

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Entropy<br />
8.4<br />
8.2<br />
8<br />
7.8<br />
7.6<br />
7.4<br />
7.2<br />
7<br />
6.8<br />
1 2 3 4 5 6 7 8<br />
Epoch<br />
KN4<br />
RNN-40<br />
RNNME-40 (1G)<br />
RNNME-40 (8G)<br />
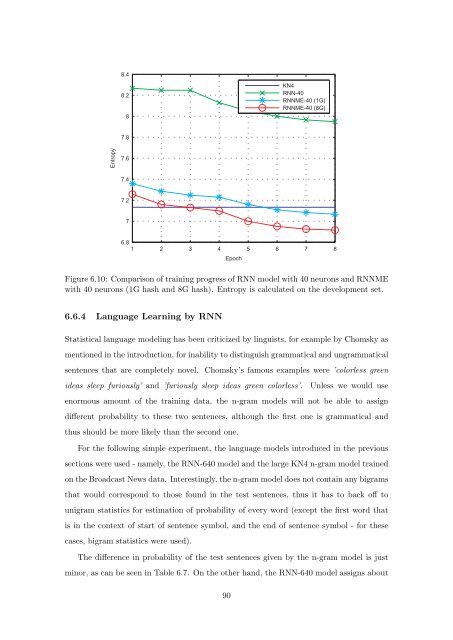
Figure 6.10: Comparis<strong>on</strong> <strong>of</strong> training progress <strong>of</strong> RNN model with 40 neur<strong>on</strong>s and RNNME<br />
with 40 neur<strong>on</strong>s (1G hash and 8G hash). Entropy is calculated <strong>on</strong> the development set.<br />
6.6.4 <str<strong>on</strong>g>Language</str<strong>on</strong>g> Learning by RNN<br />
<str<strong>on</strong>g>Statistical</str<strong>on</strong>g> language modeling has been criticized by linguists, for example by Chomsky as<br />
menti<strong>on</strong>ed in the introducti<strong>on</strong>, for inability to distinguish grammatical and ungrammatical<br />
sentences that are completely novel. Chomsky’s famous examples were ’colorless green<br />
ideas sleep furiously’ and ’furiously sleep ideas green colorless’. Unless we would use<br />
enormous amount <strong>of</strong> the training data, the n-gram models will not be able to assign<br />
different probability to these two sentences, although the first <strong>on</strong>e is grammatical and<br />
thus should be more likely than the sec<strong>on</strong>d <strong>on</strong>e.<br />
For the following simple experiment, the language models introduced in the previous<br />
secti<strong>on</strong>s were used - namely, the RNN-640 model and the large KN4 n-gram model trained<br />
<strong>on</strong> the Broadcast News data. Interestingly, the n-gram model does not c<strong>on</strong>tain any bigrams<br />
that would corresp<strong>on</strong>d to those found in the test sentences, thus it has to back <strong>of</strong>f to<br />
unigram statistics for estimati<strong>on</strong> <strong>of</strong> probability <strong>of</strong> every word (except the first word that<br />
is in the c<strong>on</strong>text <strong>of</strong> start <strong>of</strong> sentence symbol, and the end <strong>of</strong> sentence symbol - for these<br />
cases, bigram statistics were used).<br />
The difference in probability <strong>of</strong> the test sentences given by the n-gram model is just<br />
minor, as can be seen in Table 6.7. On the other hand, the RNN-640 model assigns about<br />
90




