

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
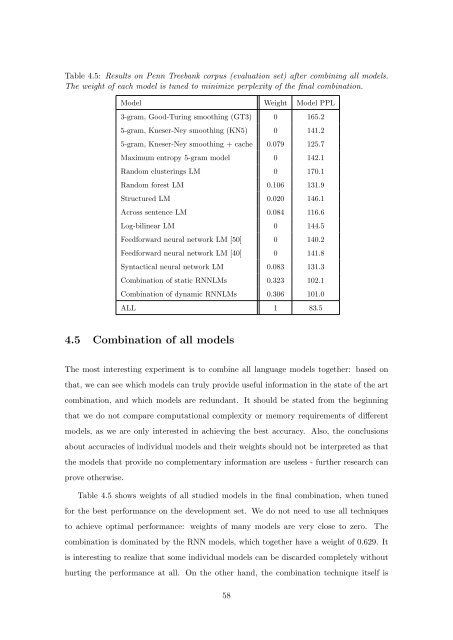
Table 4.5: Results <strong>on</strong> Penn Treebank corpus (evaluati<strong>on</strong> set) after combining all models.<br />
The weight <strong>of</strong> each model is tuned to minimize perplexity <strong>of</strong> the final combinati<strong>on</strong>.<br />
Model Weight Model PPL<br />
3-gram, Good-Turing smoothing (GT3) 0 165.2<br />
5-gram, Kneser-Ney smoothing (KN5) 0 141.2<br />
5-gram, Kneser-Ney smoothing + cache 0.079 125.7<br />
Maximum entropy 5-gram model 0 142.1<br />
Random clusterings LM 0 170.1<br />
Random forest LM 0.106 131.9<br />
Structured LM 0.020 146.1<br />
Across sentence LM 0.084 116.6<br />
Log-bilinear LM 0 144.5<br />
Feedforward neural network LM [50] 0 140.2<br />
Feedforward neural network LM [40] 0 141.8<br />
Syntactical neural network LM 0.083 131.3<br />
Combinati<strong>on</strong> <strong>of</strong> static RNNLMs 0.323 102.1<br />
Combinati<strong>on</strong> <strong>of</strong> dynamic RNNLMs 0.306 101.0<br />
ALL 1 83.5<br />
4.5 Combinati<strong>on</strong> <strong>of</strong> all models<br />
The most interesting experiment is to combine all language models together: <str<strong>on</strong>g>based</str<strong>on</strong>g> <strong>on</strong><br />
that, we can see which models can truly provide useful informati<strong>on</strong> in the state <strong>of</strong> the art<br />
combinati<strong>on</strong>, and which models are redundant. It should be stated from the beginning<br />
that we do not compare computati<strong>on</strong>al complexity or memory requirements <strong>of</strong> different<br />
models, as we are <strong>on</strong>ly interested in achieving the best accuracy. Also, the c<strong>on</strong>clusi<strong>on</strong>s<br />
about accuracies <strong>of</strong> individual models and their weights should not be interpreted as that<br />
the models that provide no complementary informati<strong>on</strong> are useless - further research can<br />
prove otherwise.<br />
Table 4.5 shows weights <strong>of</strong> all studied models in the final combinati<strong>on</strong>, when tuned<br />
for the best performance <strong>on</strong> the development set. We do not need to use all techniques<br />
to achieve optimal performance: weights <strong>of</strong> many models are very close to zero. The<br />
combinati<strong>on</strong> is dominated by the RNN models, which together have a weight <strong>of</strong> 0.629. It<br />
is interesting to realize that some individual models can be discarded completely without<br />
hurting the performance at all. On the other hand, the combinati<strong>on</strong> technique itself is<br />
58




