

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Entropy reducti<strong>on</strong> per word over KN4 [bits]<br />
0<br />
-0.1<br />
-0.2<br />
-0.3<br />
-0.4<br />
-0.5<br />
-0.6<br />
-0.7<br />
10 1<br />
10 2<br />
Hidden layer size<br />
RNN + KN4<br />
RNNME+KN4<br />
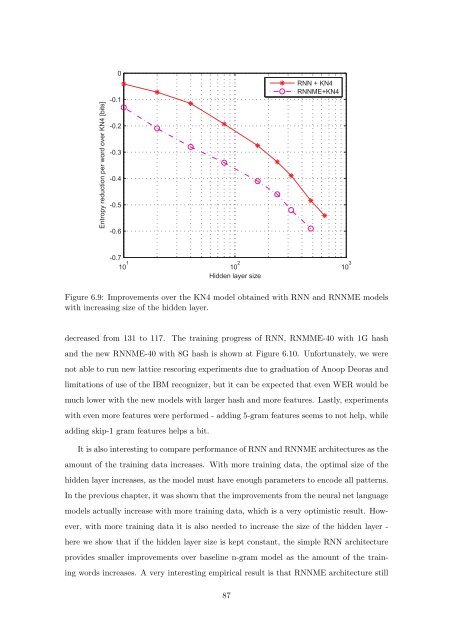
Figure 6.9: Improvements over the KN4 model obtained with RNN and RNNME models<br />
with increasing size <strong>of</strong> the hidden layer.<br />
decreased from 131 to 117. The training progress <strong>of</strong> RNN, RNMME-40 with 1G hash<br />
and the new RNNME-40 with 8G hash is shown at Figure 6.10. Unfortunately, we were<br />
not able to run new lattice rescoring experiments due to graduati<strong>on</strong> <strong>of</strong> Anoop Deoras and<br />
limitati<strong>on</strong>s <strong>of</strong> use <strong>of</strong> the IBM recognizer, but it can be expected that even WER would be<br />
much lower with the new models with larger hash and more features. Lastly, experiments<br />
with even more features were performed - adding 5-gram features seems to not help, while<br />
adding skip-1 gram features helps a bit.<br />
It is also interesting to compare performance <strong>of</strong> RNN and RNNME architectures as the<br />
amount <strong>of</strong> the training data increases. With more training data, the optimal size <strong>of</strong> the<br />
hidden layer increases, as the model must have enough parameters to encode all patterns.<br />
In the previous chapter, it was shown that the improvements from the neural net language<br />
models actually increase with more training data, which is a very optimistic result. How-<br />
ever, with more training data it is also needed to increase the size <strong>of</strong> the hidden layer -<br />
here we show that if the hidden layer size is kept c<strong>on</strong>stant, the simple RNN architecture<br />
provides smaller improvements over baseline n-gram model as the amount <strong>of</strong> the train-<br />
ing words increases. A very interesting empirical result is that RNNME architecture still<br />
87<br />
10 3




