

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Perplexity<br />
1600<br />
1400<br />
1200<br />
1000<br />
800<br />
600<br />
400<br />
200<br />
0 100 200 300 400 500 600<br />
Sorted chunks<br />
Held-out set<br />
Eval set<br />
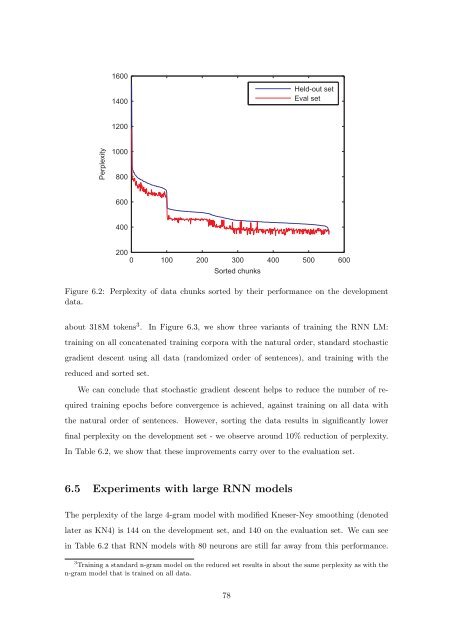
Figure 6.2: Perplexity <strong>of</strong> data chunks sorted by their performance <strong>on</strong> the development<br />
data.<br />
about 318M tokens 3 . In Figure 6.3, we show three variants <strong>of</strong> training the RNN LM:<br />
training <strong>on</strong> all c<strong>on</strong>catenated training corpora with the natural order, standard stochastic<br />
gradient descent using all data (randomized order <strong>of</strong> sentences), and training with the<br />
reduced and sorted set.<br />
We can c<strong>on</strong>clude that stochastic gradient descent helps to reduce the number <strong>of</strong> re-<br />
quired training epochs before c<strong>on</strong>vergence is achieved, against training <strong>on</strong> all data with<br />
the natural order <strong>of</strong> sentences. However, sorting the data results in significantly lower<br />
final perplexity <strong>on</strong> the development set - we observe around 10% reducti<strong>on</strong> <strong>of</strong> perplexity.<br />
In Table 6.2, we show that these improvements carry over to the evaluati<strong>on</strong> set.<br />
6.5 Experiments with large RNN models<br />
The perplexity <strong>of</strong> the large 4-gram model with modified Kneser-Ney smoothing (denoted<br />
later as KN4) is 144 <strong>on</strong> the development set, and 140 <strong>on</strong> the evaluati<strong>on</strong> set. We can see<br />
in Table 6.2 that RNN models with 80 neur<strong>on</strong>s are still far away from this performance.<br />
3 Training a standard n-gram model <strong>on</strong> the reduced set results in about the same perplexity as with the<br />
n-gram model that is trained <strong>on</strong> all data.<br />
78




