
zadatke prikazane u knjizi.<br />
U knjizi su prikazani mnogobrojni primjeri i zadaci te su dani svi podaci<br />
potrebni µcitatelju da bi mogao sam jednostavno reproducirati prikazane<br />
dobivene rezultate.<br />
Osim studentima, koji slušaju predmet Ekonometrija, Analiza vremenskih<br />
nizova, Ekonometrija II, namijenjen je i istraµzivaµcima koji µzele dobiti<br />
µcvrste temelje, kako bi shvatili samu bit regresijske analize pomoću metode<br />
najmanjih kvadrata. Što se tiµce potrebnog predznanja, da bi se knjiga mogla<br />
lako µcitati, potrebno je samo osnovno znanje iz matriµcne algebre.<br />
Knjiga je podijeljena u tri poglavlja: u prvom dijelu objašnjava se poiii
jam ekonometrije, koraci u ekonometrijskoj analizi te regresijska funkcija<br />
populacije i uzorka; u drugom dijelu objašnjava se na koji se naµcin dobivaju<br />
parametri metodom najmanjih kvadrata, svojstva regresijskog pravaca i<br />
procjenitelja, da bi se u zadnjem dijelu prikazali pokazatelji kvalitete regresije.<br />
Budući da je ova knjiga proizašla iz dijelova priprema za predavanja iz<br />
predmeta Ekonometrija µzelio bih se zahvaliti svim studentima koji su svojim<br />
komentarima i pitanjima tijekom predavanja doprinijeli da se knjiga pribliµzi<br />
njihovim potrebama i boljem razumijevanju gradiva, kao i svim onim studentima<br />
koji su uspješno detektirali tiskarske greške u radnim verzijama<br />
ovog rada, jer sam svjestan da je rat s tiskarskim greškama bespovratno<br />
izgubljen, ali poneka je bitka dobivena, zahvaljujući njima. Nadalje, posebno<br />
bih se zahvalio profesorici Mariji Bušelić i Sanji Blaµzević koje su svojom<br />
beskrajnom upornošću i altruizmom doprinijele da ova knjiga uopće ugleda<br />
svjetlost dana. Za tehniµcku podršku zahvalio bih se Ðaniju Buriću. Na kraju<br />
volio bih reći jedno veliko hvala bliµzim µclanovima moje obitelji na njihovim<br />
sugestijama i lekturi, te za uvijek prisutnu podršku kada su s dubokim razumijevanjem<br />
µcesto morali podnositi moja prevrtljiva raspoloµzenja tijekom<br />
njezinog nastajanja.<br />
iv
Poglavlje 1<br />
Uvod u regresijsku analizu<br />
1.1 Pojam ekonometrije<br />
Ekonometrija doslovno znaµci ekonomsko mjerenje. Ekonometriju moµzemo<br />
de…nirati kao znanstvenu disciplinu koja se bavi empiriµckim dokazivanjem<br />
ekonomskih zakona de…niranih u ekonomskoj teoriji. Usko je vezana uz<br />
discipline: ekonomska teorija, matematiµcka ekonomija i ekonomska<br />
statistika.<br />
Ekonomska teorija postavlja svoje zakone uglavnom na kvalitativnoj razini,<br />
tj. odre†uje smjer kretanja zavisnosti odre†enih ekonomskih pojava,<br />
bez odre†ivanja veliµcine i znaµcajnosti tih veza.<br />
Matematiµcka ekonomija izraµzava ekonomsku teoriju u odre†enoj matematiµckoj<br />
formi (jednadµzbe), bez osvrtanja na empiriµcku provjeru tih teorija.<br />
Ekonomska statistika bavi se prikupljanjem, obradom i prezentiranjem<br />
ekonomskih pokazatelja u obliku tablica i slika. Ekonomska statistika ne bavi<br />
se provjerom ekonomskih teorija na temelju tako prikupljenih podataka.<br />
Znaµci, ekonometrijom se provjeravaju, koristeći se metodama matematiµcke<br />
ekonomije i podacima dobivenim iz statistike, jesu li valjane ekonomske<br />
teorije za odre†eni uzorak (populaciju).<br />
Ekonometriju moµzemo podijeliti u dvije glavne skupine: teorijska ekonometrija<br />
i primijenjena ekonometrija. Teorijska ekonometrija bavi se<br />
razvijanjem ekonometrijskih metoda, dok se primijenjena ekonometrija bavi<br />
primjenjivanjem ekonometrijskih metoda koje je razvila teorijska ekonometrija<br />
na konkretnim ekonomskim problemima.<br />
Teorijska i primijenjena ekonometrija mogu koristiti ili Bayesov ili klasiµcni<br />
pristup statistiµckom zakljuµcivanju. Glavna je razlika izme†u ova dva<br />
pristupa u njihovom poimanju vjerojatnosti. Po Bayesovom pristupu vjerojatnost<br />
se odnosi na stupanj razumno prihvatljivog uvjerenja; vjerojatnost je<br />
vezana za stupnjeve pouzdanosti koje istraµzivaµc unaprijed ima o nekom empiriµckom<br />
fenomenu (prije samog promatranja podataka). Drugim rijeµcima<br />
po Bayesu imamo subjektivni pristup konceptu vjerojatnosti. Po klasiµcnom<br />
1
pristupu vjerojatnost se odnosi na frekvenciju pojavljivanja odre†enog doga†aja<br />
u ponovljenim izvlaµcenjima, ili imamo objektivni pristup konceptu<br />
vjerojatnosti.<br />
1.2 Koraci u ekonometrijskoj analizi<br />
Ekonometrijska analiza slijedi odre†en put, a to je:<br />
1. Odre†ivanje teorije ili hipoteze<br />
2. Speci…kacija matematiµckog modela<br />
3. Speci…kacija ekonometrijskog modela<br />
4. Prikupljanje podataka<br />
5. Procjena ekonometrijskog modela<br />
6. Testiranje hipoteza<br />
7. Predvi†anje i prognoziranje<br />
1.2.1 Odre†ivanje teorije ili hipoteze<br />
Svoje teorije i hipoteze ekonometrija uglavnom preuzima, kao što smo rekli,<br />
iz ekonomske teorije. Tako je npr., J. M. Keynes rekao da ako se raspoloµziv<br />
dohodak stanovništva poveća, tada će se, uz ostale nepromijenjene uvjete,<br />
povećati potrošnja stanovništva, ali za manje od povećanja raspoloµzivog dohotka.<br />
Ne govori nam ništa u prilog tome koliko će se potrošnja povećati za<br />
jediniµcno povećanje raspoloµzivog dohotka, već nam govori samo o smjeru zavisnog<br />
kretanja tih varijabli i da je graniµcna sklonost potrošnji stanovništva<br />
izme†u 0 i 1.<br />
1.2.2 Speci…kacija matematiµckog modela<br />
Iako je Keynes pretpostavio pozitivnu vezu izme†u potrošnje i raspoloµzivog<br />
dohotka, nije speci…cirao precizni oblik funkcionalne veze izme†u tih<br />
varijabli. Matematiµcka ekonomija sugerira sljedeću funkcionalnu formu:<br />
gdje:<br />
y = potrošnja<br />
x = raspoloµziv dohodak<br />
0 = autonomna potrošnja<br />
1 = graniµcna sklonost potrošnji<br />
y = 0 + 1 x 0 < 1 < 1 (1.1)<br />
2
y<br />
y = β + 1x<br />
0<br />
β<br />
Potrošnja<br />
1<br />
β 1<br />
β 0<br />
Raspoloživ dohodak<br />
x<br />
Slika 1.1: Deterministiµcki model<br />
Jednadµzba (1.1) govori nam da je potrošnja linearno ovisna o dohotku jer<br />
imamo linearnu funkciju (polinom prvog stupnja). To je matematiµcki model<br />
izme†u potrošnje i dohotka koji se u ekonomiji zove funkcija potrošnje.<br />
Općenito modelom zovemo skup matematiµckih jednadµzbi. Jednadµzbe ne<br />
moraju biti linearne već mogu poprimiti razliµcite funkcionalne forme (logaritamske,<br />
eksponencijalne, itd.). U prikazanom sluµcaju model µcini samo jedna<br />
linearna jednadµzba. y i x zovemo varijablama modela. Varijablu x, koja<br />
ne ovisi o drugim varijablama u modelu, zovemo nezavisnom ili egzogenom<br />
varijablom, dok varijablu y, koja u našem sluµcaju ovisi o varijabli x<br />
zovemo zavisnom ili endogenom varijablom. 0 i 1 zovu se parametri<br />
ili koe…cijenti modela. O vrijednostima parametara ovisi izgled funkcije.<br />
0 odre†uje odsjeµcak na ordinati, koji se u ekonomiji interpretira kao autonomna<br />
potrošnja, dok 1 odre†uje nagib ili smjer funkcije, što se u ekonomiji<br />
interpretira kao graniµcna sklonost potrošnji.<br />
1.2.3 Speci…kacija ekonometrijskog modela<br />
Jednadµzba 1.1 prikazuje egzaktnu ili deterministiµcku vezu izme†u varijable<br />
x i varijable y. Me†utim, veze izme†u ekonomskih varijabli uglavnom<br />
nisu egzaktne stoga se pojavljuje potreba za ukljuµcivanjem stohastiµckog elementa<br />
" u matematiµcki model. Ukljuµcivanjem stohastiµckog elementa "<br />
matematiµcki se model 1.1 pretvara u ekonometrijski (stohastiµcki) mo-<br />
3
del:<br />
y = 0 + 1 x + " 0 < 1 < 1: (1.2)<br />
Stohastiµcki element " zovemo i sluµcajno odstupanje, sluµcajna greška<br />
ili rezidual.<br />
y<br />
y = β + 1x<br />
0<br />
β<br />
Potrošnja<br />
+<br />
ε<br />
−<br />
ε<br />
Raspoloživ dohodak<br />
x<br />
Slika 1.2: Ekonometrijski model<br />
Na Slici 1.2 prikazan je ekonometrijski model funkcije potrošnje. Iz Slike<br />
1.2 vidimo da svaku toµcku moµzemo odrediti deterministiµckim dijelom y =<br />
0 + 1 x kojemu dodajemo sluµcajno odstupanje ". Sluµcajno odstupanje<br />
moµze biti pozitivno (iznad pravca) ili negativno (ispod pravca). Sluµcajno<br />
odstupanje preuzima na sebe vrijednosti svih varijabli koje su izostavljene<br />
iz modela, a koje utjeµcu na ponašanje y i greške koje se pojavljuju uslijed<br />
krive funkcionalne forme. Moµzemo reći da se sluµcajna greška " pojavljuje<br />
zbog:<br />
1. Neodre†enosti teorije: ekonomska teorija teµzi pojednostavljivanju stvarnog<br />
svijeta i stoga u teorijske modele ne ulaze sve varijable koje bi<br />
mogle utjecati na y, već samo one koje se smatraju vaµznijima, kako bi<br />
se ekonomski modeli zadrµzali jednostavnima.<br />
2. Nedostupnosti podataka: npr. moµzemo smatrati da na potrošnju pojedinaca<br />
utjeµce, osim njihovog raspoloµzivog dohotka, i njihovo bogatstvo.<br />
Dok je raspoloµziv dohodak dostupna informacija, bogatstvo je<br />
µcesto nedostupan podatak.<br />
4
3. Manje vaµznih varijabli: pretpostavimo da, osim raspoloµzivog dohotka,<br />
na potrošnju utjeµcu i sljedeće varijable: broj djece, spol, vjera,<br />
obrazovanje i zemljopisni poloµzaj. Moguće je pretpostaviti da je njihov<br />
utjecaj na potrošnju slab, nesustavan i stoga sluµcajan. Stoga se iz<br />
praktiµcnih razloga te varijable izostavljaju, a njihov zajedniµcki utjecaj<br />
na zavisnu varijablu y ulazi u sluµcajnu grešku ".<br />
4. Sluµcajnosti koje su svojstvene ljudskom ponašanju: kada bismo i uspjeli<br />
ukljuµciti u model sve relevantne varijable, uvijek postoji u ponašanju<br />
pojedinca odre†ena doza sluµcajnosti koja se ne moµze racionalno<br />
objasniti, ma koliko mi to pokušavali.<br />
5. Loših zamjenskih varijabli: µcesto varijable koje predlaµze ekonomska<br />
teorija nisu neposredno mjerljive. U poznatoj funkciji potrošnje Miltona<br />
Friedmana permanentna potrošnja ovisi o permanentnom dohotku.<br />
Me†utim, niti je permanentni dohodak, niti je permanentna potrošnja<br />
neposredno mjerljiva veliµcina, već se procjenjuju na temelju njihovih<br />
tekućih vrijednosti. U tom sluµcaju moµze doći do greške u njihovoj procjeni.<br />
Ovu će mjernu grešku tako†er na sebe preuzeti sluµcajna greška<br />
".<br />
6. Krive funkcionalne forme: iako smo ispravno u model ukljuµcili relevantne<br />
varijable moguće je da smo pogriješili u odabiru funkcionalne<br />
forme. Npr. pretpostavimo da je umjesto y = 0 + 1 x + " ispravan<br />
model y = 0 + 1 x + 2 x 2 + ". U modelu sa samo dvije varijable lako<br />
je na temelju izgleda dijagrama disperzije odrediti funkcionalnu formu.<br />
Me†utim, u modelima s više nezavisnih varijabli to postaje vrlo teško<br />
jer nije moguće prikazati višestruko dimenzionalni dijagram disperzije.<br />
Greška, koja se pojavljuje uslijed odabira krive funkcionalne forme, ući<br />
će u sluµcajnu grešku ".<br />
1.2.4 Prikupljanje podataka<br />
Parametre 0 i 1 modela 1.2 procjenjuju se na temelju opaµzanja varijabli<br />
x i y koji se dobiju iz statistike. Opaµzanja o varijablama mogu se prikupljati<br />
za vremenska razdoblja, pa govorimo o vremenskim nizovima (eng.<br />
time series). Osim toga mogu se prikupljati za pojedince, grupe pojedinaca,<br />
predmete ili za geografska podruµcja, pa govorimo o podacima vremenskog<br />
presjeka (eng. cross section). Obje se vrste podataka mogu kombinirati<br />
da bi se dobili zdruµzeni podaci vremenskih nizova i vremenskih<br />
presjeka (eng. pooled cross sections).<br />
Vremenski nizovi<br />
Vremenski se nizovi sastoje od opaµzanja jedne ili više varijabli kroz vrijeme.<br />
Takvi se podaci mogu prikupljati dnevno (npr. cijene dionica), tjedno<br />
5
(npr. ponuda novca), mjeseµcno (npr. indeks cijena, stopa nezaposlenosti),<br />
kvartalno (npr. BDP), godišnje (npr. drµzavni proraµcun), desetogodišnje<br />
(npr. popis stanovništva).<br />
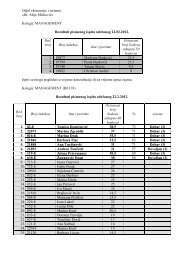
Tablica 1.1: Potrošnja i BDP u Hrvatskoj od 1997. do 2005. godine<br />
Godina<br />
Potrošnja (C)<br />
u milijardama kuna<br />
BDP (Y)<br />
u milijardama kuna<br />
1997. 79.023 123.811<br />
1998. 82.741 137.604<br />
1999. 83.336 141.579<br />
2000. 109.500 152.519<br />
2001. 99.611 165.639<br />
2002. 100.139 181.231<br />
2003. 115.081 198.422<br />
2004. 122.100 212.826<br />
2005. 130.576 229.031<br />
Izvor: International Financial Statistics (IFS), Međunarodni monetarni fond, veljača 2007.<br />
U Tablici 1.1 prikazani su podaci o hrvatskoj potrošnji i BDP-u za razdoblje<br />
od 1997. do 2005. godine na temelju kojih moµzemo izraµcunati hrvatsku<br />
funkciju potrošnje. Vidimo da se radi o dva vremenska niza izraµzena<br />
na godišnjoj frekvenciji. Svi podaci koji ulaze u odre†enu ekonometrijsku<br />
analizu moraju biti izraµzeni u istoj vremenskoj frekvenciji (svi moraju biti<br />
godišnji, kao u gornjem sluµcaju, kvartalni, itd.) Podatke iz viših frekvencija<br />
moµzemo pretvoriti u niµze frekvencije (npr. kvartalne u godišnje)<br />
pomoću prosjeka za varijable koje prikazuju stanja (npr. cijene, kamatnjaci),<br />
ili pomoću zbrajanja za varijable koje prikazuju tokove (npr. BDP,<br />
potrošnja, investicije). S niµzih frekvencija na više frekvencije moguće<br />
je transformirati varijable pomoću statistiµckih metoda interpolacije (za stanja)<br />
i distribucije vrijednosti (za tokove). Vremenske nizove karakteriziraju<br />
trend i sezonska odstupanja (za frekvencije više od godišnjih) a njima<br />
se bavi jedan posebni dio ekonometrije koji se zove Analiza vremenskih<br />
nizova ili Ekonometrija vremenskih nizova. Na slici 1.3 prikazan je<br />
hrvatski BDP izraµzen u kvartalima (tromjeseµcno) gdje se jasno vidi da u<br />
promatranom razdoblju BDP ima znaµcajan trend rasta i velika sezonska odstupanja;<br />
BDP je najveći u 3. kvartalu a najmanji u 1. kvartalu 1 . Drugim<br />
rijeµcima, vremenski nizovi µcesto nisu stacionarni procesi 2 , a stacionarnost<br />
je jedna od pretpostavki na kojima leµze ekonometrijski modeli.<br />
1 Jasno se vidi da je 1995. godine "podbacila" sezona uslijed redarstvenih akcija Bljeska<br />
i Oluje.<br />
2 Kaµze se da je vremenski niz stacionaran ako se njegova sredina i varijanca asimptotski<br />
ne mijenjaju tijekom vremena.<br />
6
150<br />
BDP<br />
bazni indeks 2000.= 100<br />
125<br />
100<br />
75<br />
1993 1995 1997 1999 2001 2003 2005<br />
Slika 1.3: Hrvatski kvartalni BDP od 1993:1-2006:3<br />
Vremenski presjeci<br />
Podaci vremenskog presjeka su podaci jedne ili više varijabli prikupljeni u<br />
zadanoj vremenskoj toµcki. Kada bismo na taj naµcin htjeli prikupiti podatke<br />
na temelju kojih bismo mogli procijeniti funkciju potrošnje u Hrvatskoj,<br />
morali bismo prikupiti npr. opaµzanja o dohotku i potrošnji po gradovima ili<br />
µzupanijama.<br />
U Tablici 1.2 prikazan je vremenski presjek (za 2004. g.) potrošnje i<br />
BDP-a za tranzicijske zemlje. Vidimo da se skup opaµzanja u ovom sluµcaju<br />
ne sastoji od razliµcitih godina, već od podataka za razliµcite zemlje za 2004.<br />
godinu. Ako ne bismo imali na raspolaganju podatke za sve zemlje za 2004.<br />
g., mogli bismo koristiti za neke zemlje i podatke iz 2003. ili 2005. godine,<br />
ako smatramo da nije došlo do strukturnih promjena u tim godinama.<br />
Drugim rijeµcima, u analizi vremenskih presjeka moµzemo zanemariti manje<br />
razlike u vremenu prikupljanja podataka. Kao što vremenski nizovi imaju<br />
svoje speci…µcne probleme (stacionarnost), tako i vremenski presjeci imaju<br />
svoje speci…µcne probleme, me†u kojima je najznaµcajniji heterogenost podataka.<br />
Dijagramom disperzije na slici 1.4 prikazan je odnos izme†u BDP-a i potrošnje<br />
u tranzicijskim zemljama. Imamo male zemlje s malim BDP-om kao<br />
što su Makedonija, Bugarska, Hrvatska, Slovenija i Slovaµcka, zemlje sa sred-<br />
7
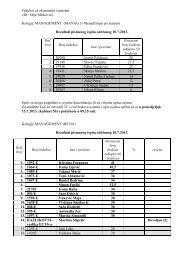
Tablica 1.2: Potrošnja i BDP 2004. godine u tranzicijskim zemljama<br />
Zemlja<br />
Potrošnja (C)<br />
u milijardama US $<br />
BDP (Y)<br />
u milijardama US $<br />
Bugarska 16.518 24.225<br />
Hrvatska 20.249 35.295<br />
Češka 54.818 108.212<br />
Mađarska 68.572 102.157<br />
Makedonija 4.182 5.368<br />
Poljska 161.921 252.254<br />
Rumunjska 51.277 75.574<br />
Slovačka 23.833 42.011<br />
Slovenija 17.874 32.601<br />
Izvor: International Financial Statistics (IFS), Međunarodni monetarni fond, veljača 2007.<br />
njim BDP-om kao Rumunjska, µCeška i Ma†arska, i na kraju imamo Poljsku<br />
koja znatno odskaµce po svojoj veliµcini. U tom sluµcaju, imamo heterogene<br />
podatke i zato moramo voditi raµcuna o tzv. efektu razmjera ili efektu<br />
opsega.<br />
Zdruµzeni podaci i panel (uzduµzni) podaci<br />
Ako kombiniramo vremenske nizove s vremenskim presjecima dobijemo zdru-<br />
µzene podatke.<br />
Posebna vrsta zdruµzenih podataka, u kojima se kroz razliµcite vremenske<br />
toµcke pojavljuju iste vremenski presjeµcne jedinice (iste obitelji, iste zemlje,<br />
itd.), zovu se panel ili uzduµzni (longitudinalni) podaci. Tablica 1.3 prikazuje<br />
uzduµzne podatke o potrošnji i BDP-u za tranzicijske zemlje. U tom<br />
sluµcaju imamo za svaku vremenski presjeµcnu jedinicu (zemlju) niz vremenskih<br />
toµcaka (od 1997. do 2005. godine). Ako gledamo tablicu kroz njezine<br />
retke, vidimo vremenski presjek, ali ako je gledamo kroz stupce, vidimo vremenski<br />
niz. Znaµci, uzduµzni podaci su kombinacija vremenskih presjeka i<br />
vremenskih nizova za iste vremenski presjeµcne jedinice.<br />
Pretpostavimo, me†utim, da se u dvije razliµcite godine (2000. i 2005.)<br />
istraµzivala funkcija potrošnje hrvatskih obitelji s pitanjima o njihovim dohocima<br />
i potrošnji. Kada bismo ukljuµcili samo opaµzanja iz 2000. godine, ili<br />
samo opaµzanja iz 2005. godine, radilo bi se o vremenskom presjeku. Me†utim,<br />
kako bi se povećao broj opaµzanja moµzemo zdruµziti podatke iz 2000. i<br />
2005. godine i tako dobiti zdruµzene podatke iz obje godine. Budući da su<br />
se obitelji za istraµzivanje birale sluµcajno, vrlo je mala vjerojatnost da je ista<br />
obitelj sudjelovala u istraµzivanju 2000. i 2005. godine. Stoga za razliµcite vremenske<br />
toµcke imamo razliµcite vremenski presjeµcne jedinice (obitelji). U tom<br />
sluµcaju ne govorimo o uzduµznim (panel) podacima nego samo o zdruµzenim<br />
(pooled) podacima.<br />
8
Slika 1.4: Odnos BDP-a i potrošnje u tranzicijskim zemljama 2004. godine.<br />
1.2.5 Procjena ekonometrijskog modela<br />
Kada imamo podatke, moµzemo procijeniti parametre funkcije potrošnje 1.2<br />
na temelju vrijednosti prikazanih u Tablici 1.1. Na Slici 1.5 prikazana je<br />
hrvatska funkcija potrošnje za razdoblje od 1997. do 2005. godine.<br />
Pravac koji prolazi kroz toµcke dijagrama disperzije nacrtali smo na naµcin<br />
da minimiziramo sumu kvadrata odstupanja. O toj metodi bit će više rijeµci<br />
u sljedećem poglavlju. Dobiveni koe…cijenti prikazanog pravca su:<br />
by = 21:42 + 0:47x: (1.3)<br />
Kapica nad y oznaµcava da se radi o procijenjenoj vrijednosti (prikazanoj<br />
pravcem) stvarne zavisne varijable y (prikazana toµckama). Iz procijenjene<br />
funkcije potrošnje prikazane u jednadµzbi 1.3 vidimo da je koe…cijent<br />
nagiba 0.47, što znaµci da bi u promatranom razdoblju povećanje BDP-a u<br />
Hrvatskoj za 1 kunu povećalo u prosjeku potrošnju stanovništva za 47 lipa.<br />
Iz Slike 1.5 vidimo da smo provukli regresijski pravac kroz dijagram<br />
disperzije. Kada se, me†utim, priµca o linearnoj regresiji, ne misli se na<br />
linearnost u varijablama, već na linearnost u parametrima. Mogli smo<br />
kroz toµcke dijagrama disperzije povući i neki drugi oblik funkcije, kao npr.<br />
9
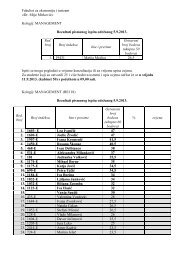
Tablica 1.3: Potrošnja i BDP u tranzicijskim zemljama u razdoblju od 1997.<br />
do 2005. g. (u milijardama US dolara)<br />
Godina<br />
1997. 1998. 1999. 2000. 2001. 2002. 2003. 2004. 2005.<br />
Bugarska<br />
C 7.57 8.60 9.22 8.73 9.47 10.69 13.73 16.52 18.71<br />
Y 10.38 12.74 12.93 12.62 13.63 15.55 19.97 24.22 26.72<br />
Hrvatska<br />
C 12.83 13.01 11.72 13.22 11.94 13.60 17.18 20.25 21.95<br />
Y 20.10 21.64 19.91 18.42 19.86 23.03 29.62 35.29 38.49<br />
Češka<br />
C 30.72 32.58 31.84 29.77 32.08 38.56 47.23 54.82 61.50<br />
Y 57.13 61.85 60.19 56.71 61.84 75.27 91.35 108.21 123.97<br />
Mađarska<br />
C 28.28 29.37 30.67 30.25 34.22 44.00 57.59 68.57 75.10<br />
Y 45.72 47.05 48.04 47.96 53.32 66.71 84.42 102.16 110.37<br />
C 2.71 2.59 2.56 2.67 2.41 2.92 3.53 4.18<br />
Makedonija Y 3.72 3.58 3.67 3.59 3.44 3.79 4.63 5.37<br />
Poljska<br />
C 98.56 107.86 106.00 109.65 123.65 132.28 141.95 161.92 190.32<br />
Y 157.12 172.67 167.84 171.18 190.51 198.00 216.48 252.25 302.67<br />
Rumunjska<br />
C 26.06 31.81 26.49 25.95 28.10 31.56 39.29 51.28 73.16<br />
Y 35.13 42.00 35.67 37.04 40.13 45.76 59.51 75.57 97.25<br />
Slovačka<br />
C 11.67 12.38 11.72 11.57 12.25 14.20 18.70 23.83 27.21<br />
Y 21.56 22.43 20.60 20.45 21.11 24.52 32.98 42.01 47.43<br />
Slovenija<br />
C 11.45 12.12 12.50 11.08 11.20 12.38 15.66 17.87 18.87<br />
Y 19.72 21.04 21.56 19.31 19.77 22.29 28.07 32.60 34.35<br />
Izvor: International Financial Statistics (IFS), Međunarodni monetarni fond, veljača 2007.<br />
¸<br />
y = 0 + 1 x 2 , ili ln y = 0 + 1 ln x, tj. nelinearan model u varijablama,<br />
me†utim, i dalje govorimo o linearnoj regresiji jer su prikazani modeli linearni<br />
u parametrima. Modeli tipa y = 0 + 2 1x, y = p 0 + 1 x; iako<br />
su linearni u varijablama, nisu linearni u parametrima i stoga govorimo o<br />
nelinearnim (u parametrima) regresijskim modelima.<br />
1.2.6 Testiranje hipoteza<br />
Kao što smo ranije rekli Keynes je oµcekivao da je graniµcna sklonost potrošnji<br />
izme†u 0 i 1. U sluµcaju Hrvatske procijenili smo u jednadµzbi 1.3 da je<br />
graniµcna sklonost potrošnji u Hrvatskoj u promatranom razdoblju bila 0.47.<br />
Kako bismo zakljuµcili da je dobiveni rezultat za Hrvatsku u suglasju sa<br />
Keynesijanskom ekonomskom teorijom, i da se ne radi o sluµcajnosti, moramo<br />
dodatno testirati je li ova vrijednost statistiµcki znaµcajno razliµcita od 0 i<br />
mogućnost da nije veća od 1.<br />
1.2.7 Prognoziranje i predvi†anje<br />
Na temelju jednadµzbe 1.3 moµzemo predvidjeti vrijednosti varijable y za zadane<br />
vrijednosti varijable x. Npr. moµzemo predvidjeti kolika će biti potrošnja<br />
stanovništva u Hrvatskoj ako BDP dosegne vrijednost od 250 milijardi kuna<br />
10
140<br />
130<br />
Potrošnja u milijardama kuna<br />
120<br />
110<br />
100<br />
90<br />
80<br />
70<br />
100 120 140 160 180 200 220 240<br />
BDP u milijardama kuna<br />
Slika 1.5: Hrvatska funkcija potrošnje za razdoblje od 1997. do 2005. godine<br />
na sljedeći naµcin:<br />
by 250 = 21:42 + 0:47(250) = 138:92:<br />
Drugim rijeµcima, na temelju vrijednosti naših parametara prognoziramo<br />
da će potrošnja stanovništva biti 138:92 milijarde kuna, kada će BDP u<br />
Hrvatskoj iznositi 250 milijardi kuna.<br />
1.3 Regresijska funkcija populacije i regresijska funkcija<br />
uzorka<br />
Pretpostavimo da smo iz hipotetiµcke populacije studenata prikupili podatke<br />
o njihovom mjeseµcnom dohotku i o njihovoj mjeseµcnoj potrošnji. Studente<br />
smo podijelili na 10 dohodovnih razreda (od 100 kn do 1000 kn) i u Tablici<br />
1.4 prikazali njihove mjeseµcne potrošnje. Stoga imamo 10 …ksnih vrijednosti<br />
varijable x kojima odgovaraju razliµcite vrijednosti y. Drugim rijeµcima<br />
imamo 10 dohodovnih podpopulacija.<br />
Iz Tablice 1.4 jasno se vidi da se u svakoj dohodovnoj grupi studenti<br />
razliµcito ponašaju (imamo one sklonije štednji i one manje sklone štednji);<br />
tako npr. pojedini studenti koji imaju dohodak 300 kn troše više (250 kn<br />
11
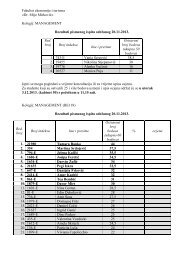
Tablica 1.4: Mjeseµcna potrošnja i dohodak studenata (u kunama)<br />
Dohodak<br />
100 200 300 400 500 600 700 800 900 1000<br />
80 120 190 240 290 350 460 500 600 700<br />
85 145 200 260 330 410 480 520 620 710<br />
90 150 230 300 365 445 490 540 640 750<br />
95 160 240 310 370 460 500 550 660<br />
100 165 250 330 375 480 510 590 680<br />
180 270 360 390 495 520 620 700<br />
200 410 530 650<br />
430 540 670<br />
560<br />
Ukupno 450 1120 1380 1800 2960 2640 4590 4640 3900 2160<br />
E ( y | x i<br />
) 90 160 230 300 370 440 510 580 650 720<br />
Potrošnja<br />
i 270 kn) nego pojedini studenti koji imaju dohodak 400 kn (240 kn i 260<br />
kn). Moµzemo, me†utim, primijetiti da unatoµc tim varijabilnostima postoji<br />
odre†eno pravilo da u prosjeku studenti koji imaju veći dohodak više i troše.<br />
To se jasno vidi iz aritmetiµckih sredina (ili prosjeka) svake podpopulacije<br />
koje su prikazane u zadnjem retku Tablice 1.4 koje zovemo vrijednostima<br />
uvjetnog oµcekivanja jer su uvjetovane zadanim vrijednostima varijable x.<br />
Uvjetno oµcekivanje oznaµcavamo s E (yjx i ) te µcitamo oµcekivana vrijednost<br />
y za zadanu vrijednost x. Tako npr. oµcekivana potrošnja studenata, koji<br />
imaju dohodak od 200 kn, iznosi 160 kn, dok je kod studenata, koji imaju<br />
800 kn, oµcekivana potrošnja 580 kn.<br />
Uvjetno oµcekivanje razlikuje se od matematiµckog (neuvjetnog) oµcekivanja<br />
E (y) koji prikazuje prosjeµcnu potrošnju svih 64 studenata populacije,<br />
neovisno o njihovom dohodovnom razredu. U našem bi sluµcaju matematiµcko<br />
oµcekivanje bilo E (y) =<br />
450+1120++2160 <br />
64 = 400:625.<br />
Na slici 1.6 prikazan je dijagram disperzije na temelju Tablice 1.4. Spajanjem<br />
svih uvjetnih oµcekivanja za sve …ksne vrijednosti dohotka dobili smo<br />
regresijsku funkciju populacije (RFP) 3 koja u našem sluµcaju poprima<br />
oblik pravca. Sve toµcke kojima prolazi regresijski pravac populacije oznaµcava<br />
oµcekivanu potrošnju odre†enog dohodovnog razreda; tako npr. za razred<br />
200 kn oµcekivana potrošnja je 160 kn, za razred 500 kn oµcekivana potrošnja<br />
je 370 kn, itd. Općenito moµzemo reći da regresijska funkcija populacije predstavlja<br />
sve toµcke uvjetnih oµcekivanja zavisne varijable y za …ksne vrijednosti<br />
nezavisne varijable x.<br />
Na temelju tako de…nirane regresijske funkcije populacije moµzemo odrediti<br />
pojedinaµcnu potrošnju svakog studenta kao odstupanje od uvjetnog oµce-<br />
3 Na slici je oznaµcena sa E (yjx i).<br />
12
y<br />
E ( y | x )<br />
800 i<br />
700<br />
600<br />
500<br />
510<br />
Potrošnja<br />
400<br />
300<br />
370<br />
200<br />
100<br />
160<br />
0<br />
0 100 200 300 400 500 600 700 800 900 1000 1100<br />
Dohodak<br />
x<br />
Slika 1.6: Regresijska funkcija populacije izvedena iz Tablice 1.4<br />
kivanja dohodovnog razreda kojemu pripada<br />
Stvarna potrošnja bit će<br />
" i = y i E (yjx i ) :<br />
y i = E (yjx i ) + " i : (1.4)<br />
Znaµci, potrošnja i tog studenta sastoji se od dva dijela: jedan je deterministiµcki<br />
ili sustavni dio E (yjx i ) kojeg moµzemo predvidjeti na temelju<br />
dohodovnog razreda kojemu student pripada te od " i što predstavlja slu-<br />
µcajno odstupanje ili nesustavni dio. Sluµcajno se odstupanje pojavljuje zbog<br />
utjecaja ostalih varijabli na potrošnju studenata a koje nisu ukljuµcene u model,<br />
kao npr. spol, stanuje li student s roditeljima ili je podstanar, društvo<br />
u kojemu se kreće, navike, itd 4 . Ako pretpostavimo da imamo linearnost<br />
E (yjx i ) u varijabli x i kao na slici 1.6 tada se jednadµzba 1.4 pretvara u<br />
y i = 0 + 1 x i + " i : (1.5)<br />
Naµzalost, u praksi nemamo na raspolaganju cjelokupnu populaciju već<br />
samo uzorak iz te populacije. Stoga je problem, s kojim smo suoµceni, da na<br />
4 Glavni razlozi pojavljivanja sluµcajne greške " i objašnjeni su u naslovu Speci…kacija<br />
ekonometrijskog modela na stranici 4.<br />
13
temelju poznavanja samo vrijednosti uzorka, izvuµcenog iz neke populacije,<br />
moramo procijeniti nama nepoznatu funkciju populacije prikazanu jednadµzbom<br />
1.5. Pretpostavimo da smo iz populacije prikazane u Tablici 1.4 izvukli<br />
jedan sluµcajan uzorak (Uzorak 1) potrošnje studenata za svaku dohodovnu<br />
grupu, prikazan u Tablici 1.5<br />
Tablica 1.5: Sluµcajni uzorci iz Tablice populacije<br />
Dohodak Potrošnja: uzorak 1 Potrošnja: uzorak 2<br />
100 80 95<br />
200 145 200<br />
300 270 240<br />
400 310 330<br />
500 375 390<br />
600 480 460<br />
700 530 500<br />
800 520 550<br />
900 700 640<br />
1000 750 700<br />
Moµzemo primijetiti da za svaku dohodovnu grupu (…ksna vrijednost x)<br />
imamo samo jednu vrijednost potrošnje (y), za razliku od populacije kada<br />
smo za svaku vrijednost x imali više vrijednosti y. Vrijednosti iz Tablice<br />
1.5 (Potrošnja: uzorak 1) prikazali smo na Slici 1.7 i provukli kroz toµcke<br />
regresijsku funkciju uzorka (RFU 1 ) koja u našem sluµcaju poprima izgled<br />
pravca kojeg ćemo oznaµciti<br />
^y i = b 0 + b 1 x i + e i (1.6)<br />
gdje je:<br />
^y i = procjenitelj E (yjx i )<br />
b 0 = procjenitelj 0<br />
b 1 = procjenitelj 1<br />
e i = sluµcajno odstupanje uzorka koje interpretiramo kao procjenitelj " i :<br />
Cilj regresijske funkcije uzorka ^y i = b 0 +b 1 x i +e i je procijeniti nepoznatu<br />
regresijsku funkciju populacije y i = 0 + 1 x i + " i .<br />
Iz naše populacije, prikazane u Tablici 1.4, moµzemo izvući i drugi uzorak<br />
(Uzorak 2 koji je prikazan u Tablici 1.5). Na slici 1.7 vidimo da, iako izvuµceni<br />
iz iste populacije, regresijske funkcije uzoraka (RFU 1 i RFU 2 ) me†usobno<br />
se razlikuju zbog ‡uktuacije populacije oko regresijske funkcije populacije.<br />
Jedino u specijalnom sluµcaju, kada bi se sve toµcke populacije prikazane na<br />
slici 1.6 nalazile na regresijskom pravcu populacije, tada bi regresijski pravci<br />
uzoraka prikazani na slici 1.7 bili potpuno jednaki. Što je veća disperzija<br />
toµcaka oko regresijske funkcije populacije, to je vjerojatnost da su regresijske<br />
funkcije uzoraka me†usobno razliµcitije. Postavlja se, dakle, pitanje<br />
14
800<br />
RFU 1<br />
RFU 2<br />
700<br />
600<br />
500<br />
Potrošnja<br />
400<br />
300<br />
200<br />
100<br />
0<br />
0 100 200 300 400 500 600 700 800 900 1000 1100<br />
Dohodak<br />
Slika 1.7: Regresijske funkcije uzoraka temeljene na populaciji iz Tablice 1.4<br />
jesu li i pod kojim uvjetima regresijske funkcije uzoraka dobri procjenitelji<br />
regresijske funkcije populacije?<br />
Odgovor glasi da će regresijska funkcija uzorka biti dobar procjenitelj<br />
"nevidljive" regresijske funkcije populacije ako vrijede sljedeće pretpostavke<br />
o RFP, koje zovemo i pretpostavkama klasiµcnog linearnog regresijskog<br />
modela:<br />
1. Linearnost u parametrima: već smo rekli da kada govorimo o linearnim<br />
modelima govorimo o linearnosti u parametrima. Neki modeli mogu<br />
izgledati nelinearno u parametrima kao na primjer Cobb-Douglasova<br />
funkcija proizvodnje 5 y = 0 K 1L 2e " (1.7)<br />
koju, me†utim, moµzemo jednostavno linearizirati ako je logaritmiramo<br />
ln y = + 1 ln K + 2 ln L + " (1.8)<br />
gdje je a = ln 0 : Vidimo da je jednadµzba 1.8 nelinearna u varijablama<br />
(zbog logaritama), ali linearna u parametrima. U tom sluµcaju govorimo<br />
da je model prikazan jednadµzbom 1.7 suštinsko linearan model,<br />
5 Napomena: e u jednadµzbi (1.7) odnosi se na bazu prirodnog logaritma a ne na sluµcajno<br />
odstupanje uzorka.<br />
15
jer ga moµzemo odre†enim transformacijama pretvoriti u model linearan<br />
u parametrima. S druge strane, da je Cobb-Douglasova funkcija<br />
bila de…nirana kao<br />
y = 0 K 1L 2<br />
+ "; (1.9)<br />
ne bi je bilo moguće nikakvom transformacijom linearizirati. U tom<br />
sluµcaju govorimo da je model suštinsko nelinearan model i da ne<br />
zadovoljava pretpostavku o linearnosti u parametrima.<br />
2. Nestohastiµcnost varijable x: vrijednosti varijable x …ksirane su u ponovljenom<br />
uzorkovanju, kao na primjeru u Tablici 1.4 kada imamo<br />
razliµcite vrijednosti potrošnje (y) za …ksne (iste) vrijednosti dohotka<br />
(x).<br />
3. Sredina sluµcajne greške " i je jednaka nuli ili simboliµcki E (" i jx i ) = 0.<br />
Budući da regresijska funkcija populacije predstavlja uvjetno matematiµcko<br />
oµcekivanje E (yjx i ), tj. sredinu (prosjek) y za zadani x i , to znaµci<br />
da je zbroj pozitivnih i negativnih odstupanja " i za svaki zadani x i<br />
jednak nuli.<br />
Primjer 1.1 Zbrajanjem odstupanja od uvjetnog matematiµcko oµcekivanja<br />
za dohodovnu grupu 100 kn u Tablici 1.4 dobijemo (80 90) +<br />
(85 90) + + (100 90) = 10 + ( 5) + + 10 = 0. Isto vrijedi<br />
i za sve ostale dohodovne grupe.<br />
4. Homoskedastiµcnost: jednaka varijanca za sva opaµzanja ili simboliµcki<br />
V ar (" i jx i ) = E [" i E (" i jx i )] 2 = 2 :<br />
Razumno bi bilo oµcekivati, u našem hipotetiµckom primjeru, osim da<br />
studenti s većim dohotkom troše apsolutno više u odnosu na studente<br />
s manjim dohotkom, da varijanca odstupanja (rasipanje oko RFP, varijabilnost<br />
potrošnje unutar dohodovne grupe) bude veća za studente s<br />
višim dohocima u odnosu na one koji imaju manji dohodak i stoga manji<br />
"manevarski" prostor za potrošnju. Ako varijanca sluµcajne greške<br />
nije ista za sva opaµzanja, već ovisi o nekoj od nezavisnih varijabli (u<br />
našem sluµcaju raste s rastom dohotka) govorimo o heteroskedastiµcnosti,<br />
koju simboliµcki oznaµcavamo s Var(" i jx i ) = 2 i , gdje nam subskript<br />
i govori da varijanca sluµcajnog odstupanja " i nije konstantna.<br />
5. Odsutnost autokorelacije sluµcajnih odstupanja: za dvije …ksne vrijednosti<br />
x i i x j za (i 6= j), kovarijanca (korelacija) izme†u dva sluµcajna<br />
odstupanja " i i " j za bilo koji (i 6= j) je nula, ili simboliµcki<br />
Cov (" i ; " j jx i ; x j ) = E f[" i E (" i )] jx i g f[" j E (" j )] jx j g = 0:<br />
To znaµci da je odstupanje " sluµcajno, tj. da nema sustavni obrazac<br />
(kao npr. isti predznak s prethodnim opaµzanjem).<br />
16
6. Odsutnost multikolinearnosti: izme†u nezavisnih varijabli (kada ih<br />
imamo više) ne smije postojati savršena linearna veza. Ako postoji<br />
znaµcajna veza izme†u nezavisnih varijabli, vrlo je teško izolirati utjecaj<br />
pojedinih varijabli na zavisnu varijablu y.<br />
7. Kovarijanca izme†u " i i x i je nula, ili simboliµcki<br />
Cov (" i ; x i ) = E [" i E (" i )] [x i E (x i )] = 0:<br />
Kada smo de…nirali RFP u jednadµzbi 1.5 pretpostavili smo da x i "<br />
imaju zasebne utjecaje na y (deterministiµcki i nesustavni dio). Me†utim,<br />
kada bi oni bili me†usobno korelirani, takvi se zasebni utjecaji x<br />
i " na y ne bi mogli pravilno identi…cirati.<br />
8. Broj opaµzanja mora biti veći od broja parametara koji se procjenjuju:<br />
na temelju jednog opaµzanja (jedna toµcka u dvodimenzionalnom prostoru)<br />
ne moµzemo procijeniti pravac na tom prostoru; potrebne su nam<br />
minimalno dvije toµcke da odredimo parametre pravca 0 i 1 , drugim<br />
rijeµcima potrebna su nam barem dva opaµzanja.<br />
9. Varijabilnost vrijednosti x: vrijednosti varijable x ne smiju biti sve<br />
iste. Bolje je ako varijabla x ima veće ‡uktuacije jer se u tom sluµcaju<br />
varijablom x mogu bolje objasniti ‡uktuacije zavisne varijable y.<br />
10. Pravilno speci…ciran regresijski model: kada govorimo o pravilno speci-<br />
…ciranom modelu, govorimo o pravilno speci…ciranoj funkcionalnoj<br />
formi, pravilno speci…ciranim nezavisnim varijablama i pravilno<br />
speci…ciranim pretpostavkama o vjerojatnosti y, x, i ".<br />
17
Poglavlje 2<br />
Parametri modela dobiveni<br />
metodom najmanjih<br />
kvadrata<br />
U prethodnom poglavlju objasnili smo da ako vrijede pretpostavke o RFP-u<br />
mogu se donositi zakljuµcci o regresijskoj funkciji populacije (RFP)<br />
y i = 0 + 1 x i + " i<br />
na temelju regresijske funkcije uzorka (RFU)<br />
^y i = b 0 + b 1 x i + e i :<br />
Postavlja se, me†utim, pitanje kako procijeniti parametre b 0 i b 1 regresijske<br />
funkcije uzorka.<br />
2.1 Procjena parametara<br />
Tablica 2.1: Mjeseµcna potrošnja i dohodak studenata (u kunama)<br />
Student Potrošnja Dohodak<br />
Marko 100 150<br />
Ivan 250 300<br />
Mira 300 500<br />
Maja 210 400<br />
Ana 160 200<br />
Pretpostavimo da smo izabrali jedan reprezentativni uzorak studenata<br />
koji su nam dali podatke o njihovim mjeseµcnim potrošnjama i dohocima.<br />
Prikupljeni podaci prikazani su u Tablici 2.1. Ako vrijednosti iz Tablice<br />
18
350<br />
300<br />
250<br />
Potrošnja<br />
200<br />
150<br />
100<br />
50<br />
0<br />
0 100 200 300 400 500 600<br />
Dohodak<br />
Slika 2.1: Dijagram disperzije mjeseµcnog dohotka i potrošnje studenata (u<br />
kunama)<br />
2.1 prikaµzemo dijagramom disperzije, u kojemu svakom opaµzanju odgovara<br />
jedna toµcka u dvodimenzionalnom prostoru dobijemo Sliku 2.1.<br />
Iz prikazanih toµcaka vidimo da kada se vrijednost dohotka studenata<br />
povećava, povećava se i njihova potrošnja . Me†utim na temelju prikazanih<br />
toµcaka ne moµzemo toµcno kvanti…cirati npr.: koliko će studenti povećati<br />
potrošnju, ako im se dohodak poveća za 100 kn, kolika je vjerojatnost potrošnje<br />
studenta koji ima 450 kn dohotka, kolika je autonomna (koja ne<br />
ovisi o dohotku) potrošnja studenata, itd. Odgovore na ova pitanja moguće<br />
je dobiti ako kroz toµcke dijagrama disperzije provuµcemo odre†enu matematiµcku<br />
funkciju. Na temelju pozicioniranja toµcaka na dijagramu disperzije<br />
prikazanom na Slici 2.1 moµzemo pretpostaviti da je prikladni funkcionalni<br />
oblik regresijske funkcije pravac kojim bismo mogli objasniti vezu izme†u<br />
dohotka i potrošnje studenata. Problem koji se sada nameće je kako odrediti<br />
parametre pravca koji će ga de…nirati. Razumno bi bilo da pravac odredimo<br />
tako da minimiziramo zbroj svih odstupanja (greške), tj. min P e i :<br />
Iz Slike 2.2 vidimo da pravac P1 prolazi bliµze toµckama dijagrama disperzije<br />
od pravca P2. S druge strane ako zbrojimo odstupanja za P1 (-<br />
35+0+60+(-30)+10) vidimo da je rezultat P e i = 5, dok ako zbrojimo<br />
odstupanja za P2 (-180+(-120)+60+50+190) rezultat je P e i = 0. Drugim<br />
rijeµcima po kriteriju minimizacije odstupanja bolji je pravac P2 u odnosu<br />
19
350<br />
300<br />
+10<br />
P1<br />
∑ e i = 5<br />
∑ e 2<br />
= 5825<br />
i<br />
Potrošnja<br />
250<br />
200<br />
150<br />
100<br />
180<br />
35<br />
120<br />
+60<br />
30<br />
+50<br />
+190<br />
P2<br />
∑ e i = 0<br />
2<br />
∑ e i<br />
= 89000<br />
50<br />
0<br />
0 100 200 300 400 500 600<br />
Dohodak<br />
Slika 2.2: Kriterij minimalnih kvadrata odstupanja<br />
na pravac, koji "na oko" izgleda bolji, P1. Zašto? Vrijednosti odstupanja e i<br />
poprimaju pozitivne i negativne vrijednosti tako da se u njihovom zbrajanju<br />
me†usobno poništavaju. Tako u sluµcaju pravca P2, u kojemu su velika<br />
odstupanja, imamo u zbroju veće (potpuno) poništavanje vrijednosti odstupanja<br />
u odnosu na pravac P1, koji ima vidno manja odstupanja, ali koja se u<br />
zbroju ne poništavaju u cijelosti. Poništavanje vrijednosti u zbroju moµzemo<br />
izbjeći tako da kvadriramo vrijednosti e i : Iz Slike 2.2 vidimo da je za pravac<br />
P1 zbroj P e 2 i = ( 35)2 + 0 2 + + 10 2 = 5825 znatno manji u odnosu<br />
na pravac P2 gdje je P e 2 i = (( 180) 2 + ( 120) 2 + + 190 2 ) = 89000.<br />
Ako nam kriterij za vuµcenja pravca kroz toµcke dijagrama disperzije postane<br />
minimizacija P e 2 i ; tada vidimo da pravac, koji "na oko" izgleda bolji,<br />
bolji je i na temelju našeg postavljenog kriterija minimizacije kvadrata<br />
odstupanja koji sprjeµcava poništavanje pozitivnih i negativnih vrijednosti<br />
odstupanja. Metodu, koja se temelji na kriteriju minimizacije kvadrata odstupanja,<br />
zovemo Obiµcnom metodom najmanjih kvadrata (eng. OLS<br />
- Ordinary Least Square).<br />
Kvadriranjem odstupanja, osim što pretvaramo odstupanja u pozitivne<br />
vrijednosti, dajemo veću teµzinu većim (udaljenijim od regresijskog pravca)<br />
odstupanjima u odnosu na manja, budući da su vrijednosti kvadrirane.<br />
Problem se u tom sluµcaju moµze pojaviti u prisutnosti izuzetno udaljenih<br />
20
odstupanja (eng. outliers), µcija prisutnost moµze bitno promijeniti izgled<br />
regresijskog pravca, budući da je metoda najmanjih kvadrata izuzetno osjetljiva<br />
na takve udaljene toµcke. Uobiµcajeno je rješenje tog problema da se<br />
opaµzanja vezana za udaljene toµcke jednostavno izbace iz analize. Pri tome<br />
se me†utim mora pristupiti vrlo paµzljivo jer ponekad te udaljene toµcke u<br />
sebi mogu sadrµzavati bitne informacije o vezi izme†u analiziranih varijabli.<br />
Na temelju kriterija minimizacije kvadrata odstupanja iz Slike 2.2 vidimo<br />
da je pravac P1 bolji od pravca P2. Ali nitko nam ne jamµci da je pravac<br />
P1 najbolji izme†u svih mogućih pravaca koje moµzemo potegnuti kroz dijagram<br />
disperzije po kriteriju minimizacije kvadrata odstupanja. Moramo<br />
li na temelju reµcenoga potegnuti kroz toµcke dijagrama disperzije veliki broj<br />
pravaca i na temelju njihovog zbroja kvadrata odstupanja odluµciti koji je od<br />
njih najbolji, ili drugim rijeµcima koji ima minimalni P e 2 i ? Takav bi pristup<br />
bio sigurno vremenski jako rastrošan i na kraju ne bismo imali konaµcan odgovor,<br />
tj. ne bismo imali nikakvu sigurnost da je našpravac, najbolji me†u<br />
onima koje smo testirali, i najbolji me†u onima koje nismo testirali. Ovaj<br />
problem riješio je njemaµcki matematiµcar Carl Friedrich Gauss na sljedeći<br />
naµcin. Za model s jednom nezavisnom varijablom<br />
y i = b 0 + b 1 x i + e i (2.1)<br />
moramo izabrati parametre b 0 i b 1 tako da minimiziraju P e 2 i : Da bismo<br />
dobili parametri s tim svojstvima moramo parcijalno derivirati izraz P e 2 i<br />
po b 0 i b 1 i izjednaµciti prve derivacije s nulom kako bismo dobili ekstreme<br />
funkcija (minimum).<br />
Kriterij najmanjih kvadrata moµzemo de…nirati kao<br />
nX<br />
nX<br />
Min e 2 i = Min (y i b 0 b 1 x i ) 2 (2.2)<br />
i=1<br />
i=1<br />
gdje y i oznaµcava stvarnu vrijednost y za i-to opaµzanje, a n oznaµcava broj<br />
opaµzanja.<br />
Parcijalnim deriviranjem izraza 2.2 po parametrima b 0 i b 1 i izjednaµcavanjem<br />
prve derivacije s nulom dobivamo jednadµzbe<br />
@<br />
@b 0<br />
P (yi b 0 b 1 x i ) 2 = 2 P (y i b 0 b 1 x i ) = 0 (2.3)<br />
@<br />
@b 1<br />
P (yi b 0 b 1 x i ) 2 = 2 P x i (y i b 0 b 1 x i ) = 0: (2.4)<br />
Simultanim rješavanjem jednadµzbi 2.3 i 2.4 po parametrima b 0 i b 1 (cjeloviti<br />
izvod prikazan je u Dodatku A.1) dobijemo vrijednosti parametara<br />
koje imaju svojstvo minimizacije sume kvadrata odstupanja prikazanih u<br />
jednadµzbi 2.2 koje glase<br />
P P (xi x) (y i y) ~xi ~y i<br />
b 1 = P (xi x) 2 = P ~x<br />
2<br />
(2.5)<br />
i<br />
21
0 = y b 1 x (2.6)<br />
gdje y i x prikazuju sredine uzoraka, a ~x i ~y oznaµcavaju varijable x i y u<br />
njihovoj devijacijskoj formi 1<br />
~x i = x i x ~y = y i y:<br />
Korištenjem Gaussovih jednadµzbi 2.5 i 2.6 moµzemo dobiti parametre<br />
(procjenitelje) modela na temelju obiµcne metode najmanjih kvadrata u slu-<br />
µcaju jedne nezavisne varijable.<br />
Ako imamo više nezavisnih varijabli procjenitelje, temeljene na Gaussovoj<br />
metodi najmanjih kvadrata (OLS), moµzemo jednostavno dobiti korištenjem<br />
matriµcne algebre.<br />
Model sa (k 1) brojem nezavisnih varijabli<br />
y i = b 0 + b 1 x 1i + b 2 x 2i + + b (k 1) x (k 1)i + e i (2.7)<br />
moµzemo prikazati u matriµcnoj formi<br />
y = Xb + e (2.8)<br />
u kojoj<br />
2 3 2<br />
y 1<br />
y 2<br />
y = 6 7<br />
4 . 5 X = 6<br />
4<br />
y n<br />
gdje<br />
3 2<br />
1 x 11 x (k 1)1<br />
1 x 12 x (k 1)2<br />
.<br />
. . ..<br />
7<br />
. 5 b = 6<br />
4<br />
1 x 1n x (k 1)n<br />
3<br />
b 0<br />
b 1 7<br />
.<br />
b k 1<br />
2<br />
5 e = 6<br />
4<br />
3<br />
e 1<br />
e 2<br />
7<br />
. 5<br />
e n<br />
y = n 1 vektor stupac s opaµzanjima zavisne varijable<br />
X = n k matrica s opaµzanjima nezavisnih varijabli<br />
b = k 1 vektor stupac nepoznatih parametara<br />
e = n 1 vektor stupac odstupanja.<br />
Svaki element matrice X ima dva subskripta; prvi se odnosi na varijablu<br />
(stupac), dok se drugi odnosi na opaµzanje (redak). Tako npr. element x 24<br />
oznaµcava µcetvrto opaµzanje varijable x 2 . Interesantno je primijetiti da je prvi<br />
redak u matrici X ispunjen jedinicama. Ovaj redak odraµzava konstantni<br />
µclan koji se veµze za parametar b 0 .<br />
Našje cilj, kao i u sluµcaju sa samo jednom nezavisnom varijablom, minimizirati<br />
sumu kvadrata odstupanja koju u matriµcnoj algebri moµzemo pisati<br />
P<br />
min n e 2 i = min(e 0 e): (2.9)<br />
i=1<br />
1 Neka svojstva devijacijskih formi prikazana su u Dodatku A.1<br />
22
Iz jednadµzbe 2.8 imamo<br />
što sumu kvadrata odstupanja pretvara u<br />
e = y Xb; (2.10)<br />
e 0 e = (y Xb) 0 (y Xb)<br />
= y 0 y b 0 X 0 y y 0 Xb + b 0 X 0 Xb<br />
= y 0 y 2b 0 X 0 y + b 0 X 0 Xb: (2.11)<br />
Zadnji je korak moguć jer su b 0 X 0 y i y 0 Xb me†usobno jednaki skalari.<br />
Minimizirati sumu kvadrata odstupanja po parametrima modela moµzemo<br />
ako deriviramo e 0 e po parametrima i izjednaµcimo prvu derivaciju s nulom<br />
@<br />
@b y0 y 2b 0 X 0 y + b 0 X 0 Xb = 2X 0 y+2X 0 Xb = 0; (2.12)<br />
iz µcega slijedi da<br />
b = X 0 X 1 X 0 y: (2.13)<br />
Za dobivanje jednadµzbe 2.13 nismo koristili nikakve pretpostavke o na-<br />
µcinu na koji se podaci generiraju. Jedino što pretpostavljamo je da postoji<br />
inverzna matrica (X 0 X) 1 , tj. da matrica X 0 X nije singularna matrica,<br />
što podrazumijeva da niti jedan redak (stupac) te matrice ne smije biti<br />
egzaktna linearna kombinacija ostalih redaka, što znaµci da nema<br />
multikolinearnosti (linearne veze izme†u nezavisnih varijabli).<br />
Tablica 2.2: Izraµcun vrijednosti procjenitelja (parametara) na temelju obiµcne<br />
metode najmanjih kvadrata odstupanja<br />
Student yi<br />
x<br />
x~ i<br />
y~i<br />
i x ~<br />
i<br />
y 2<br />
i<br />
x ŷ<br />
i<br />
i ei<br />
e i<br />
Marko 100 150 104 160 16640 25600 126.34 26.34 693.87<br />
Ivan 250 300 46 10 460 100 199.15 50.85 2586.09<br />
Mira 300 500 96 190 18240 36100 296.22 3.78 14.29<br />
Maja 210 400 6 90 540 8100 247.68 37.68 1420.00<br />
Ana 160 200 44 110 4840 12100 150.61 9.39 88.18<br />
∑ 1020 1550 0 0 39800 82000 1020 0 4802.44<br />
Sredina 204 310 204 960.49<br />
Primjer 2.1 Iz jednadµzbi za parametre 2.5 i 2.6 i Tablice 2.2 moµzemo izraµcunati:<br />
P ~xi ~y i<br />
b 1 = P ~x<br />
2<br />
= 39800 = 0:48537 (2.14)<br />
i<br />
82000<br />
b 0 = y b 1 x = 204 0:48537 310 = 53: 535: (2.15)<br />
23
Isti smo rezultat mogli dobiti i korištenjem matriµcne forme iz jednadµzbe<br />
2.13 koja vrijedi za broj k nezavisnih varijabli pa stoga vrijedi i za sluµcaj<br />
samo jedne nezavisne varijable, kao u našem primjeru:<br />
gdje su<br />
Ako izraµcunamo 2 da<br />
2<br />
X =<br />
6<br />
4<br />
b = X 0 X 1 X 0 y<br />
1 150<br />
1 300<br />
1 500<br />
1 400<br />
1 200<br />
<br />
X 0 1 1 1 1 1<br />
X =<br />
150 300 500 400 200<br />
i da<br />
1 1 1 1 1<br />
X 0 y =<br />
150 300 500 400 200<br />
u konaµcnici imamo<br />
b = X 0 X <br />
1 X 0 y =<br />
5 1550<br />
1550 562 500<br />
3 2<br />
7<br />
5 ; y = 6<br />
4<br />
2<br />
<br />
6<br />
4<br />
2<br />
<br />
6<br />
4<br />
100<br />
250<br />
300<br />
210<br />
160<br />
1 150<br />
1 300<br />
1 500<br />
1 400<br />
1 200<br />
100<br />
250<br />
300<br />
210<br />
160<br />
3<br />
3<br />
7<br />
5<br />
3<br />
<br />
7<br />
5 =<br />
1020<br />
7<br />
5 = 356 000<br />
1 1020<br />
356 000<br />
5 1550<br />
1550 562 500<br />
<br />
;<br />
<br />
53: 535<br />
=<br />
:<br />
0:485 37<br />
(2.16)<br />
Vidljivo je da smo u 2.16 dobili identiµcni rezultat kao i u jednadµzbama<br />
2.14 i 2.15, tj. da je b 0 = 53:535, a b 1 = 0:48537. Drugim rijeµcima naš<br />
regresijski pravac uzorka (zaokruµzen na dvije decimale) dobiven metodom<br />
najmanjih kvadrata je<br />
^y i = 53:54 + 0:49x i : (2.17)<br />
Iz Tablice 2.2 vidimo da je P e 2 i = 4802:44 ovog pravca manja nego za<br />
pravce iz Slike 2.2. Ne samo to, već znamo da ne postoji pravac, me†u<br />
testiranima i ne testiranima do sada, koji bi imao manju sumu kvadrata<br />
odstupanja. Regresijski pravac iz 2.17 moµzemo gra…µcki prikazati kao na Slici<br />
2.3. Vidimo da za prvo opaµzanje (Marko iz Tablice 2.2) imamo dohodak od<br />
150; stvarnu potrošnju y 1 = 100 i Markovu procijenjenu potrošnju našim<br />
regresijskim pravcem od ^y 1 = 126:34. Stoga odstupanje regresijskog pravca<br />
2 Manipuliranje matricama olakšavaju matriµcno orijentirani raµcunalni paketi kao što su<br />
Matlab ili Scilab<br />
24
od stvarne vrijednosti (greška) u Markovom sluµcaju je (y 1 ^y 1 ) = e 1 =<br />
26:34. Ostale stvarne i procijenjene vrijednosti nisu prikazane na Slici 2.3<br />
nego ih moµzemo naći u Tablici 2.2.<br />
Potrošnja<br />
yˆ = 53.54 + 0. 49<br />
i<br />
x i<br />
ˆ = 274.04 y p<br />
y = 204<br />
yˆ1 =126.34<br />
y 1<br />
=100<br />
e1 = −26.34<br />
53.54<br />
0<br />
x 1<br />
=150<br />
x = 310<br />
x p<br />
= 450<br />
Dohodak<br />
Slika 2.3: Regresijski pravac uzorka<br />
Na temelju ovog dobivenog pravca moµzemo odgovoriti na pitanja na koje<br />
nismo mogli odgovoriti na temelju samo dijagrama disperzije kao što su:<br />
Koliko će studenti povećati potrošnju ako im se dohodak poveća za<br />
100 kn? Prva derivacija potrošnje po dohotku dobivenog pravca je<br />
d^y<br />
dx<br />
= 0:49, što znaµci da je graniµcna sklonost potrošnji reprezentativnog<br />
studenta 0:49, što nam govori da će od dodatne dobivene kune potrošiti<br />
49 lipa, ili ako dobije dodatnih 100 kuna, 49 kuna će potrošiti, a 51<br />
kunu uštedjeti. Gra…µcki 0:49 predstavlja koe…cijent smjera (nagib)<br />
regresijskog pravca na Slici 2.3.<br />
Kolika je vjerojatnost potrošnje studenta koji ima 450 kn dohotka? Iz<br />
našeg pravca imamo<br />
^y 450 = 53:54 + 0:49(450) = 274: 04;<br />
iz µcega moµzemo prognozirati da student koji ima 450 kn dohotka trebao<br />
bi trošiti 274:04 kn, kao što se jasno vidi iz regresijskog pravca na Slici<br />
2.3.<br />
25
Kolika je autonomna (koja ne ovisi o dohotku) potrošnja studenata?<br />
Potrošnja, koja ne ovisi o dohotku, u našem primjeru je 53:54 kn. To<br />
je i minimalna potrošnja našeg reprezentativnog studenta kada nema<br />
dohotka (x = 0; radi se o minimumu jer za dohodak vrijedi uvjet o nenegativnosti).<br />
Gra…µcki, kao što je prikazana na Slici 2.3, ta vrijednost<br />
oznaµcava odsjeµcak na ordinati regresijskog pravca.<br />
2.2 Svojstva regresijskog pravca<br />
Regresijski pravac dobiven metodom najmanjih kvadrata ima sljedeća svojstva:<br />
1. Regresijski pravac prolazi kroz sredinu uzoraka (x i y) kao što<br />
se jasno vidi na Slici 2.3. Ovo svojstvo proizlazi iz jednadµzbe 2.6 za<br />
izraµcunavanje parametra b 0 . Naime, ako je<br />
b 0 = y b 1 x (2.18)<br />
tada vrijedi da je<br />
y = b 0 + b 1 x (2.19)<br />
što nam govori da kada x poprima vrijednost svoje sredine x procijenjena<br />
vrijednost ^y je y: Drugim rijeµcima regresijski pravac prolazi kroz<br />
toµcku (x; y).<br />
Primjer 2.2 Lako moµzemo provjeriti da za x = 310<br />
^y 310 = 53:54 + 0:49(310) = 204 (2.20)<br />
^y poprima vrijednost 3 svoje sredine y = 204, kao što se vidi iz Tablice<br />
2.2.<br />
2. Sredina stvarnog y jednaka je sredini procijenjenog ^y. Svojstvo<br />
y = ^y proizlazi iz 4 ^y i = b 0 + b 1 x i<br />
= (y b 1 x) + b 1 x i<br />
= y + b 1 (x i x) : (2.21)<br />
Zbrajanjem lijeve i desne strane jednadµzbe 2.21 dobijemo<br />
P ^yi = ny + b 1<br />
P (xi x) : (2.22)<br />
3 Mala se greška pojavljuje u ovome izraµcunu uslijed zaokruµzivanja na dvije decimale.<br />
4 Napomena: ovo svojstvo vrijedi samo ako regresija ima konstantni µclan b 0, jer bez<br />
konstantnog µclana, kao što se jasno vidi iz izvoda, ne moµze se izvesti jednadµzba 2.21.<br />
26
Iz<br />
P<br />
Svojstva B.4 operatora zbrajanja (vidi Dodatak B.1) znamo da<br />
(xi x) = 0; što 2.22 pretvara u<br />
P ^yi = ny: (2.23)<br />
Ako lijevu i desnu stranu jednadµzbe 2.23 podijelimo s n; dobijemo<br />
P ^yi<br />
= ny<br />
n n<br />
^y = y: (2.24)<br />
Primjer 2.3 Iz Tablice 2.2 vidimo da je sredina stvarnog y = 204<br />
jednaka sredini procijenjenog ^y = 204.<br />
3. Suma odstupanja je nula 5 ( P e i = 0), što se jasno vidi iz Tablice<br />
2.2. Ovo svojstvo proizlazi iz uvjeta minimizacije kvadrata odstupanja<br />
po b 0 prikazanog u jednadµzbi 2.3<br />
@ P (yi b 0 b 1 x i ) 2 = 2 P (y i b 0 b 1 x i ) = 2 P e i = 0<br />
@b 0<br />
(2.25)<br />
što povlaµci P e i = 0: Iz toga proizlazi da je i sredina odstupanja<br />
e =<br />
P<br />
ei<br />
n<br />
= 0: (2.26)<br />
4. Odstupanja e i i procijenjeni ^y i me†usobno su neovisni. Kovarijancu<br />
izme†u e i i ^y i moµzemo izraziti<br />
Cov (^y i ; e i ) = 1 nP<br />
^y i ^y (e i e) (2.27)<br />
n<br />
i=1<br />
Iz Svojstva 3. regresijskog pravca znamo da je e = 0; stoga da<br />
bi<br />
P<br />
izraz 2.27 bio nula (neovisnost izme†u ovih dviju varijabli) tada<br />
^yi ^y e i mora biti jednak nuli, ili ako pišemo u devijacijskoj formi<br />
P e^yi e i = 0: Regresijski pravac za dvije varijable u devijacijskoj<br />
formi moµzemo pisati bez konstantnog µclana<br />
e^yi = b 1 ~x i : (2.28)<br />
Varijable u devijacijskoj formi imaju sredinu nula, stoga regresijski<br />
pravac prolazi kroz ishodište (vidi Svojstvo 1. regresijskog pravca),<br />
iz µcega proizlazi da je odsjeµcak na ordinati tog pravca jednak nuli, ili<br />
drugim rijeµcima b 0 = 0: Na temelju jednadµzbe 2.28 moµzemo pisati<br />
P P e^yi e i = b 1 ~xi e i<br />
= b 1<br />
P ~xi (~y b 1 ~x i )<br />
= b 1<br />
P ~xi ~y b 2 1<br />
P ~x<br />
2<br />
i : (2.29)<br />
5 Napomena: ovo svojstvo ne vrijedi kada nemamo konstantnog µclana b 0 u regresiji.<br />
27
Na temelju jednadµzbe 2.5 moµzemo pisati<br />
P ~xi ~y = b 1<br />
P ~x<br />
2<br />
i (2.30)<br />
što 2.29 pretvara u<br />
P e^yi e i = b 2 P<br />
1 ~x<br />
2<br />
i b 2 P<br />
1 ~x<br />
2<br />
i<br />
= 0: (2.31)<br />
Na ovaj smo naµcin dokazali da ne postoji linearna veza izme†u odstupanja<br />
i procijenjene zavisne varijable. U našem primjeru iz Tablice 2.2<br />
lako se moµze provjeriti da vrijedi P ^y i ^y e i = 0.<br />
5. Odstupanja e i i x i me†usobno su neovisni, drugim rijeµcima P x i e i =<br />
0. Ovaj zakljuµcak proizlazi iz uvjeta minimizacije kvadrata odstupanja<br />
po b 1 prikazanog u jednadµzbi 2.4<br />
@ P (yi b 0 b 1 x i ) 2 = 2 P x i (y i b 0 b 1 x i ) = 2 P x i e i = 0<br />
@b 1<br />
(2.32)<br />
što povlaµci P x i e i = 0. Ovo svojstvo regresijskog pravca, tako†er se<br />
moµze lako provjeriti na primjeru iz Tablice 2.2.<br />
2.3 Svojstva procjenitelja<br />
Ako vrijede pretpostavke o regresijskoj funkciji populacije koje smo<br />
naveli na stranici 15 tada procjenitelji dobiveni metodom najmanjih kvadrata<br />
imaju odre†ena poµzeljna svojstva navedena u Gauss-Markovljevom<br />
teoremu:<br />
Gauss-Markovljev teorem: Ako vrijede pretpostavke klasiµcnog<br />
linearnog regresijskog modela, procjenitelji dobiveni metodom<br />
najmanjih kvadrata najbolji (naje…kasniji) su linearni nepristrani<br />
procjenitelji, tj. imaju minimalnu varijancu u klasi linearnih<br />
nepristranih procjenitelja.<br />
1. Linearnost: znaµci da je procjenitelj linearna funkcija sluµcajne varijable<br />
jer se moµze napisati kao linearna kombinacija pojedinih opaµzanja<br />
y.<br />
Primjer 2.4 Iz Tablice 2.2 moµzemo dobiti vektor b iz<br />
=<br />
<br />
33<br />
41<br />
2<br />
1025<br />
39<br />
164<br />
1<br />
8200<br />
b = X 0 X 1 X 0 y<br />
85<br />
164<br />
19<br />
8200<br />
23<br />
164<br />
9<br />
8200<br />
101<br />
164<br />
11<br />
8200<br />
2<br />
<br />
6<br />
4<br />
100<br />
250<br />
300<br />
210<br />
160<br />
3<br />
7<br />
5<br />
28
ili b 0 moµzemo dobiti iz linearne kombinacije 33 39<br />
41100+ 164 250 85<br />
164 300<br />
23 101<br />
164210 +<br />
164160 = 53: 537. Na sliµcan naµcin moµzemo dobiti vrijednost<br />
b 1 iz linearne kombinacije elemenata vektora y s drugim redom matrice<br />
(X 0 X) 1 X 0 .<br />
Stoga su procjenitelji dobiveni na taj naµcin, linearna kombinacija vrijednosti<br />
zavisne varijable y pa ih zovemo linearnim procjeniteljima.<br />
2. Nepristranost: znaµci da u ponovljenom uzorkovanju moµzemo oµcekivati<br />
da je procjenitelj u prosjeku jednak stvarnom populacijskom<br />
procjenitelju , što moµzemo pisati<br />
E(b) = : (2.33)<br />
Na slici 2.4 moµzemo vidjeti dvije distribucije dobivene ponovljenim<br />
Distribucija frekvencija<br />
Nepristrana<br />
Pristrana<br />
β<br />
E(b)=β<br />
E(b)≠β<br />
Slika 2.4: Nepristranost i pristranost procjenitelja<br />
E(b)=β<br />
uzorkovanjem iz iste populacije.<br />
Propozicija 2.1 Procjenitelj dobiven pomoću metode najmanjih kvadrata<br />
je nepristran, ili sredina distribucije bit će E(b) = .<br />
29
Dokaz.<br />
h<br />
E (b) = E X 0 X i h<br />
1 X 0 y = E X 0 X i<br />
1 X 0 (X + ")<br />
h<br />
= E X 0 X 1 X 0 X + X 0 X i h<br />
1 X 0 " = E I+ X 0 X i<br />
1 X 0 "<br />
h<br />
= + E X 0 X i<br />
1 X 0 " = : (2.34)<br />
Zadnji korak slijedi iz<br />
h<br />
E X 0 X i<br />
1 X 0 "<br />
h<br />
= E<br />
zato jer su X i " nezavisni i E ["] = 0.<br />
X 0 X 1 X<br />
0 i E ["] = 0 (2.35)<br />
Interesantno je primijetiti da u tom dokazu nismo koristili pretpostavke<br />
da nema autokorelacije i heteroskedastiµcnosti. To ukazuje da procjenitelji<br />
dobiveni metodom najmanjih kvadrata i u sluµcaju postojanja<br />
heteroskedastiµcnosti i autokorelacije reziduala su nepristrani<br />
sve dok sluµcajna greška ima sredinu nula i dok je neovisna od egzogenih<br />
varijabli. Izraz (X 0 X) 1 X 0 " iz jednadµzbe 2.34 moµzemo gledati<br />
kao regresija " na X. To ukazuje da će procjenitelji biti nepristrani,<br />
i u sluµcaju da smo zanemarili unijeti u model neku nedostajuću<br />
varijablu, sve dok je ta varijabla neovisna o ostalim X i ima sredinu<br />
0. Znaµci, pristranost procjenitelja, uslijed nedostajuće objasnidbene<br />
varijable, imat ćemo samo u sluµcaju ako je ona zavisna o drugim nezavisnim<br />
varijablama i ako ima sredinu razliµcitu od nule. Procjenitelj<br />
dobiven metodom najmanjih kvadrata normalno je distribuiran<br />
budući da je b linearna funkcija ", a " je normalno distribuiran 6 .<br />
3. E…kasnost: znaµci da procjenitelj dobiven metodom najmanjih kvadrata<br />
ima minimalnu varijancu izme†u svih linearnih procjenitelja koji<br />
su nepristrani. Na slici 2.5 prikazan je e…kasan i nee…kasan procjenitelj.<br />
Vidimo da su oba procjenitelja nepristrana, me†utim, e…kasan<br />
ima manje odstupanja (minimalno) oko sredine u odnosu na nee…kasnog<br />
procjenitelja. Gauss-Markovljev teorem ne odnosi se na nelinearne<br />
procjenitelje. Nelinearni procjenitelj moµze biti nepristran i<br />
imati manju varijancu u odnosu na procjenitelja dobivenog metodom<br />
najmanjih kvadrata.<br />
4. Konzistentnost: prethodna svojstva procjenitelja odnose se na svojstva<br />
konaµcnih uzoraka. Kada se veliµcina uzorka beskonaµcno poveća<br />
tada procjenitelji imaju odre†ena poµzeljna statistiµcka svojstva. Ta se<br />
svojstva zovu svojstva velikih uzoraka ili asimptotska svojstva.<br />
Konzistentnost je jedno takvo poµzeljno svojstvo, koje ima procjenitelj<br />
dobiven metodom najmanjih kvadrata. Kaµzemo da je procjenitelj<br />
konzistentan kada procjenitelj b povećanjem uzorka konvergira<br />
6 Vidi o tome više na stranici 42.<br />
30
Distribucija frekvencija<br />
Efikasan<br />
Neefikasan<br />
E(b)=β<br />
Slika 2.5: E…kasan i nee…kasan procjenitelj<br />
stvarnoj vrijednosti . Drugim rijeµcima kada je uzorak jako velik,<br />
vjerojatnost da je b razliµcit od veoma je mala ili formalno<br />
lim Pr fjb j > g = 0 za sve > 0 (2.36)<br />
n!1<br />
što znaµci, asimptotski gledano, da je vjerojatnost da procjenitelj, dobiven<br />
metodom najmanjih kvadrata, odstupa više od proizvoljne pozitivne<br />
vrijednosti od stvarnog parametra jednaka nuli. U tom sluµcaju<br />
kaµzemo da limes vjerojatnosti b je i pišemo<br />
plim b = : (2.37)<br />
µCesto se ne moµze dokazati da je neki procjenitelj nepristran; moguće je<br />
da u odre†enim nelinearnim i dinamiµckim modelima nepristran procjenitelj<br />
uopće ne postoji. U tim sluµcajevima konzistentnost je minimalni<br />
uvjet, koji se postavlja pred procjenitelja, kako bi bio koristan. Stoga<br />
su ekonometriµcari µcesto više zabrinuti konzistentnošću procjenitelja<br />
nego li njihovom (ne)pristranošću.<br />
31
Poglavlje 3<br />
Pokazatelji kvalitete regresije<br />
y<br />
y<br />
yˆ = 20 + 0. 8x<br />
yˆ = 20 + 0. 8x<br />
Nakon što smo procijenili parametre modela postavlja se pitanje koliko dobro<br />
tako dobiveni regresijski pravac pristaje opaµzanjima? Na slici 3.1 prika-<br />
0 x 0<br />
a) b)<br />
x<br />
Slika 3.1: Pristajanje regresijskog pravca opaµzanjima<br />
zana su dva istovjetna regresijska pravca uzorka izvuµcena iz dvije razliµcite<br />
populacije<br />
^y = 20 + 0:8x:<br />
U sluµcaju 3.1a) toµcke (opaµzanja) se grupiraju vrlo blizu regresijskom pravcu,<br />
dok se u sluµcaju 3.1b) grupiraju daleko od regresijskog pravca. Jasno je da<br />
gore navedeni regresijski pravac bolje pristaje sluµcaju a) nego sluµcaju b).<br />
32
3.1 Koe…cijent determinacije<br />
Uobiµcajen pokazatelj pristajanja regresijskog pravca nekim opaµzanjima je<br />
koe…cijent determinacije kojeg ćemo oznaµciti sa R 2 . Koe…cijent determinacije<br />
pokazuje koliko je varijance uzorka y objašnjeno našim modelom<br />
ili matematiµcki koe…cijent determinacije moµzemo de…nirati kao<br />
R 2 =<br />
1<br />
Var (^y)<br />
Var (y) =<br />
n 1<br />
1<br />
n 1<br />
P n<br />
i=i (^y i y) 2 P n<br />
P n<br />
i=i (y i y) 2 = i=i (^y i y) 2<br />
P n<br />
i=i (y i y) 2 (3.1)<br />
gdje 1 P n<br />
n 1 i=i (^y i y) 2 pokazuje "objašnjenu" varijancu y regresijskim pravcem<br />
a n 1<br />
P<br />
n 1 i=i (y i y) 2 "ukupnu" varijancu y. Drugim rijeµcima, nakon<br />
skraćivanja, koe…cijent determinacije regresijskog modela prikazuje dio ukupne<br />
varijance y koju smo objasnili regresijskim modelom.<br />
Na slici 3.2 prikazano 1 je za odre†enu vrijednost x i :<br />
ukupno odstupanje y od njegove sredine (y i<br />
y)<br />
regresijskim pravcem objašnjeno odstupanje y; (^y i<br />
y)<br />
regresijskim pravcem neobjašnjeno odstupanje y; (y i<br />
smo do sada oznaµcavali kao rezidual e i .<br />
^y) kojeg<br />
Propozicija 3.1 Kada je u modelu, dobiven metodom najmanjih kvadrata,<br />
prisutan konstantni µclan b 0 za y i = ^y i + e i vrijedi<br />
Var (y i ) = Var (^y i ) + Var (e i ) :<br />
Dokaz. Stvarnu vrijednost y i moµzemo izraµcunati na temelju zbroja procijenjene<br />
vrijednosti ^y i i sluµcajnog odstupanja e i<br />
Jednadµzbu 3.2 moµzemo pisati u devijacijskoj formi<br />
y i = ^y i + e i : (3.2)<br />
(y i y) = ^y i ^y + (e i e) (3.3)<br />
Iz Svojstva 3. regresijskog pravca, iz jednadµzbe 2.26 znamo da vrijedi<br />
e = 0<br />
1 Napomena: pogrešno bi bilo iz ove slike zakljuµciti da je ukupno odstupanje jednako<br />
zbroju objašnjenog odstupanja i neobjašnjenog odstupanja. Na slici je stvarna vrijednost<br />
postavljena tako da se mogu zornije prikazati te veliµcine, ali uoµcljivo je da kada bi se toµcka<br />
koja prikazuje stvarnu vrijednost y nalazila, recimo, izme†u regresijskog pravca i sredine<br />
y da bi ukupno odstupanje bilo manje od objašnjenog odstupanja.<br />
33
y<br />
( y i<br />
− y)<br />
y i<br />
y<br />
( y − ˆ)<br />
i<br />
y i<br />
( yˆ<br />
i<br />
− y)<br />
ˆ +<br />
yi = b0<br />
b1<br />
x i<br />
0<br />
x i<br />
x<br />
Slika 3.2: Ukupno, objašnjeno i neobjašnjeno odstupanje y od svoje sredine.<br />
a iz Svojstva 2. regresijskog pravca, jednadµzba 2.24 znamo da vrijedi 2<br />
^y = y<br />
Na temelju navedenih svojstava 3.3 moµzemo pisati<br />
(y i y) = (^y i y) + e i :<br />
Ako pre†emo operatorom sume i kvadriramo obje strane jednadµzbe dobijemo<br />
Izraz<br />
nX<br />
(y i y) 2 =<br />
i=1<br />
nX<br />
(^y i y) 2 + 2<br />
i=1<br />
nX<br />
(^y i<br />
i=1<br />
nX<br />
(^y i y) e i +<br />
i=1<br />
y) e i<br />
nX<br />
e 2 i : (3.4)<br />
predstavlja kovarijancu izme†u procijenjenog y i reziduala, što iz Svojstva<br />
4. regresijskog pravca, jednadµzba 2.31 znamo da je 0. Stoga 3.4 moµzemo<br />
pisati<br />
nX<br />
nX<br />
nX<br />
(y i y) 2 = (^y i y) 2 + e 2 i (3.5)<br />
i=1<br />
i=1<br />
2 Napomena: Svojstva 2. i 3. regresijskog pravca dobivena metodom najmanjih kvadrata<br />
ne vrijede kada u modelu nije prisutan konstantni µclan b 0:Vidi izvod tih Svojstava<br />
na stranici 27.<br />
i=1<br />
i=1<br />
34
i kada podijelimo s (n<br />
1) dobijemo<br />
ili<br />
P n<br />
i=1 (y i y) 2<br />
n 1<br />
P n<br />
i=1<br />
=<br />
(^y i y) 2<br />
+<br />
n 1<br />
Var (y i ) = Var (^y i ) + Var (e i )<br />
P n<br />
i=1 e2 i<br />
n 1<br />
µcime smo dokazali Propoziciju 3.1.<br />
Koristeći se ovim svojstvom koe…cijent determinacije moµzemo izvesti tako<br />
da podijelimo cijelu jednadµzbu s Var(y i ) te nakon skraćivanja za (n 1)<br />
dobijemo<br />
P n<br />
i=1<br />
1 =<br />
(^y i y) 2 P n P n<br />
P n<br />
i=1 (y i y) 2 + i=1 e2 i<br />
P n<br />
i=1 (y i y) 2 = R2 i=1<br />
+<br />
e2 i<br />
P n<br />
i=1 (y i y) 2 (3.6)<br />
iz µcega slijedi da je koe…cijent deteminacije R 2 jednak<br />
R 2 = 1<br />
P n<br />
i=1 e2 i<br />
P n<br />
i=1 (y i y) 2 : (3.7)<br />
Iz 3.7 vidimo da su vrijednosti koje R 2 moµze poprimiti izme†u 0 i 1.<br />
Jedino ako su sva odstupanja od regresijskog pravca jednaka nuli e i = 0<br />
tada je R 2 = 1. U tom sluµcaju sva opaµzanja leµze na regresijskom pravcu<br />
i govorimo o deterministiµckom, a ne više o stohastiµckom modelu. Ako je<br />
R 2 = 0 to znaµci da model ne objašnjava kretanje y ništa bolje od sredine<br />
uzorka y. Stoga moµzemo na R 2 gledati kao na pokazatelj koliko regresijski<br />
model bolje opisuje kretanje zavisne varijable u odnosu na trivijalni model<br />
koji sadrµzava samo konstantni µclan.<br />
Budući da R 2 mjeri objašnjenu varijaciju varijable y , on je osjetljiv na<br />
de…niciju te varijable. Na primjer objasniti potrošnju studenata u našem<br />
primjeru razliµcito je od objašnjenja kretanja logaritma potrošnje studenata,<br />
stoga niti koe…cijenti determinacije iz modela, koji imaju kao zavisnu varijablu<br />
potrošnju, nisu usporedivi s koe…cijentima deteminacije koji imaju zavisnu<br />
varijablu ln(potrošnja): Da bi koe…cijenti determinacije bili usporedivi<br />
izme†u razliµcitih modela, ti modeli moraju imati istu zavisnu varijablu.<br />
Budući da koe…cijent determinacije nema u svojem temelju odre†enu<br />
hipotezu koju testiramo, već pokazuje nam samo odnos objašnjene i ukupne<br />
varijance y, nemamo graniµcne vrijednosti na temelju kojih moµzemo zakljuµciti<br />
je li neka pojava dovoljno dobro objašnjena našim modelom. Što je veći<br />
R 2 , znaµci da smo veći dio pojave objasnili, ali teško je odrediti i što je<br />
to "veliki" koe…cijent determinacije. Vrijednost R 2 = 0:5 moµze biti niska<br />
u sluµcajevima kada analiziramo vremenske nizove, dok u sluµcaju analize<br />
vremenskih presjeka moµze biti zadovoljavajuće visoka, budući da je lakše<br />
objasniti agregatnu potrošnju zemlje kroz vrijeme (vremenski niz) u odnosu<br />
na potrošnju pojedinih kućanstava u zemlji (vremenski presjek).<br />
35
Primjer 3.1 Na temelju podataka iz Tablice 2.2 moµzemo izraµcunati koe…-<br />
cijent determinacije<br />
R 2 =<br />
P n<br />
i=i (^y i y) 2<br />
P n<br />
i=i (y i y) 2 = 19317:56 = 0:800 89:<br />
24120:00<br />
Budući da su jednadµzbe 3.1 i 3.7 istovjetne za model procijenjen pomoću<br />
metode najmanjih kvadrata s konstantnim µclanom, R 2 moµzemo dobiti i<br />
pomoću<br />
R 2 = 1<br />
P n<br />
i=1 e2 i<br />
P n<br />
i=1 (y i y) 2 = 1 4802:44<br />
= 0:800 89:<br />
24120:00<br />
Ovaj nam koe…cijent determinacije govori da smo 80% varijacije potrošnje<br />
studenata uspjeli objasniti pomoću kretanja njihovog raspoloµzivog dohotka.<br />
Koe…cijenta determinacije, kao što je de…niran u 3.7 prate tri problema:<br />
1. Ne vrijedi za regresijske modele koji su izraµcunati metodom najmanjih<br />
kvadrata bez konstantnog µclana b 0 : Jednadµzbu 3.7 dobili smo iz<br />
pretpostavki<br />
e = 0 , ^y = y (3.8)<br />
koje ne vrijede kada nemamo konstantni µclan u modelu 3 . U tom slu-<br />
µcaju dobiveni koe…cijent determinacije iz 3.7 nije isti koe…cijentu determinacije<br />
iz 3.1. Kada nemamo konstantni µclan u modelu koristimo<br />
tzv. necentriranim koe…cijentom determinacije koji glasi<br />
necentrirani R 2 =<br />
P n<br />
i=1 ^y2 i<br />
P n<br />
i=1 y2 i<br />
= 1<br />
P n<br />
Pi=1 e2 i<br />
n<br />
i=1 y2 i<br />
: (3.9)<br />
Ovaj se pokazatelj zove necentrirani jer varijable nisu centrirane oko<br />
sredine ili nisu u devijacijskoj formi kao u sluµcaju obiµcnog koe…cijenta<br />
determinacije iz 3.1 koji stavlja u odnos centrirane varijable oko svojih<br />
sredina, pa se stoga µcesto zove i centrirani koe…cijent determinacije.<br />
Za raµcunanje necentriranog koe…cijenta determinacije, budući<br />
da ne koristi devijacijske forme, nije potrebno zadovoljavati svojstva<br />
iz 3.8.<br />
Primjer 3.2 Ako za procjenu potrošnje studenata iz Tablice 2.1 koristimo<br />
model bez konstantnog µclana b 0<br />
^y i = b 1 x i + e i<br />
3 Vidi Svojstvo 2 i 3 regresijskog pravca na stranici 27.<br />
36
centrirani R 2 izraµcunat pomoću jednadµzbe 3.1 je<br />
R 2 =<br />
dok izraµcunat pomoću 3.7 je<br />
P n<br />
i=i (^y i y) 2<br />
P n<br />
i=i (y i y) 2 = 33149:51 = 1: 374 4<br />
24120:00<br />
R 2 = 1<br />
P n<br />
i=1 e2 i<br />
P n<br />
i=1 (y i y) 2 = 1 6891:56<br />
= 0:714 28:<br />
24120:00<br />
Necentrirani R 2 je<br />
îli alternativno<br />
necentrirani R 2 =<br />
P n<br />
i=1 ^y2 i<br />
P n<br />
i=1 y2 i<br />
= 225308:44 = 0:970 32<br />
232200:00<br />
necentrirani R 2 = 1<br />
P n<br />
Pi=1 e2 i<br />
n<br />
i=1 y2 i<br />
= 1<br />
6891:56<br />
= 0:970 32:<br />
232200:00<br />
Iz gonjeg primjera vidimo da su centrirani R 2 ; izraµcunati na temelju<br />
3.1 i 3.7, razliµciti<br />
P n<br />
i=i (^y i y) 2<br />
P n<br />
i=i (y i y) 2 6= 1 P n<br />
i=1 e2 i<br />
P n<br />
i=1 (y i y) 2<br />
i da je R 2 ; izraµcunat na temelju 3.1 veći od 1, što ukazuje da u tom<br />
sluµcaju ne vrijedi Var(y i ) =Var(^y i ) +Var(e i ). Jasno je da je tako izraµcunat<br />
R 2 pogrešno izraµcunat jer nisu zadovoljene pretpostavke iz<br />
3.8. S druge strane iz primjera 3.2 proizlazi da je necentrirani koe…-<br />
cijent determinacije ekvivalentan i kada nemamo konstantnog µclana u<br />
modelu. Odnosno, i dalje vrijedi<br />
P n P n<br />
Pi=1 ^y2 i<br />
n = 1 Pi=1 e2 i<br />
n :<br />
i=1 y2 i<br />
i=1 y2 i<br />
2. Ne vrijedi za regresijske modele koji nisu izraµcunati pomoću metode<br />
najmanjih kvadrata (OLS). Budući da smo koe…cijent determinacije<br />
izraµcunali na temelju Svojstava regresijskog pravca, izvedenog pomoću<br />
metode najmanjih kvadrata, tada, ako koristimo metodu najmanjih<br />
kvadrata, imat ćemo jednakost izme†u 3.1 i 3.7, no ako je regresijski<br />
pravac izraµcunat pomoću neke druge metode tada ta jednakost više<br />
ne vrijedi, stoga i tako izraµcunat R 2 ne vrijedi. Postoji alternativni<br />
naµcin raµcunanja koe…cijenta determinacije R 2 ; koji u sluµcaju metode<br />
najmanjih kvadrata ostaje isti kao u 3.1 i 3.7, a za ostale metode<br />
37
(ne OLS) procjenjivanja regresijskog pravca kreće se uvijek izme†u<br />
vrijednosti 0 i 1. Taj koe…cijent determinacije moµzemo izraµcunati kao<br />
R 2 = corr 2 (y i ; ^y i ) =<br />
P n<br />
i=1 (y i y) ^y i ^y <br />
( P n<br />
i=1 (y i y)) P n<br />
i=1 ^y i ^y ! 2<br />
; (3.10)<br />
tj. izraµcunavamo ga na temelju kvadriranog koe…cijenta korelacije izme†u<br />
stvarnih y i procijenjenih ^y. Ovako de…niran R 2 govori koliko se<br />
dobro mogu varijacije u y objasniti varijacijama u ^y; ili pokazuje jaµcinu<br />
linearne veze izme†u ovih dviju varijabli. Budući da se koe…cijent<br />
korelacije uobiµcajeno oznaµcava s r, zato se koe…cijent determinacije oznaµcava<br />
s R 2 da bi se naglasilo da je koe…cijent determinacije kvadrat<br />
koe…cijenta korelacije.<br />
Primjer 3.3 Na temelju podataka iz Tablice 2.2 imamo<br />
R 2 = corr 2 (y i ; ^y i ) = 0:8949 2 = 0:800 85:<br />
Iz gornjeg primjera proizlazi da je tako izraµcunat koe…cijent determinacije<br />
istovjetan koe…cijentima deteminacije koje smo izraµcunali na<br />
temelju 3.1 i 3.7. Interesantno je primijetiti da u sluµcaju samo jedne<br />
nezavisne varijable, kao u gornjem primjeru, budući da je procijenjeni<br />
^y linearna kombinacija samo x, moµzemo dobiti isti koe…cijent<br />
determinacije ako kvadriramo koe…cijent korelacije izme†u x i y; što<br />
se jasno vidi u sljedećem primjeru.<br />
Primjer 3.4<br />
R 2 = corr 2 (y i ; x i ) = 0:8949 2 = 0:800 85:<br />
3. R 2 nikada ne opada s povećanjem broja nezavisnih varijabli i kada dodatne<br />
varijable ne objašnjavaju kretanje zavisne varijable. Uobiµcajeni<br />
naµcin rješavanja tog problema je ukljuµcivanje u izraµcun koe…cijenta<br />
determinacije stupnjeve slobode, što nam daje tzv. korigirani R 2<br />
kojeg oznaµcavamo s<br />
R 2 = 1<br />
1<br />
P n<br />
(n k) i=1 e2 i<br />
1<br />
(n 1)<br />
P n<br />
i=1 (y i y) 2 : (3.11)<br />
Var(y i ) je neovisna od broja nezavisnih varijabli x, dok P n<br />
i=1 e2 i ovisi<br />
o<br />
P<br />
broju nezavisnih varijabli x, jer što je veći broj x-ova, smanjit će se<br />
n<br />
i=1 e2 i . Da bi se efekt smanjenja sume kvadrata reziduala pri uklju-<br />
µcivanju novih varijabli "kaznio", suma kvadrata reziduala dijeli se sa<br />
38
stupnjevima slobode (n k). U tom se sluµcaju koe…cijent determinacije<br />
ne povećava automatski s povećanjem broja regresora, već ovisi<br />
o tome je li nova varijabla više doprinijela smanjenju P n<br />
i=1 e2 i svojim<br />
ulaskom u model ili više štetila smanjenjem stupnjeva slobode (n k).<br />
Korigirani R 2 je uvijek manji od nekorigiranog R 2 , osim u sluµcaju kada<br />
model ukljuµcuje samo konstantni µclan pa su oba jednaka nuli. U<br />
ekstremnim sluµcajevima korigirani R 2 moµze biti negativan.<br />
Primjer 3.5 Na temelju podataka iz Tablice 2.2 korigirani koe…cijent<br />
determinacije bit će<br />
R 2 = 1<br />
1= (n k) P n<br />
i=1 e2 i<br />
1= (n 1) P n<br />
i=1 (y i y) 2 = 1 1= (5 2) 4802:44<br />
= 0:734 53:<br />
1= (5 1) 24120:00<br />
3.2 Znaµcajnost procjenitelja<br />
3.2.1 Standardna greška procjenitelja<br />
Na temelju jednadµzbe 2.13 procijenili smo vrijednosti parametara populacije<br />
na temelju jednog uzorka iz te populacije. Budući da se podaci mijenjaju<br />
u ovisnosti o uzorku kojeg vuµcemo iz neke populacije, mijenjaju se i parametri<br />
uzorka b kojima procjenjujemo parametre populacije . Postavlja<br />
se stoga pitanje koliko bi me†usobno odstupali parametri razliµcitih uzoraka<br />
s istim brojem opaµzanja koje vuµcemo iz iste populacije, ili koliko moµzemo<br />
biti sigurni da dobiveni parametri na temelju nekog uzorka precizno opisuju<br />
"nevidljive" parametre populacije? Zato što ne znamo stvarne vrijednosti<br />
populacije, zakljuµcke o odstupanjima u populaciji donosimo na temelju<br />
odstupanja u uzorku. Ako uzorak ima velika odstupanja oko regresijske<br />
funkcije, kao na Slici 3.1b); zakljuµcujemo da je taj uzorak izvuµcen iz neke<br />
populacije koja tako†er ima velika odstupanja. Ako su odstupanja velika,<br />
tada se iz populacije mogao izvući jedan drugi uzorak koji ima bitno razliµcite<br />
vrijednosti parametara regresijske funkcije uzorka u odnosu na naš prvo<br />
izvuµceni uzorak. U tom sluµcaju dobiveni parametri iz jednadµzbe 2.13 nisu<br />
pouzdani za opisivanje parametara populacije, ili drugim rijeµcima: ne mo-<br />
µzemo biti sigurni da parametri dobiveni iz uzorka precizno opisuju stvarne<br />
"nevidljive" parametre populacije. S druge strane ako su odstupanja oko<br />
regresijske funkcije uzorka mala, kao na Slici 3.1a), tada pretpostavljamo da<br />
je taj uzorak izvuµcen iz neke populacije koja ima mala odstupanja, i da bi<br />
parametri, koje bismo dobili iz ostalih uzoraka iste veliµcine, izvuµceni iz iste<br />
populacije, bili vrlo sliµcni parametrima regresijskog pravca iz prvog uzorka.<br />
Preciznost (pouzdanost) procjenitelja mjerimo standardnom devijacijom,<br />
koju zovemo i standardnom greškom procjenitelja i raµcunamo<br />
je na temelju varijance procjenitelja. Varijancu procjenitelja moµzemo<br />
izraziti<br />
Var (b) = E (b E [b]) (b E [b]) 0 : (3.12)<br />
39
Na temelju svojstva nepristranosti procjenitelja dobivenih metodom najmanjih<br />
kvadrata imamo<br />
E [b] = (3.13)<br />
što 3.12 pretvara u<br />
2<br />
= 6<br />
4<br />
Var (b) = E (b ) (b ) 0<br />
E [b 1 1 ] 2 3<br />
E [(b 1 1 ) (b 2 2 )] E [(b 1 1 ) (b k k )]<br />
E [(b 2 2 ) (b 1 1 )] E [b 2 2 ] 2 E [(b 2 2 ) (b k k )]<br />
.<br />
.<br />
.<br />
..<br />
7<br />
.<br />
5<br />
E [(b k k ) (b 0 0 )] E [(b k k ) (b 2 2 )] E [b k k ] 2<br />
(3.14)<br />
što moµzemo pisati<br />
2<br />
Var (b 1 ) Cov (b 1 ; b 2 ) Cov (b 1 ; b k )<br />
Cov (b 2 ; b 1 ) Var (b 2 ) Cov (b 2 ; b k )<br />
Var (b) = 6<br />
4<br />
.<br />
.<br />
. .. .<br />
Cov (b k ; b 1 ) Cov (b k ; b 2 ) Var (b k )<br />
3<br />
7<br />
5 : (3.15)<br />
Vidimo da je matrica Var(b) simetriµcna matrica s varijancama parametara<br />
na glavnoj dijagonali i kovarijancama izme†u parametara na pozicijama<br />
izvan glavne dijagonale.<br />
Iz jednadµzbe 2.13 znamo da<br />
iz µcega imamo<br />
b = X 0 X 1 X 0 y = X 0 X 1 X 0 (X + ")<br />
= X 0 X 1 X 0 X + X 0 X 1 X 0 "<br />
= I + X 0 X 1 X 0 "<br />
+ X 0 X 1 X 0 " (3.16)<br />
(b ) = X 0 X 1 X 0 ": (3.17)<br />
Vrijednosti matrice Var(b) moµzemo stoga izraµcunati na temelju<br />
Var (b) = E (b ) (b ) 0<br />
h<br />
= E X 0 X 1 X 0 "" 0 X X 0 X i 1<br />
= X 0 X 1 X<br />
0<br />
2 I n<br />
<br />
X X 0 X 1<br />
= 2 X 0 X 1 X 0 X X 0 X 1<br />
= 2 X 0 X 1 : (3.18)<br />
40
Iz 3.18 poznata nam je vrijednost matrice (X 0 X) 1 . Me†utim skalar 2<br />
predstavlja varijancu regresijskog modela populacije koja nam je nepoznata.<br />
Moµzemo je procijeniti pomoću nepristranog procjenitelja varijance<br />
populacije izraµcunatog iz odstupanja uzorka 4<br />
s 2 =<br />
e0 e<br />
(3.19)<br />
n k<br />
što 3.18 pretvara u<br />
Var (b) =<br />
e0 e<br />
n k X0 X 1 : (3.20)<br />
Standardne devijacije (greške) procjenitelja moµzemo izraµcunati tako da korjenujemo<br />
varijance ili<br />
sd (b) = p Var (b)<br />
r<br />
e<br />
=<br />
0 e<br />
n k (X0 X) 1 : (3.21)<br />
Iz jednadµzbe 3.18 vidimo da što je veća varijanca modela populacije<br />
2 (veća raspršenost oko regresijske funkcije populacije) da je veća i varijanca<br />
procjenitelja Var(b). Znaµci, ako imamo vrlo raspršenu populaciju oko<br />
regresijske funkcije populacije tada i regresijske funkcije uzoraka, koje su<br />
izvedene iz te populacije, mogu se me†usobno jako razlikovati. U sluµcaju<br />
da imamo malu raspršenost populacije oko regresijske funkcije populacije<br />
tada će uzorci izvedeni iz te populacije davati sliµcne vrijednosti parametara<br />
regresijskih funkcija uzoraka.<br />
Budući da ne znamo 2 , nju smo procijenili iz varijance uzorka s 2 (jednadµzba<br />
3.19), pretpostavljajući da ako uzorak ima velika odstupanja oko<br />
regresijske funkcije uzorka da i populacija iz koje je taj uzorak izvuµcen ima<br />
velika odstupanja oko regresijske funkcije populacije.<br />
Primjer 3.6 Na temelju jednadµzbe 3.21 moµzemo izraµcunati Var(b) za parametre<br />
iz primjera 2.1 na sljedeći naµcin:<br />
Var (b) = 4802:44 <br />
1<br />
5 1550<br />
5 2 1550 562 500<br />
= 4802:44 <br />
225 31<br />
164 8200<br />
31 1<br />
3 8200 82 000<br />
<br />
2196: 2 6: 051 9<br />
=<br />
:<br />
6: 051 9 0:01 952 2<br />
Vidimo da je Var(b 0 ) = 2196:2, Var(b 1 ) = 0:019522, te kovarijanca Cov(b 0 ; b 1 ) =<br />
6:0519. Standardna devijacija procjenitelja bit će<br />
sd (b 0 ) = p Var (b 0 ) = p 2196:2 = 46: 864<br />
sd (b 1 ) = p Var (b 1 ) = p 0:019522 = 0:139 72:<br />
4 Dokaz da se radi o nepristranom procijenitelju varijance populacije moµze se naći u [3],<br />
str. 48-49. ili [5], str. 30-31.<br />
41
Do sada nismo imali nikakvu pretpostavku vezanu za oblik distribucije<br />
odstupanja " i , osim što smo pretpostavili da su me†usobno nekorelirani,<br />
neovisni o X, da imaju sredinu nula i konstantnu varijancu. Me†utim da bi<br />
se moglo statistiµcki zakljuµcivati i testirati hipoteze moramo eksplicitno de-<br />
…nirati pretpostavku o distribuciji odstupanja. Uobiµcajena je pretpostavka<br />
da su odstupanja " i normalno distribuirana, tj.<br />
" N 0; 2 I n<br />
<br />
: (3.22)<br />
Drugim rijeµcima, vektor " normalno je distribuiran sa sredinom nula i s<br />
kovarijanµcnom matricom 2 I n . Iz jednadµzbe 3.16 vidimo da su procjenitelji<br />
b linearna funkcija vektora odstupanja " iz µcega slijedi da su procjenitelji<br />
dobiveni metodom najmanjih kvadrata tako†er normalno distribuirani sa<br />
sredinama i kovarijanµcnom matricom 2 (X 0 X) 1 tj.<br />
<br />
b N ; 2 X 0 X 1<br />
(3.23)<br />
iz µcega slijedi da je svaki element vektora b normalno distribuiran ili<br />
<br />
b k N k ; 2 X 0 X <br />
1<br />
(3.24)<br />
kk<br />
gdje (k; k) predstavlja element na glavnoj dijagonali matrice (X 0 X) 1 :<br />
3.2.2 Testiranje hipoteza nad procjeniteljima<br />
Pri statistiµckom testiranju hipoteza moµzemo uµciniti dvije vrste greške: mo-<br />
µzemo odbaciti hipotezu koja je istinita ili moµzemo ne odbaciti hipotezu koja<br />
je kriva. Odbacivanje istinite hipoteze u statistici se zove greška I. tipa,<br />
dok se neodbacivanje krive hipoteze zove greška II. tipa. Vjerojatnost nastanka<br />
greške I. tipa neposredno kontrolira istraµzivaµc proizvoljnim odabirom<br />
razine znaµcajnosti koja se u statistici oznaµcava s : Uobiµcajeno je testirati<br />
na razini znaµcajnosti od 5%, tj. s "ugra†enom" vjerojatnošću greške I.<br />
tipa od 5%. Postavlja se pitanje zašto dodatno ne smanjiti tu vjerojatnost<br />
greške, pa testirati na razini znaµcajnosti od 1% ili manje? Naµzalost na tim<br />
razinama znaµcajnosti dodatno smanjenje vjerojatnosti greške I. tipa drastiµcno<br />
povećava vjerojatnost da se uµcini greška II. tipa (koja se u statistici<br />
uobiµcajeno oznaµcava sa ), tj. da se ne odbaci hipoteza koja je kriva. Vjerojatnost<br />
da se ne uµcini greška II. tipa zove se snaga testa (1 ); odnosno<br />
snaga testa pokazuje sposobnost testa da odbaci krivu hipotezu.<br />
Ekonometrijski paketi pri testiranju razliµcitih hipoteza izraµcunavaju tzv.<br />
p vrijednost (p iz eng. probability) ili toµcnu razinu znaµcajnosti testa<br />
koja prikazuje najmanju razinu znaµcajnosti pri kojoj moµzemo odbaciti H 0 :<br />
Ako je p vrijednost manja od razine znaµcajnosti ; moµzemo odbaciti H 0 .<br />
Ona, tako†er, pokazuje osjetljivost odluke o odbacivanju nul hipoteze u<br />
odnosu na razinu znaµcajnosti. Tako npr. vrijednost p = 0:07 ukazuje da<br />
42
moµzemo odbaciti nul hipotezu na razini znaµcajnosti od 10%, ali ne i na<br />
razini znaµcajnosti od 5%. Kada moµzemo odbaciti H 0 , kaµzemo da su rezultati<br />
statistiµcki znaµcajni, a kada ne moµzemo odbaciti H 0 , kaµzemo da rezultati<br />
nisu statistiµcki znaµcajni.<br />
Za testiranje hipoteza o parametrima (procjeniteljima) modela koristit<br />
ćemo dva testa: t-test za testiranje zasebnih hipoteza i F-test za testiranje<br />
zajedniµckih hipoteza.<br />
t-test<br />
Iz jednadµzbe 3.24 slijedi da varijabla<br />
z =<br />
<br />
b k<br />
k<br />
2 (X 0 X) 1<br />
kk<br />
1=2<br />
(3.25)<br />
ima standardnu normalnu distribuciju, tj. sredinu nula i varijancu 1. Budući<br />
da nam nije poznata varijanca populacije 2 , zamijenit ćemo je procijenjenom<br />
nepristranom varijancom na temelju uzorka iz jednadµzbe 3.19,<br />
s 2 = 1 P<br />
n k e<br />
2<br />
i : Budući da su reziduali uzorka e i normalno distribuirani, njihova<br />
suma kvadrata P e 2 i ima 2 distribuciju 5 . Od tuda sluµcajna varijabla<br />
t k =<br />
<br />
b k<br />
k<br />
s 2 (X 0 X) 1<br />
kk<br />
1=2<br />
(3.26)<br />
predstavlja odnos standardizirane normalne varijable i drugog korijena varijable<br />
s 2 distribucijom. Budući da su ove dvije varijable i me†usobno<br />
nezavisne, tada sluµcajna varijabla t k ima Studentovu t distribuciju s (n k)<br />
stupnjeva slobode 6 . Studentova distribucija sliµcna je normalnoj distribuciji.<br />
Ima nešto deblje krakove u odnosu na normalnu distribuciju kada imamo<br />
mali broj stupnjeva slobode, no povećanjem broja stupnjeva slobode postaju<br />
sliµcnije i za dovoljan velik broj stupnjeva slobode postaju identiµcne.<br />
Slijedom gore reµcenog moµzemo konstruirati t-test kojim moµzemo testirati<br />
hipoteze o parametru populacije k pomoću<br />
k<br />
t k = b k<br />
sd (b k )<br />
(3.27)<br />
koji ima t distribuciju s (n k) stupnjeva slobode. Vidimo da su nam u 3.27<br />
poznate sve veliµcine: parametar uzorka b k , standardna greška parametra<br />
uzorka sd(b k ) i vrijednost parametra populacije koju proizvoljno testiramo<br />
k :5 Vidi Dodatak C.1, teorem C.3.<br />
6 Vidi Dodatak C.1, teorem C.5.<br />
43
Dvostrani t-test Na temelju jednadµzbe 3.27 moµzemo testirati hipotezu<br />
da k poprima vrijednost k , tj. H 0 : k = k nasuprot alternativnoj<br />
hipotezi H 1 : k 6= k . Velika razlika u vrijednostima parametara uzorka b k;<br />
kojeg smo procijenili pomoću metode najmanjih kvadrata i testne veliµcine k<br />
podrazumijeva malu vjerojatnost da su te dvije veliµcine iste. U tom sluµcaju<br />
moµzemo lakše odbaciti H 0 . Nadalje iz brojnika jednadµzbe 3.27 moµzemo<br />
uoµciti da se povećanjem razlike izme†u b k i k testna statistika t k povećava<br />
u apsolutnoj vrijednosti. Stoga moµzemo lako zakljuµciti kako veća vrijednost<br />
jt k j implicira lakše odbacivanje H 0 .<br />
Interesantno je dalje primijetiti da povećanje veliµcine uzorka smanjuje<br />
standardnu grešku procjenitelja. Budući da se standardna greška procjenitelja<br />
nalazi u nazivniku jednadµzbe 3.27 to povećava t vrijednost. Veća t vrijednost<br />
podrazumijeva lakše odbacivanje H 0 što kod velikih uzoraka znatno<br />
smanjuje vjerojatnost greške II. tipa. Kako bi kompenzirali taj efekt, istra-<br />
µzivaµci uobiµcajeno smanjuju vjerojatnost greške I. tipa tako što smanje razinu<br />
znaµcajnosti njihovih testova. To objašnjava zašto je kod velikih uzoraka<br />
opravdano birati razinu znaµcajnosti od 1%, umjesto uobiµcajenih 5%, a kod<br />
vrlo malih uzoraka razinu znaµcajnosti od 10%.<br />
Budući da alternativna hipoteza H 1 : k 6= k dozvoljava vrijednosti<br />
koje su veće ali i manje od k , tada se takav test zove dvostrani test<br />
(testira se na oba kraka distribucije) µcije se kritiµcne vrijednosti t =2;(n k)<br />
de…niraju kao vjerojatnost<br />
Pr jt k j > t =2;(n k) = : (3.28)<br />
Odbacujemo H 0 ako je apsolutna vrijednost jt k j veća od kritiµcne vrijednosti<br />
t =2;(n k) gdje oznaµcava razinu znaµcajnosti a (n k) stupnjeve<br />
slobode.<br />
Primjer 3.7 Pretpostavimo da µzelimo testirati, s razinom znaµcajnosti od<br />
5%; hipotezu da je graniµcna sklonost potrošnji studenata, iz Tablice 2.1,<br />
0:6:Na temelju parametra kojeg smo izraµcunali u primjeru 2.1 i standardne<br />
devijacije koju smo izraµcunali u primjeru 3.6 moµzemo testirati H 0 : 1 = 0:6<br />
nasuprot alternativnoj hipotezi H 1 : 1 6= 0:6 pomoću t-testa na sljedeći<br />
naµcin:<br />
t 1 = b 1 1 0:485 0:6<br />
= = 0:823:<br />
sd (b 1 ) 0:1397<br />
U tablici Studentove distribucije vjerojatnosti E.2, prikazanoj u Dodatku,<br />
moµzemo naći kritiµcnu vrijednost t 0:025;3 = 3:1824: Budući da je u našem<br />
primjeru jt 1 j < t =2;(n k) , tj. 0:823 < 3:1824 zakljuµcujemo da ne moµzemo<br />
odbaciti nul hipotezu H 0 = 0:6 :<br />
Umjesto tablice Studentove distribucije mogli smo koristiti toµcnu razinu<br />
znaµcajnosti testa (p vrijednost) za dvostranu t distribuciju, s 3 stupnja<br />
44
slobode i testnom veliµcinom od 0:823, koju uobiµcajeno izraµcunavaju ekonometrijski<br />
paketi. U našem primjeru ona iznosi p = 0:4707, što nam govori<br />
da ne moµzemo odbaciti nul hipotezu jer vjerojatnost da smo uµcinili grešku<br />
ako odbacimo H 0 = 0:6 je 47:07%; mnogo veća od razine znaµcajnosti od 5%<br />
na kojoj testiramo. Budući da imamo vrlo mali uzorak (n = 5) opravdano<br />
bi bilo testirati na razini znaµcajnosti od 10%. Ali na temelju p vrijednosti<br />
od 47:07% odmah moµzemo zakljuµciti da i na razini od 10% ne moµzemo odbaciti<br />
nul hipotezu. Lako se moµze uoµciti da p vrijednost pokazuje "graniµcnu"<br />
razinu znaµcajnosti testa, ili najmanju razinu znaµcajnosti pri kojoj se moµze<br />
odbaciti nul hipoteza (u našem primjeru nul hipotezu moµzemo odbaciti tek za<br />
razine znaµcajnosti 47:07%). Statistiµcko zakljuµcivanje na temelju p vrijednosti<br />
identiµcno je zakljuµcivanju na temelju tablice Studentove distribucije<br />
vjerojatnosti.<br />
U prethodnom primjeru 3.7 vidjeli smo da rezultati testiranja nisu bili<br />
statistiµcki znaµcajni, ili da nismo mogli odbaciti H 0 = 0:6, što ne znaµci<br />
da automatski prihvaćamo vrijednost testiranog parametra 1 = 0:6 kao<br />
istinitu. U našem smo primjeru mogli testirati cijeli skup razliµcitih hipoteza<br />
koje ne moµzemo odbaciti na razini znaµcajnosti od 5%, kao što su npr.<br />
H 0 : 1 = 0:5; H 0 : 1 = 0:3; H 0 : 1 = 0:75: Bilo bi neozbiljno tvrditi da su<br />
sve te hipoteze istovremeno istinite, ili da ih sve istovremeno prihvaćamo.<br />
Stoga je jedini prikladni zakljuµcak da se gore navedene hipoteze ne mogu<br />
odbaciti. Drugim rijeµcima hipoteze u klasiµcnoj statistici ne prihvaćaju se,<br />
već se odbacuju ili ne odbacuju.<br />
Ekonometrijski paketi uobiµcajeno automatski prikazuju, pokraj vrijednosti<br />
parametara i njihovih standardnih devijacija, t vrijednosti kojima se<br />
testira hipoteza H 0 : k = 0, nasuprot hipotezi H 0 : k 6= 0. Budući da je u<br />
tom sluµcaju k = 0; t-test jednadµzbe 3.27 pretvara se u<br />
k<br />
t k = b k<br />
sd (b k ) = b k 0<br />
sd (b k ) =<br />
b k<br />
sd (b k ) ; (3.29)<br />
kojeg uobiµcajeno zovemo t-omjer. Ako je procijenjeni parametar znaµcajno<br />
razliµcit od 0; tada moµzemo reći da varijabla x k , koja se veµze za taj parametar,<br />
ima znaµcajan utjecaj na zavisnu varijablu y: Drugim rijeµcima, ako moµzemo<br />
odbaciti H 0 : k = 0, tada kaµzemo da je utjecaj varijable x k na y znaµcajan.<br />
Primjer 3.8 Je li utjecaj raspoloµzivog dohotka na potrošnju studenata iz<br />
Tablice 2.1 znaµcajan, moµzemo testirati pomoću<br />
t 1 = b 1<br />
sd (b 1 ) = 0:485 = 3: 472:<br />
0:1397<br />
Toµcna razina znaµcajnost testa iznosi p = 0:04; na temelju koje moµzemo sa<br />
znaµcajnošću od 5 i 10% odbaciti H 0 : 1 = 0: S druge strane, ako odaberemo<br />
razinu testiranja od 1% znaµcajnosti, tada ne moµzemo odbaciti tu istu<br />
45
nul hipotezu. Moµzemo stoga zakljuµciti da je utjecaj raspoloµzivog dohotka na<br />
potrošnju studenata statistiµcki znaµcajan ako testiramo sa znaµcajnošću od 5 i<br />
10%, no ako testiramo sa znaµcajnošću od 1%, ne moµzemo odbaciti hipotezu<br />
da raspoloµziv dohodak studenata ne utjeµce na njihovu potrošnju.<br />
Jednostrani t test Ponekad moramo testirati hipoteze nad parametrima<br />
koje imaju jednostranu alternativnu hipotezu. Ako testiramo hipotezu<br />
H 0 : k k , vidimo da će alternativna hipoteza H 1 : k > k biti jednostrana<br />
budući da uzima u obzir samo vrijednosti koje su veće od k . Ako<br />
razmotrimo jednadµzbu 3.27 vidimo da velika pozitivna razlika brojnika vodi<br />
ka velikoj pozitivnoj t k vrijednosti (standardna greška procjenitelja koja<br />
se nalazi u nazivniku izraza uvijek je pozitivna), a velika negativna razlika<br />
brojnika vodi ka velikoj negativnoj vrijednosti t k . Velika pozitivna razlika<br />
vodi ka odbacivanju H 0 , dok je velika negativna razlika u skladu s nul<br />
hipotezom H 0 : k k i ne vodi ka njezinom odbacivanju. Analogno,<br />
mogli smo konstruirati hipotezu H 0 : k k , sa H 1 : k < k : Kritiµcnu<br />
vrijednost za jednostrani test moµzemo stoga izraziti kao<br />
za H 0 : k k nasuprot H 1 : k > k te<br />
za H 0 : k k nasuprot H 1 : k < k :<br />
Pr t k > t ;(n k) = (3.30)<br />
Pr t k < t ;(n k) = (3.31)<br />
Primjer 3.9 Pretpostavimo da µzelimo testirati, s razinom znaµcajnosti od<br />
5%, hipotezu da je graniµcna sklonost studenata iz Tablice 2.1 jednaka ili<br />
veća od 0:6, ili H 0 : 1 0:6, nasuprot hipotezi H 0 : 1 < 0:6. Na temelju<br />
jednadµzbe 3.27 dobit ćemo<br />
t 1 = b 1 1<br />
sd (b 1 )<br />
=<br />
0:485 0:6<br />
0:1397<br />
= 0:823;<br />
istu vrijednost koju smo dobili u primjeru 3.7 kada smo testirali dvostranim<br />
testom hipotezu H 0 : 1 = 0:6: Kritiµcna vrijednost za jednostrani test 7 s 5%<br />
znaµcajnosti i 3 stupnja slobode iznosi t 0:05;3 = 2:3534, dok je za dvostrani<br />
test iz primjera 3.7 bila t 0:025;3 = 3:1824: Budući da je u našem primjeru<br />
t 1 > t 0:025;3 , tj. 0:823 > 2:3534; na temelju jednadµzbe 3.31 ne moµzemo<br />
odbaciti s 5% znaµcajnosti hipotezu H 0 : 1 0:6: Ekonometrijski paketi uobi-<br />
µcajeno prikazuju p vrijednosti za dvostrane testove, koji su µcešći u praksi.<br />
Ako koristimo za statistiµcko zakljuµcivanje p vrijednosti umjesto tablica Studentove<br />
distribucije za jednostrani t-test, moramo dobivenu p vrijednost za<br />
dvostrani test podijeliti s 2. Tako u našem sluµcaju imamo p=2 = 0:4707=2 =<br />
7 Vidi Dodatak, Tablica E.2<br />
46
0:235 4, što ukazuje da je vjerojatnost da smo pogriješili 23:54%, ako odbacimo<br />
H 0 . Drugim rijeµcima ako testiramo s 5% znaµcajnosti, ne moµzemo<br />
odbaciti hipotezu da je graniµcna sklonost potrošnji studenata iz našeg primjera<br />
jednaka ili veća od 0:6:<br />
Primjer 3.10 Pretpostavimo da µzelimo testirati, sa znaµcajnošću od 5%, hipotezu<br />
da je graniµcna sklonost potrošnji studenata iz Tablice 2.1 jednaka ili<br />
manja od 0:1, ili H 0 : 1 0:1, nasuprot hipotezi H 1 : 1 > 0:1. Na temelju<br />
jednadµzbe 3.27 imamo<br />
t 1 = b 1 1<br />
sd (b 1 )<br />
=<br />
0:485 0:1<br />
0:1397<br />
= 2: 756: (3.32)<br />
Iz Studentove tablice imamo t 0:05;3 = 2:3534. Budući da t 1 > t 0:025;3 ; ili<br />
2:756 > 2:3534 na temelju jednadµzbe 3.30 moµzemo odbaciti H 0 : Do istog<br />
zakljuµcka moµzemo doći koristeći se p vrijednošću koja za ovaj test iznosi<br />
p=2 = 0:070=2 = 0:035 :Drugim rijeµcima vjerojatnost da smo uµcinili grešku<br />
je 3:5%, ako odbacimo nul hipotezu. Zato što je vjerojatnost da smo uµcinili<br />
grešku, kada odbacujemo H 0 , manja od "dopuštene" vjerojatnosti greške od<br />
5%, hipotezu H 0 : 1 0:1 moµzemo odbaciti.<br />
Interval pouzdanosti parametara Interval pouzdanosti parametra mo-<br />
µzemo de…nirati kao raspon svih vrijednosti k za koje se H 0 : k = k ne<br />
moµze odbaciti t-testom. Vjerojatnost da se t statistika na†e izme†u kritiµcnih<br />
t vrijednosti iznosi<br />
Pr t =2;(n k) t k t =2;(n k) = 1 : (3.33)<br />
Supstitucijom jednadµzbe 3.27 u 3.33 dobijemo<br />
<br />
Pr t =2;(n k) b <br />
k k<br />
sd (b k ) t =2;(n k) = 1 : (3.34)<br />
Nakon sre†ivanja po k imamo<br />
Pr b k sd (b k ) t =2;(n k) k b k + sd (b k ) t =2;(n k) = 1 ; (3.35)<br />
ili kompaktno interval pouzdanosti populacijskog parametra k moµzemo<br />
pisati kao<br />
b k sd (b k ) t =2;(n k) : (3.36)<br />
Iz jednadµzbe 3.36 vidimo da interval pouzdanosti izraµcunavamo na temelju<br />
poznatih veliµcina koje smo izvukli iz uzorka te populacije, a to su: parametar<br />
b k i njegova standardna devijacija sd(b k ). Što je veća standardna devijacija<br />
procjenitelja, to će biti širi interval pouzdanosti. Širi interval pouzdanosti<br />
47
znaµci veću neizvjesnost u procjenjivanju populacijskog nepoznatog parametra<br />
k . Stoga se na standardnu grešku procjenitelja gleda kao na mjeru preciznosti<br />
procjenitelja koja nam govori koliko precizno procjenitelj b k opisuje<br />
stvarnu vrijednost populacijskog k .<br />
Populacijski parametar k je nepoznata, ali …ksna vrijednost, zato izraz<br />
3.35 ne moµzemo interpretirati kao "(1 ) je vjerojatnost da se populacijski<br />
parametar k nalazi u granicama b k sd (b k ) t =2;(n k) " jer bi to impliciralo<br />
da je interval pouzdanosti …ksan, a populacijski parametar sluµcajna vrijednost.<br />
Budući da je populacijski parametar k …ksna vrijednost, kada bi<br />
interval pouzdanosti tako†er bio …ksan, vrijednost populacijskog parametra<br />
leµzala bi, ili ne bi leµzala, u …ksnom intervalu pouzdanosti. U tom sluµcaju<br />
imali bismo samo dvije vjerojatnosti: ako leµzi, vjerojatnost je 1 (100%);<br />
ako ne leµzi u intervalu pouzdanosti je 0. Me†utim interval pouzdanosti nije<br />
…ksan već sluµcajan jer ovisi o izvuµcenom uzorku iz populacije. Stoga<br />
jedini pravilan naµcin interpretacije intervala pouzdanosti parametra je da<br />
u ponovljenom uzorkovanju, 100 (1 ) % izraµcunatih sluµcajnih intervala<br />
pouzdanosti, na temelju izvuµcenih uzoraka iz iste populacije, ukljuµcivat će<br />
stvarni populacijski …skni parametar k: Drugim rijeµcima kada bi se iz neke<br />
populacije izvuklo 100 uzoraka i na temelju njih izraµcunalo, koristeći izraz<br />
3.36, 100 sluµcajnih 95 postotnih intervala pouzdanosti za …ksni populacijski<br />
parametar k , u 95 od 100 intervala pouzdanosti našli bismo vrijednost<br />
populacijskog …ksnog parametra k :<br />
Primjer 3.11 Na temelju jednadµzbe 3.36 moµzemo izraµcunati 95 postotne<br />
intervale pouzdanosti za parametre modela izraµcunatih u primjeru 2.1. Da<br />
bismo dobili 95 postotni interval pouzdanosti biramo razinu znaµcajnosti od<br />
= 0:05 jer 100 (1 ) % = 100 (1 0:05) % = 95%: Kritiµcna vrijednost<br />
t =2;(n k) iznosi t 0:025;3 = 3:1824 (vidi Tablica E.2 u Dodatku). Na temelju<br />
izraza 3.36 moµzemo izraµcunati 95 postotni interval pouzdanosti za parametar<br />
0<br />
b 0 sd (b 0 ) t =2;(n k)<br />
= 53: 535 46:864 3:1824<br />
= 53:535 149: 14<br />
što moµzemo pisati<br />
95: 605 0 202:675:<br />
Za parametar 1 95 postotni interval pouzdanosti bit će<br />
što moµzemo pisati<br />
b 1 sd (b 1 ) t =2;(n k)<br />
= 0:48537 0:139 72 3:1824<br />
= 0:48537 0:444 6<br />
0:04077 1 :0:92997:<br />
48
F -test<br />
Na temelju t-testa moµzemo testirati pojedinaµcne hipoteze nad jednim koe…-<br />
cijentom. Postavlja se pitanje kako testirati zajedniµcke hipoteze nad koe…-<br />
cijentima kao što su na primjer<br />
H 0 : 1 = 2 = 0 ili H 0 : 1 + 2 4 = 1:<br />
U tom sluµcaju moµzemo konstruirati ograniµceni model koji će u sebi sadr-<br />
µzavati ograniµcenja nad parametrima i testirati razliku izme†u neobjašnjena<br />
odstupanja ograniµcenog modela i neograniµcenog modela. Kod neograniµcenog<br />
modela ne forsiramo da parametri poprime odre†ene vrijednosti, već<br />
dopuštamo da poprime bilo koju vrijednost koja, u sluµcaju da rabimo metodu<br />
najmanjih kvadrata, minimizira zbroj kvadrata odstupanja. Kod ograniµcenog<br />
modela, s druge strane, forsiramo da odre†eni parametri poprime<br />
a priori zadane vrijednosti koje ne minimiziraju zbroj kvadrata odstupanja.<br />
Jasno je stoga da zbroj kvadrata neobjašnjenih odstupanja bit će uvijek veći<br />
kod ograniµcenog modela u odnosu na neograniµceni model. Nadalje, što se<br />
forsirani parametar u neograniµcenom modelu udaljava svojom vrijednošću<br />
od parametra koji minimizira sumu kvadrata odstupanja (dobiven neograniµcenim<br />
modelom) to će biti veća razlika izme†u sume kvadrata odstupanja<br />
ograniµcenog i neograniµcenog modela. Na taj naµcin prirodno se nameće test<br />
koji uspore†uje zbrojeve kvadrata neobjašnjenih odstupanja ograniµcenog i<br />
neograniµcenog modela. Ako je razlika velika, tada će se nul hipoteza moći<br />
odbaciti, ako je razlika mala, tada se nul hipoteza neće moći odbaciti.<br />
Ako sumu kvadrata odstupanja P (y i ^y i ) 2 oznaµcimo s RSS, tada F test<br />
moµzemo pisati<br />
F = (RSS R RSS UR ) =J<br />
(3.37)<br />
RSS UR = (n k)<br />
gdje RSS R oznaµcava sumu kvadrata odstupanja ograniµcenog modela, RSS UR<br />
sumu kvadrata odstupanja neograniµcenog modela, J broj ograniµcenja i (n k)<br />
stupnjeve slobode neograniµcenog modela. Budući da je RSS R uvijek veći<br />
od RSS UR , gornji izraz uvijek će biti pozitivan.<br />
Ako vrijedi pretpostavka da su odstupanja e i normalno distribuirana,<br />
tada P (y i ^y i ) 2 ; što skraćeno pišemo P e 2 i , iz Teorema8 C.3 ima 2 distribuciju.<br />
Na temelju Teorema C.4 znamo da zbrajanje i oduzimanje varijabli<br />
s 2 distribucijom daju varijablu s 2 distribucijom. Stoga će i razlika<br />
RSS R RSS UR , tako†er, imati 2 distribuciju. Iz Teorema C.6 znamo da<br />
će odnos dviju sluµcajnih varijabli s 2 distribucijom x 1=n 1<br />
x 2 =n 2<br />
imati F distribuciju<br />
s (n 1 ; n 2 ) stupnjeva slobode, ili kao u sluµcaju naše jednadµzbe 3.37 F -test<br />
ima F distribuciju sa (J; n k) stupnjeva slobode. F -test je jednostrani test<br />
µciju kritiµcnu vrijednost F;(n<br />
J k)<br />
moµzemo de…nirati kao<br />
n<br />
o<br />
Pr F > F;(n J k)<br />
= (3.38)<br />
8 Vidi Dodatak C.1<br />
49
gdje predstavlja razinu znaµcajnosti testa. Drugim rijeµcima velika razlika<br />
izme†u RSS R i RSS UR vodit će k velikim vrijednostima F statistike iz<br />
3.37, a velike vrijednosti F statistike vodit će na temelju 3.38 odbacivanju<br />
nul hipotez·e.<br />
Ekonometrijski paketi µcesto automatski pokraj vrijednosti parametara,<br />
standardnih devijacija koe…cijenata, t vrijednosti, koe…cijenata determinacije<br />
itd. prikazuju i rezultate F -testa kojim se za model<br />
testira zajedniµcka hipoteza<br />
y = 0 + 1 x 1 + 2 x 2 + + k 1 x k 1<br />
H 0 : 1 = 2 = = k 1 = 0; (3.39)<br />
odnosno, testira se zajedniµcka hipoteza da su svi parametri, koji se veµzu za<br />
nezavisne varijable, jednaki nula, što znaµci da niti jedna nezavisna varijabla<br />
nije znaµcajna za objašnjenje zavisne varijable y. U tom se sluµcaju ograniµceni<br />
model svodi na trivijalan model koji sadrµzi samo konstantni µclan 0<br />
y = 0 : (3.40)<br />
Iz Propozicije 3.1 znamo da za model s konstantnim µclanom vrijedi<br />
Var (y i ) = Var (^y i ) + Var (e i ) :<br />
Ako pomnoµzimo s (n 1) dobijemo jednadµzbu 3.5<br />
nX<br />
(y i y) 2 =<br />
i=1<br />
nX<br />
(^y i y) 2 +<br />
nX<br />
i=1<br />
i=1<br />
e 2 i<br />
koju moµzemo pojednostavljeno pisati<br />
T SS = ESS + RSS; (3.41)<br />
gdje T SS oznaµcava ukupnu sumu kvadrata odstupanja, ESS objašnjenu<br />
sumu kvadrata odstupanja, a RSS neobjašnjenu sumu kvadrata odstupanja<br />
od sredine uzorka. Budući da u ograniµcenom modelu 3.40 nemamo ni jednu<br />
nezavisnu varijablu, tada će njegova objašnjena suma kvadrata odstupanja<br />
biti ESS R = 0, a iz 3.41 slijedi da za tako ograniµceni model vrijedi<br />
RSS R = T SS: (3.42)<br />
Taj rezultat pretvara F -test, kojim moµzemo testirati hipotezu 3.39, u<br />
F = (RSS R RSS UR ) =J<br />
RSS UR = (n k)<br />
= (T SS RSS UR) = (k 1)<br />
RSS UR = (n k)<br />
50<br />
= ESS UR= (k 1)<br />
RSS UR = (n k)<br />
(3.43)
ili u odnos objašnjene i neobjašnjene varijance neograniµcenog modela.<br />
Broj ograniµcenja J je (k 1), tj. broj parametara koji se procjenjuju<br />
u modelu manje jedan (konstantni µclan koji nije ograniµcen). Interesantno<br />
je primijetiti da ograniµceni model 3.40 ima koe…cijent determinacije (korigirani<br />
kao i nekorigirani) jednak nuli jer je ESS = P (^y i y i ) 2 = 0: Stoga<br />
je testirati nul hipotezu 3.39 ekvivalentno testiranju nul hipoteze da je populacijski<br />
koe…cijent determinacije R 2 = 0: Drugim rijeµcima F -test iz 3.43<br />
moµzemo interpretirati i kao test kojim se testira znaµcajnost koe…cijenta<br />
determinacije R 2 .<br />
Kada imamo skup linearnih ograniµcenja u obliku<br />
r 11 1 + r 12 2 + + r 1k k = q 1<br />
r 21 1 + r 22 2 + + r 2k k = q 2<br />
.<br />
r J1 1 + r J2 2 + + r jk k = q J<br />
zgodno ih je prikazati u kompaktnoj matriµcnoj formi<br />
R = q: (3.44)<br />
Matrica R ima k stupaca koji odgovaraju broju parametara, koji se procjenjuju<br />
i J redaka, koji odgovaraju broju linearnih ograniµcenja nad parametrima.<br />
Broj stupaca mora biti manji od broja redaka (J < k); drugim rijeµcima<br />
moramo imati manje ograniµcenja od procijenjenih parametara. Testiranje<br />
nul hipoteze jednog skupa od J linearnih ograniµcenja moµzemo de…nirati sa<br />
nasuprot alternativnoj hipotezi<br />
H 0 : R q = 0 (3.45)<br />
H 1 : R q 6= 0: (3.46)<br />
Na ovaj naµcin lako moµzemo de…nirati zajedniµcku nul hipotezu koja se<br />
sastoji od mnogih linearnih ograniµcenja kao npr.<br />
putem<br />
R = 4<br />
H 0 : 2 = 2; 3 = 7 ; 4 + 5 6 = 1<br />
2<br />
0 1 0 0 0 0 0<br />
1 0 0 0 0 0 1<br />
0 0 0 1 1 1 0<br />
3<br />
2<br />
5 , q = 4<br />
ili hipotezu 3.39 da su svi parametri u modelu osim konstantnog µclana jednaki<br />
nuli<br />
R = [0 : I k 1 ] ; q = 0:<br />
2<br />
0<br />
1<br />
3<br />
5<br />
51
Za zadane parametre uzorka, dobivene metodom najmanjih kvadrata, mo-<br />
µzemo de…nirati vektor nepodudarnosti (eng. discrepancy vector) s<br />
m = Rb q (3.47)<br />
gdje vektor Rb prikazuje procijenjeno stanje, a q veliµcine koje µzelimo testirati.<br />
Na temelju Waldovog kriterija<br />
W = m 0 Var (m) m (3.48)<br />
nakon supstituiranja varijance populacije 2 procijenjenom varijancom populacije<br />
s 2 , moµzemo dobiti F statistiku 9 za testiranje linearne hipoteze 3.45<br />
h<br />
m<br />
nR<br />
0 s 2 (X 0 X) 1i o 1<br />
R 0 m<br />
F =<br />
J<br />
: (3.49)<br />
F statistika izraµcunata ovim naµcinom, s (J; n k) stupnjeva slobode, istovjetna<br />
je F statistici, koju dobijemo koristeći jednadµzbu 3.37, tj. daju<br />
potpuno isti rezultat. Prednost 3.49 nad 3.37 je relativno jednostavno de…-<br />
niranje skupa linearnih ograniµcenja koja ulaze u nul hipotezu.<br />
Primjer 3.12 Pretpostavimo da µzelimo nad parametrima modela 10<br />
y = 410:81<br />
(162:830)<br />
33:75 x 1+ 3:23 x 2+ 9:71 x 3 31:57 x 4+ 38:39 x 5<br />
(26:134) (0:989) (0:727) (1:162) (10:793)<br />
R 2 UR = 0:9989<br />
RSS UR = 6808:58<br />
ESS UR = 6394831<br />
(3.50)<br />
testirati s 5% znaµcajnosti sljedeće hipoteze:<br />
a)<br />
H 0 : 1 = 2 = 3 = 4 = 5 = 0 (3.51)<br />
drugim rijeµcimaµzelimo testirati zajedniµcku hipotezu da su svi parametri<br />
vezani za nezavisne varijable jednaki nula nasuprot hipotezi H 1 : 1 =<br />
2 = 3 = 4 = 5 6= 0: U našem sluµcaju model iz jednadµzbe 3.50<br />
je neograniµceni model, dok će ograniµceni model, u kojeg ugra†ujemo<br />
nul hipotezu 3.51, biti model samo s konstantnim µclanom, ili u našem<br />
sluµcaju<br />
R<br />
y = 3067:82<br />
R 2 = 0:0000<br />
RSS R = 6401640 : (3.52)<br />
Budući da u ograniµcenom modelu nemamo nezavisnih varijabli, koe…-<br />
cijent determinacije R 2 ; kao i korigirani koe…cijent determinacije R 2<br />
9 Vidi detaljan izvod u [3] str. 96-97.<br />
10 Podaci za ovaj model prikazani su u Dodatku D.1.<br />
52
su nula. Vidimo da RSS R ograniµcenog modela 3.52 znatno je veći od<br />
RSS UR neograniµcenog modela 3.50. Hipotezom smo ograniµcili 5 parametara,<br />
zato je broj ograniµcenja J = 5, i imamo (n k) = (25 6) =<br />
19 stupnjeva slobode. Prema tome F test kojim testiramo nul hipotezu<br />
3.51 bit će<br />
F = (RSS R RSS UR ) =J<br />
RSS UR = (n k)<br />
=<br />
(6401640 6808:58) =5<br />
(6808:58) =19<br />
= 3569: 1:<br />
Kritiµcna vrijednost F distribucije za 5% znaµcajnosti prikazana je u<br />
Dodatku, Tablica E.3, i iznosi F0:05;19 5 = 2:740. Budući da je u našem<br />
sluµcaju F > F;(n<br />
J k)<br />
, moµzemo na razini od 5% znaµcajnosti odbaciti<br />
nul hipotezu 3.51. Na temelju Tablice E.4, iz Dodatka, vidimo da nul<br />
hipotezu moµzemo odbaciti i s 1% znaµcajnosti, tj. s vjerojatnošću da<br />
smo pri odbacivanju hipoteze uµcinili grešku od samo 1%; budući da je<br />
kritiµcna vrijednost F0:01;19 5 = 4:171 manja od testne veliµcine 3569:1.<br />
Kada testiramo hipotezu da su svi parametri vezani za nezavisne varijable<br />
jednaki nula, tada F vrijednost moµzemo dobiti koristeći se i<br />
jednadµzbom 3.43<br />
F = ESS UR= (k 1)<br />
RSS UR = (n k) = 6394831=5<br />
6808:58=19 = 3569:1<br />
u koju ulaze podaci samo neograniµcenog modela. Ekonometrijski paketi<br />
pokraj parametara modela µcesto automatski prikazuju ovu F vrijednost,<br />
kojom se testira hipoteza da su svi parametri modela vezani za nezavisne<br />
varijable jednaki nula (hipoteza 3.51). U matriµcnoj formi gornju<br />
hipotezu moµzemo testirati pomoću Waldovog kriterija ako de…niramo<br />
R = [0 : I 5 ] ; q = 0:<br />
Vidimo da matricom R ne ograniµcavamo samo konstantni µclan (prvi<br />
stupac). Broj ograniµcenja je J = 5 dok je broj parametara k = 6; što<br />
zadovoljava uvjet J < k, pa moµzemo izraµcunati vektor nepodudarnosti<br />
koji će u našem primjeru biti<br />
2<br />
m = Rb q =<br />
6<br />
4<br />
0 1 0 0 0 0<br />
0 0 1 0 0 0<br />
0 0 0 1 0 0<br />
0 0 0 0 1 0<br />
0 0 0 0 0 1<br />
2<br />
3<br />
7<br />
5 6<br />
4<br />
410:81<br />
33:75<br />
3:23<br />
9:71<br />
31:57<br />
38:39<br />
3<br />
7<br />
5<br />
2<br />
6<br />
4<br />
0<br />
0<br />
0<br />
0<br />
0<br />
3 2<br />
7<br />
5 = 6<br />
4<br />
33: 75<br />
3: 23<br />
9: 71<br />
31: 57<br />
38: 39<br />
Vektor nepodudarnosti prikazuje razliku izme†u vrijednosti parametara<br />
uzorka i vrijednosti koje testiramo. Budući da u našem primjeru<br />
testiramo hipotezu da su populacijski parametri vezani za nezavisne<br />
53<br />
3<br />
7<br />
5 :
varijable jednaki nula, vektor nepodudarnosti svodi se na vrijednosti<br />
procijenjenih parametara na temelju uzorka koji su vezani za nezavisne<br />
varijable. Što su veće, u apsolutnoj veliµcini, vrijednosti vektora<br />
nepodudarnosti, lakše će biti odbaciti nul hipotezu. Kada znamo da je<br />
procijenjena varijanca populacije našeg modela s 2 = 358:35; i da je<br />
simetriµcna matrica<br />
2<br />
73:9891 9:4129 0:2885 0:1717 0:2869 1:2070<br />
X 0 X 9:4129 1:9059 0:0182 0:0049 0:0404 0:1452<br />
1 = 0:2885 0:0182 0:0027 0:0019 0:0004 0:0030<br />
6 0:1717 0:0049 0:0019 0:0015 0:0003 0:0014<br />
4 0:2869 0:0404 0:0004 0:0003 0:0038 0:0100<br />
1:2070 0:1452 0:0030 0:0014 0:0100 0:3251<br />
imamo sve elemente za izraµcunavanje F vrijednosti pomoću jednadµzbe<br />
h<br />
m<br />
nR<br />
0 s 2 (X 0 X) 1i o 1<br />
R 0 m<br />
F =<br />
= 3569:1:<br />
J<br />
3<br />
;<br />
7<br />
5<br />
b)<br />
H 0 : 1 = 15 (3.53)<br />
nasuprot H 1 : 1 6= 15. U prethodnom smo poglavlju vidjeli da hipoteze<br />
nad jednim parametrom testiramo t-testom. F -test je općenit,<br />
stoga, osim testiranja nad više parametara, dopušta nam testiranje i<br />
nad jednim parametrom. Obje metode morale bi dovesti do istog zakljuµcka.<br />
Ako gornju hipotezu testiramo pomoću t-testa imamo<br />
t 1 = b 1 1<br />
sd (b 1 )<br />
=<br />
33:75 ( 15)<br />
26:134<br />
= 0:71746<br />
(p=0:4818) :<br />
Ograniµceni model bit će<br />
y = 0 15x 1 + 2 x 2 + 3 x 3 + 4 x 4 + 5 x 5<br />
(y + 15x 1 ) = 0 + 2 x 2 + 3 x 3 + 4 x 4 + 5 x 5<br />
koji procijenjen izgleda<br />
(y + 15x 1 ) = 318:21<br />
(98:061) + 3:05<br />
(0:945) x 2+ 9:76<br />
(0:715) x 3 31:17<br />
(1:008) x 4+ 36:97<br />
(10:478) x 5<br />
R 2 = 0:9989<br />
RSS R = 6993:03 :<br />
Prema tome F -test, kojim testiramo hipotezu 3.53, bit će<br />
F = (RSS R RSS UR ) =J<br />
RSS UR = (n k)<br />
=<br />
(6993:03 6808:58) =1<br />
6808:58=19<br />
= 0:514 73<br />
(p=0:4818) :<br />
Jasno je da t i F vrijednosti nisu iste, budući da proizlaze iz razliµcitih<br />
distribucija. Me†utim, toµcne razine znaµcajnosti testa p su identiµcne u<br />
54
oba sluµcaja, p = 0:4818, što upućuje na identiµcan statistiµcki zakljuµcak,<br />
tj. da ne moµzemo odbaciti nul hipotezu. Waldovim kriterijem moµzemo<br />
testirati hipotezu 3.53 na temelju matrica ograniµcenja<br />
R = 0 1 0 0 0 0 , q = 15<br />
koje daju vektor nepodudarnosti m = 18: 75. Kada ukljuµcimo ove<br />
vrijednosti u jednadµzbu 3.49 dobijemo vrijednost F = 0:514 73; koja je<br />
istovjetna F vrijednosti dobivenu prethodnom metodom (RSS).<br />
c)<br />
H 0 : 4 + 5 = 0 (3.54)<br />
nasuprot hipotezi H 1 : 4 + 5 6= 0. Iz gornje jednadµzbe slijedi da je<br />
4 = 5 ili 5 = 4 . Neovisno o tome koristimo li za ograniµcenje<br />
modela 3.50 jednakost 4 = 5 ili 5 = 4 , moramo dobiti istu<br />
vrijednost RSS R . Ako koristimo 4 = 5 ; imamo<br />
y = 0 + 1 x 1 + 2 x 2 + 3 x 3 5 x 4 + 5 x 5<br />
= 0 + 1 x 1 + 2 x 2 + 3 x 3 + 5 (x 5 x 4 )<br />
i kada procijenimo parametre dobijemo ograniµceni model<br />
y = 392:81<br />
(157:61)<br />
31:70 x 1+ 3:30 x 2+ 9:74 x 3+31:84 (x 5 x 4 )<br />
(25:508) (0:970) (0:714) (1:058)<br />
R 2 = 0:9989<br />
RSS R = 6942:08 :<br />
Ako koristimo 5 =<br />
4 imamo<br />
y = 0 + 1 x 1 + 2 x 2 + 3 x 3 + 4 x 4 4 x 5<br />
= 0 + 1 x 1 + 2 x 2 + 3 x 3 + 4 (x 4 x 5 )<br />
i kada procijenimo parametre modela dobijemo ograniµceni model<br />
y = 392:81<br />
(157:61)<br />
31:70 x 1+ 3:30 x 2+ 9:74 x 3 31:84 (x 4 x 5 )<br />
(25:508) (0:970) (0:714) (1:058)<br />
R 2 = 0:9989<br />
RSS R = 6942:08<br />
s identiµcnim RSS R . Stoga, neovisno o jednakosti koju koristimo za<br />
ograniµcenje modela, dobijemo istu F vrijednost<br />
F = (RSS R RSS UR ) =J<br />
RSS UR = (n k)<br />
=<br />
(6942:08 6808:58) =1<br />
(6808:58) =19<br />
= 0:372 6<br />
(p=0:5489) :<br />
Iz razine znaµcanost testa p = 0:5489 zakljuµcujemo da ne moµzemo odbaciti<br />
ovu hipotezu. Interesantno je primijetiti da pri testiranju ove hipoteze,<br />
iako se u hipotezi pojavljuju dva parametra, imamo samo jedno<br />
ograniµcenje. Jedno ograniµcenje bilo bi i kada bismo testirali hipotezu:<br />
H 0 : 1 + 2 2 4 + 5 = 0, unatoµc tome što se pojavljuju 4 parametra,<br />
dok s druge strane, ako npr. testiramo H 0 : 1 = 0; 4 = 30;<br />
55
imamo dva ograniµcenja. Znaµci, pri raµcunanju broja ograniµcenja nije<br />
vaµzan broj parametara koji se pojavljuje u hipotezi već broj jednadµzbi.<br />
Ako µzelimo dobiti F vrijednost pomoću Waldovog kriterija matrice<br />
ograniµcenja, kojima opisujemo hipotezu 3.54, glase<br />
R = 0 0 0 0 1 1 , q = 0<br />
koje daju vrijednost m =6:8241 i F = 0:3726; identiµcnu vrijednost<br />
koju smo dobili i metodom usporedbe RSS ograniµcenog i neograniµcenog<br />
modela.<br />
d)<br />
H 0 : 1 = 4 ; 2 = 3; 4 + 5 = 0 (3.55)<br />
nasuprot alternativnoj hipotezi H 1 : 1 6= 4 ; 2 6= 3; 4 + 5 6= 0. Kada<br />
imamo skup linearnih ograniµcenja, (kao u ovom primjeru) supstitucija<br />
tih ograniµcenja u neograniµceni model bit će sloµzen posao da bismo<br />
dobili ograniµceni model na temelju kojeg moµzemo izraµcunati RSS R ,<br />
dok će to isto matriµcnom metodom, na temelju Waldovog kriterija, biti<br />
lakše izvedivo. Matrice ograniµcenja za testiranje gornje hipoteze bit<br />
će<br />
2<br />
3 2 3<br />
R = 4<br />
0 1 0 0 1 0<br />
0 0 1 0 0 0<br />
0 0 0 0 1 1<br />
koje daju vektor nepodudarnosti<br />
2<br />
m = 4<br />
2:1789<br />
0:2314<br />
6:8241<br />
5 , q = 4<br />
3<br />
5 :<br />
0<br />
3<br />
0<br />
5<br />
Na temelju jednadµzbe 3.49 za broj ograniµcenja J = 3 dobit ćemo F<br />
vrijednost od 0:1578 kojoj odgovara razina znaµcajnosti testa p = 0:9233.<br />
Drugim rijeµcima ovu hipotezu ne moµzemo odbaciti.<br />
56
Dodatak A<br />
Izvodi i dokazi<br />
A.1 Izvod parametara modela s jednom nezavisnom<br />
varijablom metodom najmanjih kvadrata<br />
Za model<br />
y i = b 0 + b 1 x i + e i<br />
(A.1)<br />
treba izabrati parametre b 0 i b 1 tako da minimiziraju P e 2 i : Da bi se dobili<br />
parametri s tim svojstvima, mora se parcijalno derivirati izraz P e 2 i po b 0<br />
i b 1 i izjednaµciti prve derivacije s nulom kako bi se dobili ekstremi funkcija<br />
(minimum)<br />
@<br />
@b 0<br />
P e<br />
2<br />
i =<br />
@<br />
@b 0<br />
P (yi b 0 b 1 x i ) 2 = 2 P (y i b 0 b 1 x i ) = 0 (A.2)<br />
@<br />
@b 1<br />
P e<br />
2<br />
i =<br />
@<br />
@b 1<br />
P (yi b 0 b 1 x i ) 2 = 2 P x i (y i b 0 b 1 x i ) = 0: (A.3)<br />
Ako jednadµzbe A.2 i A.3 podijelimo s 2 i napišemo u obliku tzv. normalnih<br />
jednadµzbi, imamo<br />
P P<br />
yi = b 0 n + b 1 xi (A.4)<br />
P P P<br />
xi y i = b 0 xi + b 1 x<br />
2<br />
i : (A.5)<br />
Sada moµzemo simultano riješiti po b 0 i b 1 tako da jednadµzbu A.4 pomnoµzimo<br />
s P x i ; a jednadµzbu A.5 s n<br />
P<br />
xi<br />
P<br />
yi = b 0 n P x i + b 1 ( P x i ) 2 (A.6)<br />
n P x i y i = b 0 n P x i + b 1 n P x 2 i : (A.7)<br />
57
Oduzimanjem jednadµzbe A.6 od jednadµzbe A.7 dobijemo<br />
iz µcega slijedi<br />
n P x i y i<br />
P<br />
xi<br />
P<br />
yi = b 1<br />
hn P x 2 i ( P x i ) 2i (A.8)<br />
b 1 = n P P P<br />
x i y i xi yi<br />
n P x 2 i<br />
( P x i ) 2 : (A.9)<br />
Jednadµzba A.9 moµze se jednostavnije napisati, ako pretpostavimo specijalni<br />
sluµcaj da je sredina uzoraka jednaka nuli. U tom specijalnom sluµcaju<br />
moµzemo dobiti koe…cijent smjera regresijskog pravca (b 1 ) tako da brojnik i<br />
nazivnik izraza A.9 podijelimo s n 2<br />
b 1 =<br />
P<br />
x i y i<br />
n<br />
P<br />
x 2 i<br />
n<br />
P P <br />
x i y i<br />
n<br />
P<br />
x i<br />
n<br />
n<br />
2<br />
=<br />
P<br />
x i y i<br />
P n xy<br />
x 2 i<br />
n<br />
x 2 : (A.10)<br />
Budući da u našem specijalnom sluµcaju po pretpostavci vrijedi x = y = 0<br />
jednadµzba A.10 postaje<br />
P<br />
x i y i<br />
P<br />
b 1 = P n xi y<br />
= P i<br />
x 2 i x<br />
2<br />
: (A.11)<br />
i<br />
n<br />
Pojednostavljena jednadµzba A.11 vrijedi samo za specijalni sluµcaj kada<br />
varijabla x i varijabla y imaju sredinu nula. Me†utim, bilo koju varijablu<br />
moµzemo transformirati tako da ima sredinu nula, ako je izrazimo u njezinoj<br />
devijacijskoj formi 1 ~x i = x i x ~y = y i y:<br />
Ovom transformacijom paralelno pomiµcemo regresijski pravac na ishodište<br />
koordinatnog sustava mijenjajući odsjeµcak na ordinati, ali ostavljajući nagib<br />
pravca nepromijenjenim, stoga se koe…cijent nagiba regresijskog pravca b 1<br />
moµze izraziti u devijacijskoj formi varijabli<br />
b 1 =<br />
P (xi x) (y i y)<br />
P (xi x) 2 =<br />
P ~xi ~y i<br />
P ~x<br />
2<br />
i<br />
: (A.12)<br />
Kada imamo b 1 ; iz jednadµzbe A.4 jednostavno moµzemo dobiti<br />
b 0 =<br />
P<br />
yi<br />
n<br />
b 1<br />
P<br />
xi<br />
n = y b 1x: (A.13)<br />
P<br />
ex i<br />
1 Dokaz: ex = =<br />
n<br />
zbrajanja u Dodatku B.1.<br />
P<br />
(x i x)<br />
n<br />
=<br />
P<br />
x i<br />
n<br />
x = x x = 0; vidi Svojstvo B.4. operatora<br />
58
Dodatak B<br />
Matematika<br />
B.1 Neka svojstva operatora zbrajanja P<br />
Operator zbrajanja P vrijednosti varijable x<br />
nX<br />
x i = x 1 + x 2 + + x n<br />
ima sljedeća svojstva:<br />
i=1<br />
Svojstvo 1<br />
gdje je k konstanta jer<br />
nX<br />
kx i = k<br />
nX<br />
i=1<br />
i=1<br />
x i<br />
(B.1)<br />
nX<br />
kx i = kx 1 + kx 2 + + kx n<br />
i=1<br />
nX<br />
= k (x 1 + x 2 + + x n ) = k x i :<br />
Svojstvo 2<br />
nX<br />
nX nX<br />
(x i + y i ) = x i + y i<br />
i=1<br />
i=1 i=1<br />
zato jer<br />
nX<br />
(x i + y i ) = x 1 + y 1 + x 2 + y 2 + + x n + y n<br />
i=1<br />
i=1<br />
= (x 1 + x 2 + + x n ) + (y 1 + y 2 + + y n )<br />
nX nX<br />
= x i + y i :<br />
i=1 i=1<br />
(B.2)<br />
59
Svojstvo 3<br />
nX<br />
k = k + k + + k = kn<br />
i=1<br />
(B.3)<br />
Svojstvo 4<br />
gdje je x = 1 n<br />
P n<br />
i=1 x i.<br />
nX<br />
(x i x) = 0 (B.4)<br />
i=1<br />
Dokaz.<br />
P n<br />
i=1 (x i<br />
n<br />
x)<br />
P n<br />
i=1<br />
=<br />
x i nx<br />
n n<br />
= 1 nX<br />
x i x = x x = 0<br />
n<br />
i=1<br />
iz µcega slijedi<br />
P n<br />
i=1 (x i<br />
n<br />
x)<br />
= 0 ()<br />
nX<br />
(x i x) = 0:<br />
i=1<br />
60
Dodatak C<br />
Statistika<br />
C.1 Distribucije vjerojatnosti izvedene iz normalne<br />
distribucije<br />
Teorem C.1 Ako su z 1 ; z 2 ; : : : ; z n normalno i nezavisno distribuirane slu-<br />
µcajne varijable takve da z i N i ; 2 i<br />
<br />
, tada je linearna kombinacija<br />
P<br />
ki z i ;<br />
gdje su k i konstante koje nisu sve nula, tako†er normalno distribuirana sa<br />
sredinom P k i i i varijancom P k 2 i 2 i :<br />
Teorem C.2 Ako su z 1 ; z 2 ; : : : ; z n normalno i zavisno distribuirane sluµcajne<br />
varijable takve da z i N i ; 2 i<br />
<br />
, tada je linearna kombinacija<br />
P<br />
ki z i ;<br />
gdje su k i konstante koje nisu sve nula, tako†er normalno distribuirana sa<br />
sredinom P k i i i varijancom P k 2 i 2 i + 2 P k i k j cov (x i ; x j ) :<br />
Teorem C.3 Ako su z 1 ; z 2 ; : : : ; z n normalno i nezavisno distribuirane slu-<br />
µcajne varijable takve da z i N (0; 1), tj. standardizirane normalne varijable,<br />
tada P n<br />
i=1 z2 i ima 2 distribuciju s n stupnjeva slobode.<br />
Teorem C.4 Ako su x 1 ; x 2 ; : : : ; x n nezavisno distribuirane sluµcajne varijable<br />
koje imaju 2 distribuciju s n i stupnjeva slobode, tada zbroj P x i ima<br />
tako†er 2 distribuciju sa P n i stupnjeva slobode.<br />
Teorem C.5 Ako je z standardizirana normalna varijabla [z 1 N (0; 1)] a<br />
x ima 2 distribuciju s n stupnjeva slobode i nezavisna je od z, tada odnos<br />
pz<br />
ima Studentovu t distribuciju s n stupnjeva slobode.<br />
x=n<br />
Teorem C.6 Ako su x 1 i x 2 dvije nezavisne varijable s 2 distribucijom s<br />
odnosnim n 1 i n 2 stupnjevima slobode, tada odnos x 1=n 1<br />
x 2 =n 2<br />
ima F distribuciju<br />
s n 1 i n 2 stupnjeva slobode.<br />
61
Dodatak D<br />
Podaci<br />
D.1<br />
y x 1 x 2 x 3 x 4 x 5<br />
2835.9 4.49 287.80 496.1 100.00 0.3202<br />
2615.0 4.26 292.12 509.2 112.93 0.1125<br />
2556.2 3.83 296.12 510.2 115.61 0.3275<br />
2510.9 3.89 297.14 514.2 117.82 0.3974<br />
2582.6 3.79 298.66 527.9 119.16 0.3392<br />
2586.4 3.79 301.11 527.1 119.16 0.8013<br />
2608.4 3.98 306.48 529.9 119.06 1.3413<br />
2542.7 3.97 310.93 524.6 119.59 1.1790<br />
2598.7 4.02 316.30 528.9 120.79 0.8171<br />
2662.4 3.87 322.14 539.9 122.94 0.4666<br />
2704.3 3.99 327.57 550.3 124.90 0.2619<br />
2767.3 3.90 333.33 563.4 127.73 0.4310<br />
2894.1 3.89 340.24 576.8 129.21 0.0325<br />
2980.6 3.96 347.41 583.9 129.93 0.0507<br />
3022.8 4.03 352.85 591.0 130.56 0.3994<br />
3088.2 4.12 359.90 594.4 130.60 0.4184<br />
3207.4 4.18 367.92 603.4 130.60 0.6175<br />
3360.1 4.20 375.92 612.1 130.22 0.7757<br />
3513.9 4.19 383.57 624.9 130.46 0.7226<br />
3641.5 4.17 391.03 634.3 129.69 0.6831<br />
3840.1 4.20 397.53 650.4 128.74 0.7747<br />
3888.3 4.21 404.34 659.6 130.12 0.5136<br />
3920.2 4.25 413.47 671.2 133.57 0.5501<br />
3816.3 4.47 421.96 676.3 138.70 0.7459<br />
3951.2 4.77 430.39 696.5 142.58 0.8152<br />
62
Dodatak E<br />
Statistiµcke tablice<br />
Tablica E.1: Kumulativna površina ispod standardne normalne distribucije<br />
z 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09<br />
0.0 0.5000 0.5040 0.5080 0.5120 0.5160 0.5199 0.5239 0.5279 0.5319 0.5359<br />
0.1 0.5398 0.5438 0.5478 0.5517 0.5557 0.5596 0.5636 0.5675 0.5714 0.5753<br />
0.2 0.5793 0.5832 0.5871 0.5910 0.5948 0.5987 0.6026 0.6064 0.6103 0.6141<br />
0.3 0.6179 0.6217 0.6255 0.6293 0.6331 0.6368 0.6406 0.6443 0.6480 0.6517<br />
0.4 0.6554 0.6591 0.6628 0.6664 0.6700 0.6736 0.6772 0.6808 0.6844 0.6879<br />
0.5 0.6915 0.6950 0.6985 0.7019 0.7054 0.7088 0.7123 0.7157 0.7190 0.7224<br />
0.6 0.7257 0.7291 0.7324 0.7357 0.7389 0.7422 0.7454 0.7486 0.7517 0.7549<br />
0.7 0.7580 0.7611 0.7642 0.7673 0.7704 0.7734 0.7764 0.7794 0.7823 0.7852<br />
0.8 0.7881 0.7910 0.7939 0.7967 0.7995 0.8023 0.8051 0.8078 0.8106 0.8133<br />
0.9 0.8159 0.8186 0.8212 0.8238 0.8264 0.8289 0.8315 0.8340 0.8365 0.8389<br />
1.0 0.8413 0.8438 0.8461 0.8485 0.8508 0.8531 0.8554 0.8577 0.8599 0.8621<br />
1.1 0.8643 0.8665 0.8686 0.8708 0.8729 0.8749 0.8770 0.8790 0.8810 0.8830<br />
1.2 0.8849 0.8869 0.8888 0.8907 0.8925 0.8944 0.8962 0.8980 0.8997 0.9015<br />
1.3 0.9032 0.9049 0.9066 0.9082 0.9099 0.9115 0.9131 0.9147 0.9162 0.9177<br />
1.4 0.9192 0.9207 0.9222 0.9236 0.9251 0.9265 0.9279 0.9292 0.9306 0.9319<br />
1.5 0.9332 0.9345 0.9357 0.9370 0.9382 0.9394 0.9406 0.9418 0.9429 0.9441<br />
1.6 0.9452 0.9463 0.9474 0.9484 0.9495 0.9505 0.9515 0.9525 0.9535 0.9545<br />
1.7 0.9554 0.9564 0.9573 0.9582 0.9591 0.9599 0.9608 0.9616 0.9625 0.9633<br />
1.8 0.9641 0.9649 0.9656 0.9664 0.9671 0.9678 0.9686 0.9693 0.9699 0.9706<br />
1.9 0.9713 0.9719 0.9726 0.9732 0.9738 0.9744 0.9750 0.9756 0.9761 0.9767<br />
2.0 0.9772 0.9778 0.9783 0.9788 0.9793 0.9798 0.9803 0.9808 0.9812 0.9817<br />
2.1 0.9821 0.9826 0.9830 0.9834 0.9838 0.9842 0.9846 0.9850 0.9854 0.9857<br />
2.2 0.9861 0.9864 0.9868 0.9871 0.9875 0.9878 0.9881 0.9884 0.9887 0.9890<br />
2.3 0.9893 0.9896 0.9898 0.9901 0.9904 0.9906 0.9909 0.9911 0.9913 0.9916<br />
2.4 0.9918 0.9920 0.9922 0.9925 0.9927 0.9929 0.9931 0.9932 0.9934 0.9936<br />
2.5 0.9938 0.9940 0.9941 0.9943 0.9945 0.9946 0.9948 0.9949 0.9951 0.9952<br />
2.6 0.9953 0.9955 0.9956 0.9957 0.9959 0.9960 0.9961 0.9962 0.9963 0.9964<br />
2.7 0.9965 0.9966 0.9967 0.9968 0.9969 0.9970 0.9971 0.9972 0.9973 0.9974<br />
2.8 0.9974 0.9975 0.9976 0.9977 0.9977 0.9978 0.9979 0.9979 0.9980 0.9981<br />
2.9 0.9981 0.9982 0.9982 0.9983 0.9984 0.9984 0.9985 0.9985 0.9986 0.9986<br />
3.0 0.9987 0.9987 0.9987 0.9988 0.9988 0.9989 0.9989 0.9989 0.9990 0.9990<br />
3.1 0.9990 0.9991 0.9991 0.9991 0.9992 0.9992 0.9992 0.9992 0.9993 0.9993<br />
3.2 0.9993 0.9993 0.9994 0.9994 0.9994 0.9994 0.9994 0.9995 0.9995 0.9995<br />
3.3 0.9995 0.9995 0.9995 0.9996 0.9996 0.9996 0.9996 0.9996 0.9996 0.9997<br />
3.4 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9997 0.9998<br />
3.5 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998 0.9998<br />
Izvor: Vrijednosti su izračunate koristeći Excel funkciju NORMSDIST<br />
63
Tablica E.2: Jednostrane kritiµcne vrijednosti Studentove t distribucije<br />
n¡ k 0.10 0.05 0.25 0.001 0.005<br />
1 3.0777 6.3137 12.7062 31.8210 63.6559<br />
2 1.8856 2.9200 4.3027 6.9645 9.9250<br />
3 1.6377 2.3534 3.1824 4.5407 5.8408<br />
4 1.5332 2.1318 2.7765 3.7469 4.6041<br />
5 1.4759 2.0150 2.5706 3.3649 4.0321<br />
6 1.4398 1.9432 2.4469 3.1427 3.7074<br />
7 1.4149 1.8946 2.3646 2.9979 3.4995<br />
8 1.3968 1.8595 2.3060 2.8965 3.3554<br />
9 1.3830 1.8331 2.2622 2.8214 3.2498<br />
10 1.3722 1.8125 2.2281 2.7638 3.1693<br />
11 1.3634 1.7959 2.2010 2.7181 3.1058<br />
12 1.3562 1.7823 2.1788 2.6810 3.0545<br />
13 1.3502 1.7709 2.1604 2.6503 3.0123<br />
14 1.3450 1.7613 2.1448 2.6245 2.9768<br />
15 1.3406 1.7531 2.1315 2.6025 2.9467<br />
16 1.3368 1.7459 2.1199 2.5835 2.9208<br />
17 1.3334 1.7396 2.1098 2.5669 2.8982<br />
18 1.3304 1.7341 2.1009 2.5524 2.8784<br />
19 1.3277 1.7291 2.0930 2.5395 2.8609<br />
20 1.3253 1.7247 2.0860 2.5280 2.8453<br />
21 1.3232 1.7207 2.0796 2.5176 2.8314<br />
22 1.3212 1.7171 2.0739 2.5083 2.8188<br />
23 1.3195 1.7139 2.0687 2.4999 2.8073<br />
24 1.3178 1.7109 2.0639 2.4922 2.7970<br />
25 1.3163 1.7081 2.0595 2.4851 2.7874<br />
26 1.3150 1.7056 2.0555 2.4786 2.7787<br />
27 1.3137 1.7033 2.0518 2.4727 2.7707<br />
28 1.3125 1.7011 2.0484 2.4671 2.7633<br />
29 1.3114 1.6991 2.0452 2.4620 2.7564<br />
30 1.3104 1.6973 2.0423 2.4573 2.7500<br />
40 1.3031 1.6839 2.0211 2.4233 2.7045<br />
60 1.2958 1.6706 2.0003 2.3901 2.6603<br />
120 1.2886 1.6576 1.9799 2.3578 2.6174<br />
1 1.2816 1.6449 1.9600 2.3264 2.5758<br />
Izvor: Vrijednosti su izračunate koristeći Excel funkciju TINV<br />
Æ<br />
64
Tablica E.3: Jednostrane kritiµcne vrijednosti F distribucije za 5 posto znaµcajnosti<br />
n 1<br />
n 2 1 2 3 4 5 6 7 8 9 10 12 15 20 25<br />
1 161.446 199.499 215.707 224.583 230.160 233.988 236.767 238.884 240.543 241.882 243.905 245.949 248.016 249.260<br />
2 18.513 19.000 19.164 19.247 19.296 19.329 19.353 19.371 19.385 19.396 19.412 19.429 19.446 19.456<br />
3 10.128 9.552 9.277 9.117 9.013 8.941 8.887 8.845 8.812 8.785 8.745 8.703 8.660 8.634<br />
4 7.709 6.944 6.591 6.388 6.256 6.163 6.094 6.041 5.999 5.964 5.912 5.858 5.803 5.769<br />
5 6.608 5.786 5.409 5.192 5.050 4.950 4.876 4.818 4.772 4.735 4.678 4.619 4.558 4.521<br />
6 5.987 5.143 4.757 4.534 4.387 4.284 4.207 4.147 4.099 4.060 4.000 3.938 3.874 3.835<br />
7 5.591 4.737 4.347 4.120 3.972 3.866 3.787 3.726 3.677 3.637 3.575 3.511 3.445 3.404<br />
8 5.318 4.459 4.066 3.838 3.688 3.581 3.500 3.438 3.388 3.347 3.284 3.218 3.150 3.108<br />
9 5.117 4.256 3.863 3.633 3.482 3.374 3.293 3.230 3.179 3.137 3.073 3.006 2.936 2.893<br />
10 4.965 4.103 3.708 3.478 3.326 3.217 3.135 3.072 3.020 2.978 2.913 2.845 2.774 2.730<br />
11 4.844 3.982 3.587 3.357 3.204 3.095 3.012 2.948 2.896 2.854 2.788 2.719 2.646 2.601<br />
12 4.747 3.885 3.490 3.259 3.106 2.996 2.913 2.849 2.796 2.753 2.687 2.617 2.544 2.498<br />
13 4.667 3.806 3.411 3.179 3.025 2.915 2.832 2.767 2.714 2.671 2.604 2.533 2.459 2.412<br />
14 4.600 3.739 3.344 3.112 2.958 2.848 2.764 2.699 2.646 2.602 2.534 2.463 2.388 2.341<br />
15 4.543 3.682 3.287 3.056 2.901 2.790 2.707 2.641 2.588 2.544 2.475 2.403 2.328 2.280<br />
16 4.494 3.634 3.239 3.007 2.852 2.741 2.657 2.591 2.538 2.494 2.425 2.352 2.276 2.227<br />
17 4.451 3.592 3.197 2.965 2.810 2.699 2.614 2.548 2.494 2.450 2.381 2.308 2.230 2.181<br />
18 4.414 3.555 3.160 2.928 2.773 2.661 2.577 2.510 2.456 2.412 2.342 2.269 2.191 2.141<br />
19 4.381 3.522 3.127 2.895 2.740 2.628 2.544 2.477 2.423 2.378 2.308 2.234 2.155 2.106<br />
20 4.351 3.493 3.098 2.866 2.711 2.599 2.514 2.447 2.393 2.348 2.278 2.203 2.124 2.074<br />
21 4.325 3.467 3.072 2.840 2.685 2.573 2.488 2.420 2.366 2.321 2.250 2.176 2.096 2.045<br />
22 4.301 3.443 3.049 2.817 2.661 2.549 2.464 2.397 2.342 2.297 2.226 2.151 2.071 2.020<br />
23 4.279 3.422 3.028 2.796 2.640 2.528 2.442 2.375 2.320 2.275 2.204 2.128 2.048 1.996<br />
24 4.260 3.403 3.009 2.776 2.621 2.508 2.423 2.355 2.300 2.255 2.183 2.108 2.027 1.975<br />
25 4.242 3.385 2.991 2.759 2.603 2.490 2.405 2.337 2.282 2.236 2.165 2.089 2.007 1.955<br />
26 4.225 3.369 2.975 2.743 2.587 2.474 2.388 2.321 2.265 2.220 2.148 2.072 1.990 1.938<br />
27 4.210 3.354 2.960 2.728 2.572 2.459 2.373 2.305 2.250 2.204 2.132 2.056 1.974 1.921<br />
28 4.196 3.340 2.947 2.714 2.558 2.445 2.359 2.291 2.236 2.190 2.118 2.041 1.959 1.906<br />
29 4.183 3.328 2.934 2.701 2.545 2.432 2.346 2.278 2.223 2.177 2.104 2.027 1.945 1.891<br />
30 4.171 3.316 2.922 2.690 2.534 2.421 2.334 2.266 2.211 2.165 2.092 2.015 1.932 1.878<br />
31 4.160 3.305 2.911 2.679 2.523 2.409 2.323 2.255 2.199 2.153 2.080 2.003 1.920 1.866<br />
32 4.149 3.295 2.901 2.668 2.512 2.399 2.313 2.244 2.189 2.142 2.070 1.992 1.908 1.854<br />
33 4.139 3.285 2.892 2.659 2.503 2.389 2.303 2.235 2.179 2.133 2.060 1.982 1.898 1.844<br />
34 4.130 3.276 2.883 2.650 2.494 2.380 2.294 2.225 2.170 2.123 2.050 1.972 1.888 1.833<br />
35 4.121 3.267 2.874 2.641 2.485 2.372 2.285 2.217 2.161 2.114 2.041 1.963 1.878 1.824<br />
36 4.113 3.259 2.866 2.634 2.477 2.364 2.277 2.209 2.153 2.106 2.033 1.954 1.870 1.815<br />
37 4.105 3.252 2.859 2.626 2.470 2.356 2.270 2.201 2.145 2.098 2.025 1.946 1.861 1.806<br />
38 4.098 3.245 2.852 2.619 2.463 2.349 2.262 2.194 2.138 2.091 2.017 1.939 1.853 1.798<br />
39 4.091 3.238 2.845 2.612 2.456 2.342 2.255 2.187 2.131 2.084 2.010 1.931 1.846 1.791<br />
40 4.085 3.232 2.839 2.606 2.449 2.336 2.249 2.180 2.124 2.077 2.003 1.924 1.839 1.783<br />
Izvor: Vrijednosti su izračunate koristeći Excel funkciju FINV. n1=stupnjevi slobode brojnika, n 2=stupnjevi slobode nazivnika<br />
65
Tablica E.4: Jednostrane kritiµcne vrijednosti F distribucije za 1 posto znaµcajnosti<br />
n 1<br />
n 2 1 2 3 4 5 6 7 8 9 10 12 15 20<br />
1 4052.185 4999.340 5403.534 5624.257 5763.955 5858.950 5928.334 5980.954 6022.397 6055.925 6106.682 6156.974 6208.662<br />
2 98.502 99.000 99.164 99.251 99.302 99.331 99.357 99.375 99.390 99.397 99.419 99.433 99.448<br />
3 34.116 30.816 29.457 28.710 28.237 27.911 27.671 27.489 27.345 27.228 27.052 26.872 26.690<br />
4 21.198 18.000 16.694 15.977 15.522 15.207 14.976 14.799 14.659 14.546 14.374 14.198 14.019<br />
5 16.258 13.274 12.060 11.392 10.967 10.672 10.456 10.289 10.158 10.051 9.888 9.722 9.553<br />
6 13.745 10.925 9.780 9.148 8.746 8.466 8.260 8.102 7.976 7.874 7.718 7.559 7.396<br />
7 12.246 9.547 8.451 7.847 7.460 7.191 6.993 6.840 6.719 6.620 6.469 6.314 6.155<br />
8 11.259 8.649 7.591 7.006 6.632 6.371 6.178 6.029 5.911 5.814 5.667 5.515 5.359<br />
9 10.562 8.022 6.992 6.422 6.057 5.802 5.613 5.467 5.351 5.257 5.111 4.962 4.808<br />
10 10.044 7.559 6.552 5.994 5.636 5.386 5.200 5.057 4.942 4.849 4.706 4.558 4.405<br />
11 9.646 7.206 6.217 5.668 5.316 5.069 4.886 4.744 4.632 4.539 4.397 4.251 4.099<br />
12 9.330 6.927 5.953 5.412 5.064 4.821 4.640 4.499 4.388 4.296 4.155 4.010 3.858<br />
13 9.074 6.701 5.739 5.205 4.862 4.620 4.441 4.302 4.191 4.100 3.960 3.815 3.665<br />
14 8.862 6.515 5.564 5.035 4.695 4.456 4.278 4.140 4.030 3.939 3.800 3.656 3.505<br />
15 8.683 6.359 5.417 4.893 4.556 4.318 4.142 4.004 3.895 3.805 3.666 3.522 3.372<br />
16 8.531 6.226 5.292 4.773 4.437 4.202 4.026 3.890 3.780 3.691 3.553 3.409 3.259<br />
17 8.400 6.112 5.185 4.669 4.336 4.101 3.927 3.791 3.682 3.593 3.455 3.312 3.162<br />
18 8.285 6.013 5.092 4.579 4.248 4.015 3.841 3.705 3.597 3.508 3.371 3.227 3.077<br />
19 8.185 5.926 5.010 4.500 4.171 3.939 3.765 3.631 3.523 3.434 3.297 3.153 3.003<br />
20 8.096 5.849 4.938 4.431 4.103 3.871 3.699 3.564 3.457 3.368 3.231 3.088 2.938<br />
21 8.017 5.780 4.874 4.369 4.042 3.812 3.640 3.506 3.398 3.310 3.173 3.030 2.880<br />
22 7.945 5.719 4.817 4.313 3.988 3.758 3.587 3.453 3.346 3.258 3.121 2.978 2.827<br />
23 7.881 5.664 4.765 4.264 3.939 3.710 3.539 3.406 3.299 3.211 3.074 2.931 2.780<br />
24 7.823 5.614 4.718 4.218 3.895 3.667 3.496 3.363 3.256 3.168 3.032 2.889 2.738<br />
25 7.770 5.568 4.675 4.177 3.855 3.627 3.457 3.324 3.217 3.129 2.993 2.850 2.699<br />
26 7.721 5.526 4.637 4.140 3.818 3.591 3.421 3.288 3.182 3.094 2.958 2.815 2.664<br />
27 7.677 5.488 4.601 4.106 3.785 3.558 3.388 3.256 3.149 3.062 2.926 2.783 2.632<br />
28 7.636 5.453 4.568 4.074 3.754 3.528 3.358 3.226 3.120 3.032 2.896 2.753 2.602<br />
29 7.598 5.420 4.538 4.045 3.725 3.499 3.330 3.198 3.092 3.005 2.868 2.726 2.574<br />
30 7.562 5.390 4.510 4.018 3.699 3.473 3.305 3.173 3.067 2.979 2.843 2.700 2.549<br />
31 7.530 5.362 4.484 3.993 3.675 3.449 3.281 3.149 3.043 2.955 2.820 2.677 2.525<br />
32 7.499 5.336 4.459 3.969 3.652 3.427 3.258 3.127 3.021 2.934 2.798 2.655 2.503<br />
33 7.471 5.312 4.437 3.948 3.630 3.406 3.238 3.106 3.000 2.913 2.777 2.634 2.482<br />
34 7.444 5.289 4.416 3.927 3.611 3.386 3.218 3.087 2.981 2.894 2.758 2.615 2.463<br />
35 7.419 5.268 4.396 3.908 3.592 3.368 3.200 3.069 2.963 2.876 2.740 2.597 2.445<br />
36 7.396 5.248 4.377 3.890 3.574 3.351 3.183 3.052 2.946 2.859 2.723 2.580 2.428<br />
37 7.374 5.229 4.360 3.873 3.558 3.334 3.167 3.036 2.930 2.843 2.707 2.564 2.412<br />
38 7.353 5.211 4.343 3.858 3.542 3.319 3.152 3.021 2.915 2.828 2.692 2.549 2.397<br />
39 7.333 5.194 4.327 3.843 3.528 3.305 3.137 3.006 2.901 2.814 2.678 2.535 2.382<br />
40 7.314 5.178 4.313 3.828 3.514 3.291 3.124 2.993 2.888 2.801 2.665 2.522 2.369<br />
Izvor: Vrijednosti su izračunate koristeći Excel funkciju FINV. n1=stupnjevi slobode brojnika, n 2=stupnjevi slobode nazivnika<br />
66
Tablica E.5: Jednostrane kritiµcne vrijednosti 2 distribucije<br />
Æ<br />
n¡ k 0.995 0.990 0.975 0.95 0.9 0.5 0.1 0.05 0.025 0.01 0.005<br />
1 0.000 0.000 0.001 0.004 0.016 0.455 2.706 3.841 5.024 6.635 7.879<br />
2 0.010 0.020 0.051 0.103 0.211 1.386 4.605 5.991 7.378 9.210 10.597<br />
3 0.072 0.115 0.216 0.352 0.584 2.366 6.251 7.815 9.348 11.345 12.838<br />
4 0.207 0.297 0.484 0.711 1.064 3.357 7.779 9.488 11.143 13.277 14.860<br />
5 0.412 0.554 0.831 1.145 1.610 4.351 9.236 11.070 12.832 15.086 16.750<br />
6 0.676 0.872 1.237 1.635 2.204 5.348 10.645 12.592 14.449 16.812 18.548<br />
7 0.989 1.239 1.690 2.167 2.833 6.346 12.017 14.067 16.013 18.475 20.278<br />
8 1.344 1.647 2.180 2.733 3.490 7.344 13.362 15.507 17.535 20.090 21.955<br />
9 1.735 2.088 2.700 3.325 4.168 8.343 14.684 16.919 19.023 21.666 23.589<br />
10 2.156 2.558 3.247 3.940 4.865 9.342 15.987 18.307 20.483 23.209 25.188<br />
11 2.603 3.053 3.816 4.575 5.578 10.341 17.275 19.675 21.920 24.725 26.757<br />
12 3.074 3.571 4.404 5.226 6.304 11.340 18.549 21.026 23.337 26.217 28.300<br />
13 3.565 4.107 5.009 5.892 7.041 12.340 19.812 22.362 24.736 27.688 29.819<br />
14 4.075 4.660 5.629 6.571 7.790 13.339 21.064 23.685 26.119 29.141 31.319<br />
15 4.601 5.229 6.262 7.261 8.547 14.339 22.307 24.996 27.488 30.578 32.801<br />
16 5.142 5.812 6.908 7.962 9.312 15.338 23.542 26.296 28.845 32.000 34.267<br />
17 5.697 6.408 7.564 8.672 10.085 16.338 24.769 27.587 30.191 33.409 35.718<br />
18 6.265 7.015 8.231 9.390 10.865 17.338 25.989 28.869 31.526 34.805 37.156<br />
19 6.844 7.633 8.907 10.117 11.651 18.338 27.204 30.144 32.852 36.191 38.582<br />
20 7.434 8.260 9.591 10.851 12.443 19.337 28.412 31.410 34.170 37.566 39.997<br />
21 8.034 8.897 10.283 11.591 13.240 20.337 29.615 32.671 35.479 38.932 41.401<br />
22 8.643 9.542 10.982 12.338 14.041 21.337 30.813 33.924 36.781 40.289 42.796<br />
23 9.260 10.196 11.689 13.091 14.848 22.337 32.007 35.172 38.076 41.638 44.181<br />
24 9.886 10.856 12.401 13.848 15.659 23.337 33.196 36.415 39.364 42.980 45.558<br />
25 10.520 11.524 13.120 14.611 16.473 24.337 34.382 37.652 40.646 44.314 46.928<br />
26 11.160 12.198 13.844 15.379 17.292 25.336 35.563 38.885 41.923 45.642 48.290<br />
27 11.808 12.878 14.573 16.151 18.114 26.336 36.741 40.113 43.195 46.963 49.645<br />
28 12.461 13.565 15.308 16.928 18.939 27.336 37.916 41.337 44.461 48.278 50.994<br />
29 13.121 14.256 16.047 17.708 19.768 28.336 39.087 42.557 45.722 49.588 52.335<br />
30 13.787 14.953 16.791 18.493 20.599 29.336 40.256 43.773 46.979 50.892 53.672<br />
31 14.458 15.655 17.539 19.281 21.434 30.336 41.422 44.985 48.232 52.191 55.002<br />
32 15.134 16.362 18.291 20.072 22.271 31.336 42.585 46.194 49.480 53.486 56.328<br />
33 15.815 17.073 19.047 20.867 23.110 32.336 43.745 47.400 50.725 54.775 57.648<br />
34 16.501 17.789 19.806 21.664 23.952 33.336 44.903 48.602 51.966 56.061 58.964<br />
35 17.192 18.509 20.569 22.465 24.797 34.336 46.059 49.802 53.203 57.342 60.275<br />
36 17.887 19.233 21.336 23.269 25.643 35.336 47.212 50.998 54.437 58.619 61.581<br />
37 18.586 19.960 22.106 24.075 26.492 36.336 48.363 52.192 55.668 59.893 62.883<br />
38 19.289 20.691 22.878 24.884 27.343 37.335 49.513 53.384 56.895 61.162 64.181<br />
39 19.996 21.426 23.654 25.695 28.196 38.335 50.660 54.572 58.120 62.428 65.475<br />
40 20.707 22.164 24.433 26.509 29.051 39.335 51.805 55.758 59.342 63.691 66.766<br />
Izvor: Vrijednosti su izračunate koristeći Excel funkciju CHIINV.<br />
67
Bibliogra…ja<br />
[1] Baltagi, B.H., (2011), Econometrics, peto izdanje, Springer Text in Business<br />
and Economics.<br />
[2] Davidson, R., J.G. MacKinnon, (2004), Econometric Theory and Methods,<br />
Oxford University Press, New York.<br />
[3] Greene, W.H., (2003), Econometric Analysis, peto izdanje, Prentice Hall,<br />
New Jersey.<br />
[4] Gujarati, D.N., (2004), Basic Econometrics, µcetvrto izdanje, McGraw-<br />
Hill, New York.<br />
[5] Hayashi, F., (2000), Econometrics, Princenton University Press, New<br />
Jersey.<br />
[6] Kennedy, P., (2003), A Guide to Econometrics, peto izdanje, MIT Press,<br />
Cambridge, Massachusetts.<br />
[7] Pindyck R.S., D.C. Rubenfeld, (1998), Econometric Models and Economic<br />
Forecasts, µcetvrto izdanje, McGraw-Hill, New York.<br />
[8] Verbeek, M., (2005), A Guide to Modern Econometrics, drugo izdanje,<br />
John Wiley & sons, West Sussex, England.<br />
[9] Wooldridge, J., (2006), Introductory Econometrics: A Modern Approach,<br />
treće izdanje, South-Western Pub.<br />
68