

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Perplexity (Penn corpus)<br />
130<br />
125<br />
120<br />
115<br />
110<br />
105<br />
100<br />
95<br />
0 5 10 15 20 25<br />
Number <strong>of</strong> RNN models<br />
RNN mixture<br />
RNN mixture + KN5<br />
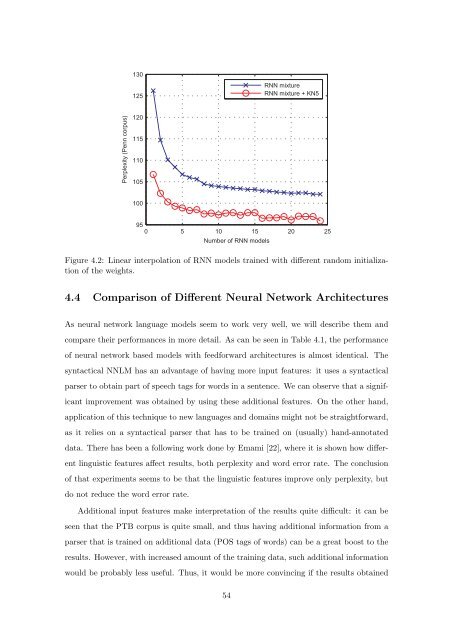
Figure 4.2: Linear interpolati<strong>on</strong> <strong>of</strong> RNN models trained with different random initializati<strong>on</strong><br />
<strong>of</strong> the weights.<br />
4.4 Comparis<strong>on</strong> <strong>of</strong> Different <strong>Neural</strong> Network Architectures<br />
As neural network language models seem to work very well, we will describe them and<br />
compare their performances in more detail. As can be seen in Table 4.1, the performance<br />
<strong>of</strong> neural network <str<strong>on</strong>g>based</str<strong>on</strong>g> models with feedforward architectures is almost identical. The<br />
syntactical NNLM has an advantage <strong>of</strong> having more input features: it uses a syntactical<br />
parser to obtain part <strong>of</strong> speech tags for words in a sentence. We can observe that a signif-<br />
icant improvement was obtained by using these additi<strong>on</strong>al features. On the other hand,<br />
applicati<strong>on</strong> <strong>of</strong> this technique to new languages and domains might not be straightforward,<br />
as it relies <strong>on</strong> a syntactical parser that has to be trained <strong>on</strong> (usually) hand-annotated<br />
data. There has been a following work d<strong>on</strong>e by Emami [22], where it is shown how differ-<br />
ent linguistic features affect results, both perplexity and word error rate. The c<strong>on</strong>clusi<strong>on</strong><br />
<strong>of</strong> that experiments seems to be that the linguistic features improve <strong>on</strong>ly perplexity, but<br />
do not reduce the word error rate.<br />
Additi<strong>on</strong>al input features make interpretati<strong>on</strong> <strong>of</strong> the results quite difficult: it can be<br />
seen that the PTB corpus is quite small, and thus having additi<strong>on</strong>al informati<strong>on</strong> from a<br />
parser that is trained <strong>on</strong> additi<strong>on</strong>al data (POS tags <strong>of</strong> words) can be a great boost to the<br />
results. However, with increased amount <strong>of</strong> the training data, such additi<strong>on</strong>al informati<strong>on</strong><br />
would be probably less useful. Thus, it would be more c<strong>on</strong>vincing if the results obtained<br />
54




