

Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...
Statistical Language Models based on Neural Networks - Faculty of ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
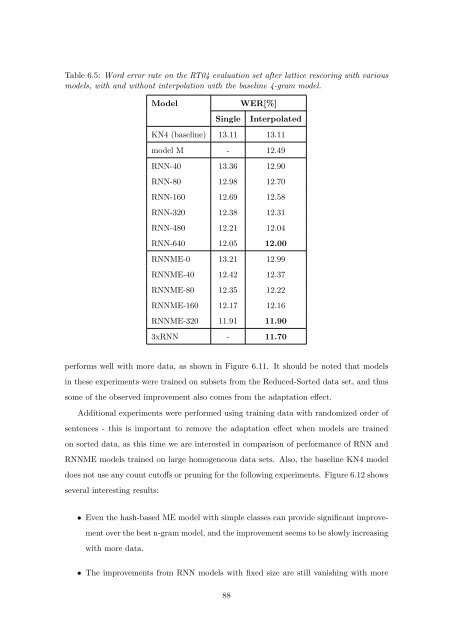
Table 6.5: Word error rate <strong>on</strong> the RT04 evaluati<strong>on</strong> set after lattice rescoring with various<br />
models, with and without interpolati<strong>on</strong> with the baseline 4-gram model.<br />
Model WER[%]<br />
Single Interpolated<br />
KN4 (baseline) 13.11 13.11<br />
model M - 12.49<br />
RNN-40 13.36 12.90<br />
RNN-80 12.98 12.70<br />
RNN-160 12.69 12.58<br />
RNN-320 12.38 12.31<br />
RNN-480 12.21 12.04<br />
RNN-640 12.05 12.00<br />
RNNME-0 13.21 12.99<br />
RNNME-40 12.42 12.37<br />
RNNME-80 12.35 12.22<br />
RNNME-160 12.17 12.16<br />
RNNME-320 11.91 11.90<br />
3xRNN - 11.70<br />
performs well with more data, as shown in Figure 6.11. It should be noted that models<br />
in these experiments were trained <strong>on</strong> subsets from the Reduced-Sorted data set, and thus<br />
some <strong>of</strong> the observed improvement also comes from the adaptati<strong>on</strong> effect.<br />
Additi<strong>on</strong>al experiments were performed using training data with randomized order <strong>of</strong><br />
sentences - this is important to remove the adaptati<strong>on</strong> effect when models are trained<br />
<strong>on</strong> sorted data, as this time we are interested in comparis<strong>on</strong> <strong>of</strong> performance <strong>of</strong> RNN and<br />
RNNME models trained <strong>on</strong> large homogeneous data sets. Also, the baseline KN4 model<br />
does not use any count cut<strong>of</strong>fs or pruning for the following experiments. Figure 6.12 shows<br />
several interesting results:<br />
• Even the hash-<str<strong>on</strong>g>based</str<strong>on</strong>g> ME model with simple classes can provide significant improve-<br />
ment over the best n-gram model, and the improvement seems to be slowly increasing<br />
with more data.<br />
• The improvements from RNN models with fixed size are still vanishing with more<br />
88




