

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
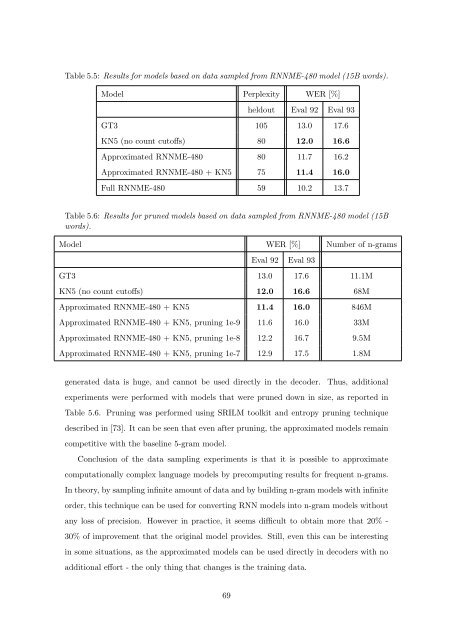
Table 5.5: Results for models <str<strong>on</strong>g>based</str<strong>on</strong>g> <strong>on</strong> data sampled from RNNME-480 model (15B words).<br />
Model Perplexity WER [%]<br />
heldout Eval 92 Eval 93<br />
GT3 105 13.0 17.6<br />
KN5 (no count cut<strong>of</strong>fs) 80 12.0 16.6<br />
Approximated RNNME-480 80 11.7 16.2<br />
Approximated RNNME-480 + KN5 75 11.4 16.0<br />
Full RNNME-480 59 10.2 13.7<br />
Table 5.6: Results for pruned models <str<strong>on</strong>g>based</str<strong>on</strong>g> <strong>on</strong> data sampled from RNNME-480 model (15B<br />
words).<br />
Model WER [%] Number <strong>of</strong> n-grams<br />
Eval 92 Eval 93<br />
GT3 13.0 17.6 11.1M<br />
KN5 (no count cut<strong>of</strong>fs) 12.0 16.6 68M<br />
Approximated RNNME-480 + KN5 11.4 16.0 846M<br />
Approximated RNNME-480 + KN5, pruning 1e-9 11.6 16.0 33M<br />
Approximated RNNME-480 + KN5, pruning 1e-8 12.2 16.7 9.5M<br />
Approximated RNNME-480 + KN5, pruning 1e-7 12.9 17.5 1.8M<br />
generated data is huge, and cannot be used directly in the decoder. Thus, additi<strong>on</strong>al<br />
experiments were performed with models that were pruned down in size, as reported in<br />
Table 5.6. Pruning was performed using SRILM toolkit and entropy pruning technique<br />
described in [73]. It can be seen that even after pruning, the approximated models remain<br />
competitive with the baseline 5-gram model.<br />
C<strong>on</strong>clusi<strong>on</strong> <strong>of</strong> the data sampling experiments is that it is possible to approximate<br />
computati<strong>on</strong>ally complex language models by precomputing results for frequent n-grams.<br />
In theory, by sampling infinite amount <strong>of</strong> data and by building n-gram models with infinite<br />
order, this technique can be used for c<strong>on</strong>verting RNN models into n-gram models without<br />
any loss <strong>of</strong> precisi<strong>on</strong>. However in practice, it seems difficult to obtain more that 20% -<br />
30% <strong>of</strong> improvement that the original model provides. Still, even this can be interesting<br />
in some situati<strong>on</strong>s, as the approximated models can be used directly in decoders with no<br />
additi<strong>on</strong>al effort - the <strong>on</strong>ly thing that changes is the training data.<br />
69




