

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
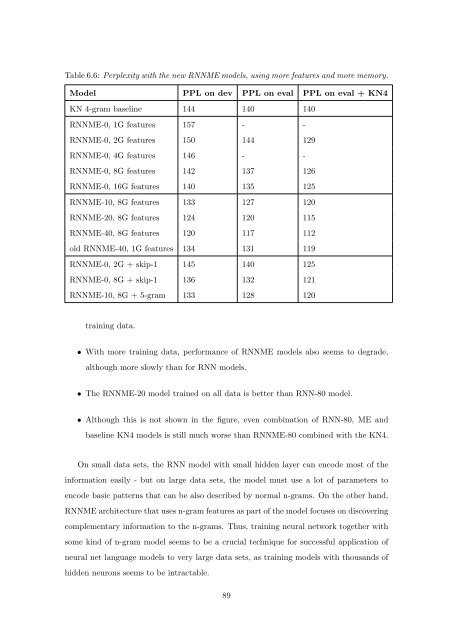
Table 6.6: Perplexity with the new RNNME models, using more features and more memory.<br />
Model PPL <strong>on</strong> dev PPL <strong>on</strong> eval PPL <strong>on</strong> eval + KN4<br />
KN 4-gram baseline 144 140 140<br />
RNNME-0, 1G features 157 - -<br />
RNNME-0, 2G features 150 144 129<br />
RNNME-0, 4G features 146 - -<br />
RNNME-0, 8G features 142 137 126<br />
RNNME-0, 16G features 140 135 125<br />
RNNME-10, 8G features 133 127 120<br />
RNNME-20, 8G features 124 120 115<br />
RNNME-40, 8G features 120 117 112<br />
old RNNME-40, 1G features 134 131 119<br />
RNNME-0, 2G + skip-1 145 140 125<br />
RNNME-0, 8G + skip-1 136 132 121<br />
RNNME-10, 8G + 5-gram 133 128 120<br />
training data.<br />
• With more training data, performance <strong>of</strong> RNNME models also seems to degrade,<br />
although more slowly than for RNN models.<br />
• The RNNME-20 model trained <strong>on</strong> all data is better than RNN-80 model.<br />
• Although this is not shown in the figure, even combinati<strong>on</strong> <strong>of</strong> RNN-80, ME and<br />
baseline KN4 models is still much worse than RNNME-80 combined with the KN4.<br />
On small data sets, the RNN model with small hidden layer can encode most <strong>of</strong> the<br />
informati<strong>on</strong> easily - but <strong>on</strong> large data sets, the model must use a lot <strong>of</strong> parameters to<br />
encode basic patterns that can be also described by normal n-grams. On the other hand,<br />
RNNME architecture that uses n-gram features as part <strong>of</strong> the model focuses <strong>on</strong> discovering<br />
complementary informati<strong>on</strong> to the n-grams. Thus, training neural network together with<br />
some kind <strong>of</strong> n-gram model seems to be a crucial technique for successful applicati<strong>on</strong> <strong>of</strong><br />
neural net language models to very large data sets, as training models with thousands <strong>of</strong><br />
hidden neur<strong>on</strong>s seems to be intractable.<br />
89




