

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Perplexity<br />
360<br />
340<br />
320<br />
300<br />
280<br />
260<br />
240<br />
220<br />
200<br />
180<br />
0 2 4 6 8 10 12 14<br />
Epoch<br />
ALL-Natural<br />
ALL-Stochastic<br />
Reduced-Sorted<br />
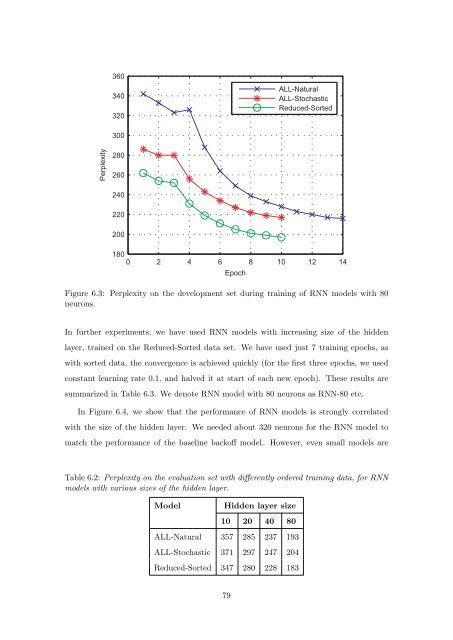
Figure 6.3: Perplexity <strong>on</strong> the development set during training <strong>of</strong> RNN models with 80<br />
neur<strong>on</strong>s.<br />
In further experiments, we have used RNN models with increasing size <strong>of</strong> the hidden<br />
layer, trained <strong>on</strong> the Reduced-Sorted data set. We have used just 7 training epochs, as<br />
with sorted data, the c<strong>on</strong>vergence is achieved quickly (for the first three epochs, we used<br />
c<strong>on</strong>stant learning rate 0.1, and halved it at start <strong>of</strong> each new epoch). These results are<br />
summarized in Table 6.3. We denote RNN model with 80 neur<strong>on</strong>s as RNN-80 etc.<br />
In Figure 6.4, we show that the performance <strong>of</strong> RNN models is str<strong>on</strong>gly correlated<br />
with the size <strong>of</strong> the hidden layer. We needed about 320 neur<strong>on</strong>s for the RNN model to<br />
match the performance <strong>of</strong> the baseline back<strong>of</strong>f model. However, even small models are<br />
Table 6.2: Perplexity <strong>on</strong> the evaluati<strong>on</strong> set with differently ordered training data, for RNN<br />
models with various sizes <strong>of</strong> the hidden layer.<br />
Model Hidden layer size<br />
10 20 40 80<br />
ALL-Natural 357 285 237 193<br />
ALL-Stochastic 371 297 247 204<br />
Reduced-Sorted 347 280 228 183<br />
79




