

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Entropy per word <strong>on</strong> the WSJ test data<br />
9<br />
8.8<br />
8.6<br />
8.4<br />
8.2<br />
8<br />
7.8<br />
7.6<br />
7.4<br />
7.2<br />
7<br />
10 5<br />
10 6<br />
Training tokens<br />
10 7<br />
KN5<br />
KN5+RNN<br />
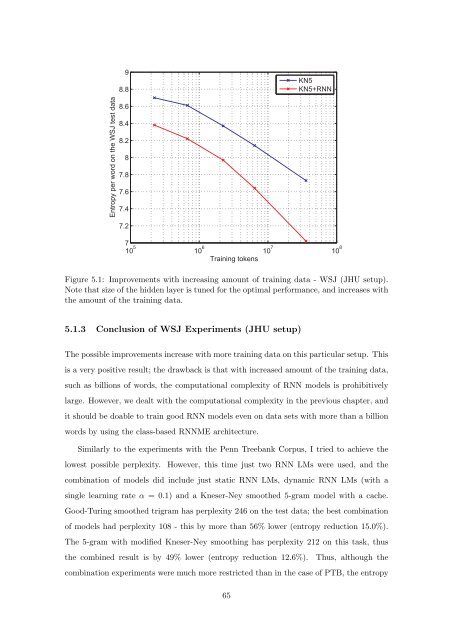
Figure 5.1: Improvements with increasing amount <strong>of</strong> training data - WSJ (JHU setup).<br />
Note that size <strong>of</strong> the hidden layer is tuned for the optimal performance, and increases with<br />
the amount <strong>of</strong> the training data.<br />
5.1.3 C<strong>on</strong>clusi<strong>on</strong> <strong>of</strong> WSJ Experiments (JHU setup)<br />
The possible improvements increase with more training data <strong>on</strong> this particular setup. This<br />
is a very positive result; the drawback is that with increased amount <strong>of</strong> the training data,<br />
such as billi<strong>on</strong>s <strong>of</strong> words, the computati<strong>on</strong>al complexity <strong>of</strong> RNN models is prohibitively<br />
large. However, we dealt with the computati<strong>on</strong>al complexity in the previous chapter, and<br />
it should be doable to train good RNN models even <strong>on</strong> data sets with more than a billi<strong>on</strong><br />
words by using the class-<str<strong>on</strong>g>based</str<strong>on</strong>g> RNNME architecture.<br />
Similarly to the experiments with the Penn Treebank Corpus, I tried to achieve the<br />
lowest possible perplexity. However, this time just two RNN LMs were used, and the<br />
combinati<strong>on</strong> <strong>of</strong> models did include just static RNN LMs, dynamic RNN LMs (with a<br />
single learning rate α = 0.1) and a Kneser-Ney smoothed 5-gram model with a cache.<br />
Good-Turing smoothed trigram has perplexity 246 <strong>on</strong> the test data; the best combinati<strong>on</strong><br />
<strong>of</strong> models had perplexity 108 - this by more than 56% lower (entropy reducti<strong>on</strong> 15.0%).<br />
The 5-gram with modified Kneser-Ney smoothing has perplexity 212 <strong>on</strong> this task, thus<br />
the combined result is by 49% lower (entropy reducti<strong>on</strong> 12.6%). Thus, although the<br />
combinati<strong>on</strong> experiments were much more restricted than in the case <strong>of</strong> PTB, the entropy<br />
65<br />
10 8




