Evaluation of checklists and scales for assessing quality of <strong>non</strong>-<strong>randomised</strong> <strong>studies</strong>24validity approach, different reviewers may chooseto list different methodological characteristics.However, one of the main advantages is that thecoding of study characteristics does not require thesame degree of judgement as when one is requiredto identify the presence of a threat to validity. Forexample, two reviewers might disagree on whetheror not a study is low in power (threat to validity),and yet have perfect agreement when coding theseparate components that make up the decision(e.g. sample size, study design, inherent power ofthe statistical test). 45Cooper 45 advocates that the optimal strategy forcategorising <strong>studies</strong> is a mix of these twoapproaches, that is, coding all potentially relevant,objective aspects of research design as well asspecific threats to validity which may not be fullycaptured by the first approach. Although thisstrategy does not (and could not) remove all of thesubjectivity from the assessment process, it may bethe best way of making assessments of quality asexplicit and objective as possible. It should benoted that inter-rater reliability is likely to befurther diminished where a judgement regardingthe ‘acceptability’ of a given feature is required asopposed to identifying its presence or absence. 52Quality assessment tools developed for thehealthcare literature have followed bothapproaches, but the majority are of the ‘methodsdescription’variety, whether they took the form ofa checklist or a scale. These tools provide a meansof judging the overall quality of a study usingitemised criteria, either qualitatively in the case ofchecklists or quantitatively for scales. 53Alternatively, a component approach can be taken,whereby one or more individual qualitycomponents, such as allocation concealment orblinding, are investigated. However, as Moher andcolleagues have pointed out, “assessing onecomponent of a trial report may provide onlyminimal information about its overall quality”. 53A common criticism of quality assessment tools isthe lack of rationale provided for the particularstudy features that reviewers choose to code 52 andthe inclusion of features unlikely to be related tostudy quality. 44,54 This may in part be due to thelack of empirical evidence for the biases associatedwith inadequately designed <strong>studies</strong> (although suchevidence does exist to some extent forRCTs 21,55,56 ). A further criticism of tools forassessing RCTs is lack of attention to standardscale development techniques, 44 to the extent thatone scale 46 which was developed usingpsychometric principles has been singled out fromother available tools. These principles involve thefollowing steps as laid out by Streiner andNorman: 57 preliminary conceptual decisions; itemgeneration and assessment of face validity; fieldtrials to assess frequency of endorsement,consistency and construct validity; and generationof a refined instrument. However, as Jüni andcolleagues have pointed out, following suchprinciples does not necessarily make a toolsuperior to other available instruments. 23Quality assessment scales in particular have alsobeen heavily criticised for the use of a singlesummary score to estimate study quality, by addingthe scores for each individual item. 58 Greenlandargues that the practice of quality scoring is themost insidious form of bias in meta-analysis as it“subjectively merges objective information witharbitrary judgements in a manner that can obscureimportant sources of heterogeneity among studyresults”. 58 It has since been empiricallydemonstrated that the use of different qualityscales for the assessment of the same trial(s) resultsin different estimates of quality. 21,59 Nevertheless,formal (or systematic) quality assessment,especially of RCTs, is increasingly common. Areview by Moher and colleagues published in 1995identified 25 scales for the quality assessment ofRCTs. 44 Subsequent work by Jüni and colleagueshas identified several more. 23,59In spite of these criticisms, it is largely agreed thatthe assessment of methodological quality shouldbe routine practice in systematic reviews and metaanalyses.Although the majority of methodologicalwork in this area has surrounded the assessment ofRCTs, it is reasonable to suggest that if formalquality assessment of <strong>randomised</strong> controlled trialsis important, then it is doubly so for <strong>non</strong><strong>randomised</strong><strong>studies</strong> owing to the greater degree ofjudgement that is required. The largelyobservational nature of <strong>non</strong>-<strong>randomised</strong> <strong>studies</strong>leads to a much higher susceptibility to bias thanis found for experimental designs, as discussed inChapter 1.A review of existing quality assessment tools for <strong>non</strong><strong>randomised</strong><strong>intervention</strong> <strong>studies</strong> was conducted inorder to provide a description of what is available,paying particular attention to whether and how wellthey cover generally accepted quality domains.MethodsInclusion criteriaTo be considered as a quality assessment tool, a list
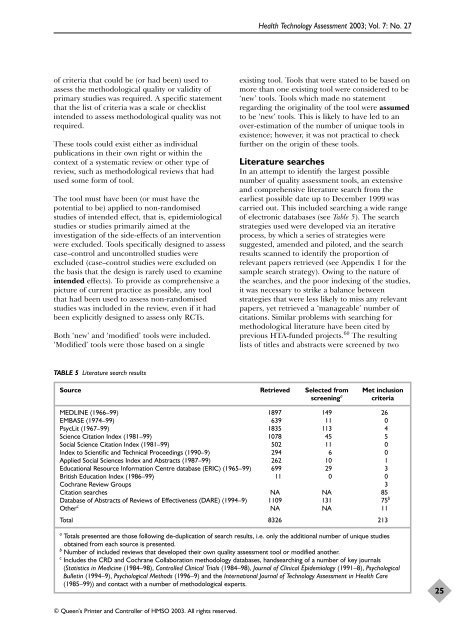
<strong>Health</strong> Technology Assessment 2003; Vol. 7: No. 27of criteria that could be (or had been) used toassess the methodological quality or validity ofprimary <strong>studies</strong> was required. A specific statementthat the list of criteria was a scale or checklistintended to assess methodological quality was notrequired.These tools could exist either as individualpublications in their own right or within thecontext of a systematic review or other type ofreview, such as methodological reviews that hadused some form of tool.The tool must have been (or must have thepotential to be) applied to <strong>non</strong>-<strong>randomised</strong><strong>studies</strong> of intended effect, that is, epidemiological<strong>studies</strong> or <strong>studies</strong> primarily aimed at theinvestigation of the side-effects of an <strong>intervention</strong>were excluded. Tools specifically designed to assesscase–control and uncontrolled <strong>studies</strong> wereexcluded (case–control <strong>studies</strong> were excluded onthe basis that the design is rarely used to examineintended effects). To provide as comprehensive apicture of current practice as possible, any toolthat had been used to assess <strong>non</strong>-<strong>randomised</strong><strong>studies</strong> was included in the review, even if it hadbeen explicitly designed to assess only RCTs.Both ‘new’ and ‘modified’ tools were included.‘Modified’ tools were those based on a singleexisting tool. Tools that were stated to be based onmore than one existing tool were considered to be‘new’ tools. Tools which made no statementregarding the originality of the tool were assumedto be ‘new’ tools. This is likely to have led to anover-estimation of the number of unique tools inexistence; however, it was not practical to checkfurther on the origin of these tools.Literature searchesIn an attempt to identify the largest possiblenumber of quality assessment tools, an extensiveand comprehensive literature search from theearliest possible date up to December 1999 wascarried out. This included searching a wide rangeof electronic databases (see Table 5). The searchstrategies used were developed via an iterativeprocess, by which a series of strategies weresuggested, amended and piloted, and the searchresults scanned to identify the proportion ofrelevant papers retrieved (see Appendix 1 for thesample search strategy). Owing to the nature ofthe searches, and the poor indexing of the <strong>studies</strong>,it was necessary to strike a balance betweenstrategies that were less likely to miss any relevantpapers, yet retrieved a ‘manageable’ number ofcitations. Similar problems with searching formethodological literature have been cited byprevious HTA-funded projects. 60 The resultinglists of titles and abstracts were screened by twoTABLE 5 Literature search resultsSource Retrieved Selected from Met inclusionscreening a criteriaMEDLINE (1966–99) 1897 149 26EMBASE (1974–99) 639 11 0PsycLit (1967–99) 1835 113 4Science Citation Index (1981–99) 1078 45 5Social Science Citation Index (1981–99) 502 11 0Index to Scientific and Technical Proceedings (1990–9) 294 6 0Applied Social Sciences Index and Abstracts (1987–99) 262 10 1Educational Resource Information Centre database (ERIC) (1965–99) 699 29 3British Education Index (1986–99) 11 0 0Cochrane Review Groups 3Citation searches NA NA 85Database of Abstracts of Reviews of Effectiveness (DARE) (1994–9) 1109 131 75 bOther c NA NA 11Total 8326 213a Totals presented are those following de-duplication of search results, i.e. only the additional number of unique <strong>studies</strong>obtained from each source is presented.b Number of included reviews that developed their own quality assessment tool or modified another.c Includes the CRD and Cochrane Collaboration methodology databases, handsearching of a number of key journals(Statistics in Medicine (1984–98), Controlled Clinical Trials (1984–98), Journal of Clinical Epidemiology (1991–8), PsychologicalBulletin (1994–9), Psychological Methods (1996–9) and the International Journal of Technology Assessment in <strong>Health</strong> Care(1985–99)) and contact with a number of methodological experts.25© Queen’s Printer and Controller of HMSO 2003. All rights reserved.