

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
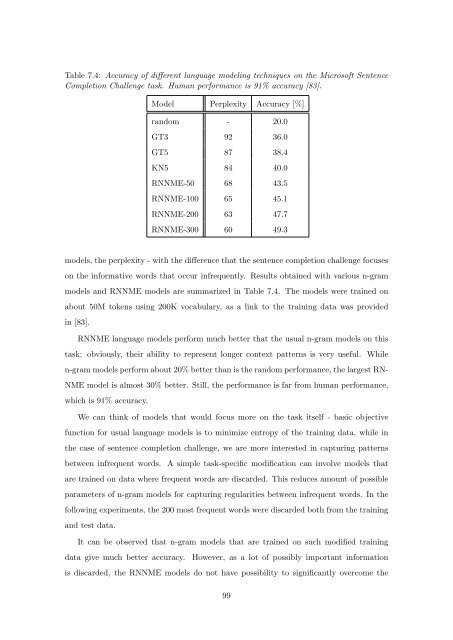
Table 7.4: Accuracy <strong>of</strong> different language modeling techniques <strong>on</strong> the Micros<strong>of</strong>t Sentence<br />
Completi<strong>on</strong> Challenge task. Human performance is 91% accuracy [83].<br />
Model Perplexity Accuracy [%]<br />
random - 20.0<br />
GT3 92 36.0<br />
GT5 87 38.4<br />
KN5 84 40.0<br />
RNNME-50 68 43.5<br />
RNNME-100 65 45.1<br />
RNNME-200 63 47.7<br />
RNNME-300 60 49.3<br />
models, the perplexity - with the difference that the sentence completi<strong>on</strong> challenge focuses<br />
<strong>on</strong> the informative words that occur infrequently. Results obtained with various n-gram<br />
models and RNNME models are summarized in Table 7.4. The models were trained <strong>on</strong><br />
about 50M tokens using 200K vocabulary, as a link to the training data was provided<br />
in [83].<br />
RNNME language models perform much better that the usual n-gram models <strong>on</strong> this<br />
task: obviously, their ability to represent l<strong>on</strong>ger c<strong>on</strong>text patterns is very useful. While<br />
n-gram models perform about 20% better than is the random performance, the largest RN-<br />
NME model is almost 30% better. Still, the performance is far from human performance,<br />
which is 91% accuracy.<br />
We can think <strong>of</strong> models that would focus more <strong>on</strong> the task itself - basic objective<br />
functi<strong>on</strong> for usual language models is to minimize entropy <strong>of</strong> the training data, while in<br />
the case <strong>of</strong> sentence completi<strong>on</strong> challenge, we are more interested in capturing patterns<br />
between infrequent words. A simple task-specific modificati<strong>on</strong> can involve models that<br />
are trained <strong>on</strong> data where frequent words are discarded. This reduces amount <strong>of</strong> possible<br />
parameters <strong>of</strong> n-gram models for capturing regularities between infrequent words. In the<br />
following experiments, the 200 most frequent words were discarded both from the training<br />
and test data.<br />
It can be observed that n-gram models that are trained <strong>on</strong> such modified training<br />
data give much better accuracy. However, as a lot <strong>of</strong> possibly important informati<strong>on</strong><br />
is discarded, the RNNME models do not have possibility to significantly overcome the<br />
99




