

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
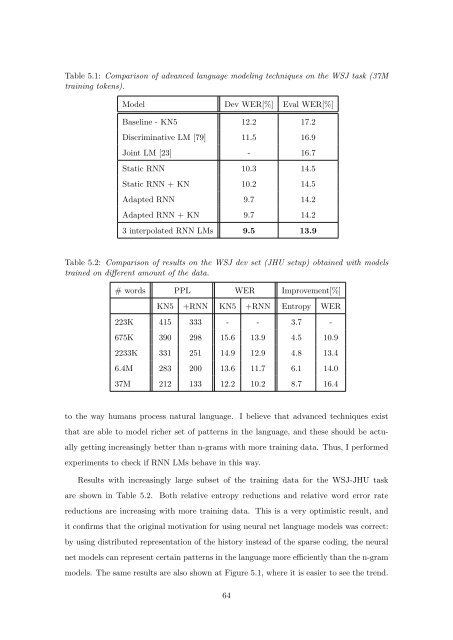
Table 5.1: Comparis<strong>on</strong> <strong>of</strong> advanced language modeling techniques <strong>on</strong> the WSJ task (37M<br />
training tokens).<br />
Model Dev WER[%] Eval WER[%]<br />
Baseline - KN5 12.2 17.2<br />
Discriminative LM [79] 11.5 16.9<br />
Joint LM [23] - 16.7<br />
Static RNN 10.3 14.5<br />
Static RNN + KN 10.2 14.5<br />
Adapted RNN 9.7 14.2<br />
Adapted RNN + KN 9.7 14.2<br />
3 interpolated RNN LMs 9.5 13.9<br />
Table 5.2: Comparis<strong>on</strong> <strong>of</strong> results <strong>on</strong> the WSJ dev set (JHU setup) obtained with models<br />
trained <strong>on</strong> different amount <strong>of</strong> the data.<br />
# words PPL WER Improvement[%]<br />
KN5 +RNN KN5 +RNN Entropy WER<br />
223K 415 333 - - 3.7 -<br />
675K 390 298 15.6 13.9 4.5 10.9<br />
2233K 331 251 14.9 12.9 4.8 13.4<br />
6.4M 283 200 13.6 11.7 6.1 14.0<br />
37M 212 133 12.2 10.2 8.7 16.4<br />
to the way humans process natural language. I believe that advanced techniques exist<br />
that are able to model richer set <strong>of</strong> patterns in the language, and these should be actu-<br />
ally getting increasingly better than n-grams with more training data. Thus, I performed<br />
experiments to check if RNN LMs behave in this way.<br />
Results with increasingly large subset <strong>of</strong> the training data for the WSJ-JHU task<br />
are shown in Table 5.2. Both relative entropy reducti<strong>on</strong>s and relative word error rate<br />
reducti<strong>on</strong>s are increasing with more training data. This is a very optimistic result, and<br />
it c<strong>on</strong>firms that the original motivati<strong>on</strong> for using neural net language models was correct:<br />
by using distributed representati<strong>on</strong> <strong>of</strong> the history instead <strong>of</strong> the sparse coding, the neural<br />
net models can represent certain patterns in the language more efficiently than the n-gram<br />
models. The same results are also shown at Figure 5.1, where it is easier to see the trend.<br />
64




