

Statistik I
Statistik I
Statistik I

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
Annahme: wahres Ergebnis in der Bevölkerung normalverteilt mit<br />
Mittel = 100 und SD = 15;<br />
⇒ Zufallsfehler = ± 5<br />
beobachtet: 140<br />
kann sein: 135 + 5 oder 145 − 5<br />
135<br />
145<br />
aber es gibt mehr Leute mit ≈ 135 als wahrem Ergebnis<br />
⇒ Durchschnitt der „Gruppe 140“ wird bei Wiederholung niedriger<br />
liegen<br />
f) Regressionsfehlschluß<br />
Annahme, daß der Regressionseffekt eine „wirkliche“ Ursache hat.<br />
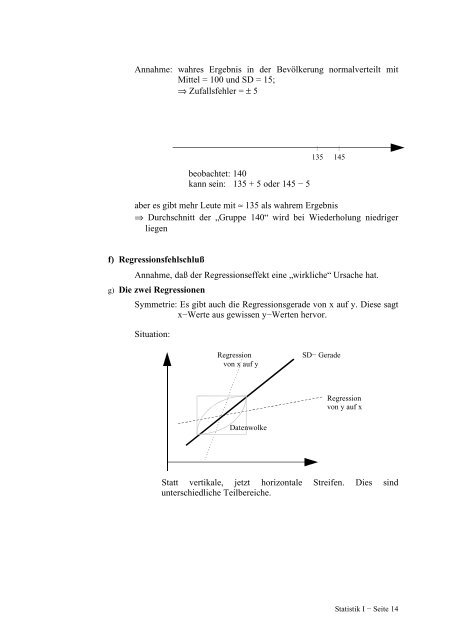
g) Die zwei Regressionen<br />
Symmetrie: Es gibt auch die Regressionsgerade von x auf y. Diese sagt<br />
x−Werte aus gewissen y−Werten hervor.<br />
Situation:<br />
Regression SD− Gerade<br />
von x auf y<br />
Datenwolke<br />
Regression<br />
von y auf x<br />
Statt vertikale, jetzt horizontale Streifen. Dies sind<br />
unterschiedliche Teilbereiche.<br />
<strong>Statistik</strong> I − Seite 14












