

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
WER [%]<br />
12.5<br />
12<br />
11.5<br />
11<br />
10.5<br />
10<br />
9.5<br />
9<br />
10 0<br />
10 1<br />
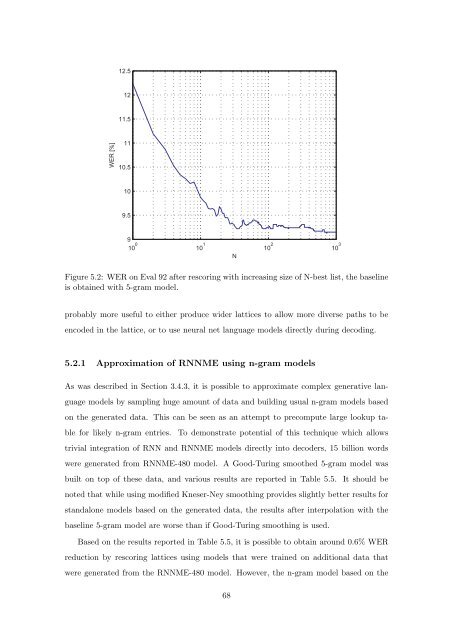
Figure 5.2: WER <strong>on</strong> Eval 92 after rescoring with increasing size <strong>of</strong> N-best list, the baseline<br />
is obtained with 5-gram model.<br />
probably more useful to either produce wider lattices to allow more diverse paths to be<br />
encoded in the lattice, or to use neural net language models directly during decoding.<br />
5.2.1 Approximati<strong>on</strong> <strong>of</strong> RNNME using n-gram models<br />
As was described in Secti<strong>on</strong> 3.4.3, it is possible to approximate complex generative lan-<br />
guage models by sampling huge amount <strong>of</strong> data and building usual n-gram models <str<strong>on</strong>g>based</str<strong>on</strong>g><br />
<strong>on</strong> the generated data. This can be seen as an attempt to precompute large lookup ta-<br />
ble for likely n-gram entries. To dem<strong>on</strong>strate potential <strong>of</strong> this technique which allows<br />
trivial integrati<strong>on</strong> <strong>of</strong> RNN and RNNME models directly into decoders, 15 billi<strong>on</strong> words<br />
were generated from RNNME-480 model. A Good-Turing smoothed 5-gram model was<br />
built <strong>on</strong> top <strong>of</strong> these data, and various results are reported in Table 5.5. It should be<br />
noted that while using modified Kneser-Ney smoothing provides slightly better results for<br />
standal<strong>on</strong>e models <str<strong>on</strong>g>based</str<strong>on</strong>g> <strong>on</strong> the generated data, the results after interpolati<strong>on</strong> with the<br />
baseline 5-gram model are worse than if Good-Turing smoothing is used.<br />
N<br />
Based <strong>on</strong> the results reported in Table 5.5, it is possible to obtain around 0.6% WER<br />
reducti<strong>on</strong> by rescoring lattices using models that were trained <strong>on</strong> additi<strong>on</strong>al data that<br />
were generated from the RNNME-480 model. However, the n-gram model <str<strong>on</strong>g>based</str<strong>on</strong>g> <strong>on</strong> the<br />
68<br />
10 2<br />
10 3




