

DARPA ULTRALOG Final Report - Industrial and Manufacturing ...
DARPA ULTRALOG Final Report - Industrial and Manufacturing ...
DARPA ULTRALOG Final Report - Industrial and Manufacturing ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
A DI value greater than one implies that the particular<br />
parameter can help in discriminating between the situations<br />
(more discrimination power). We calculated DI values for<br />
38 behavioral parameters <strong>and</strong> selected those parameters with<br />
DI values larger than one. This resulted in 10 parameters,<br />
comprising of eight statistical <strong>and</strong> two deterministic<br />
parameters, as shown in Table III. ‘# of events’ from ‘Task<br />
Arrival’ <strong>and</strong> ‘Time to Solution’ was the most discriminating<br />
behavioral parameter. Note that ‘# of events’ is the same for<br />
both time series’ as arrived tasks are processed.<br />
TABLE III<br />
DISCRIMINABILITY INDEX OF BEHAVIORAL PARAMETERS<br />
Rank DI Time Series Parameter<br />
1 2477.5 Task Arrival/Time to Solution # of events<br />
2 5.7 Time to Solution(G) Variance<br />
3 5.1 Time to Solution(G) Radius<br />
4 4.4 Time to Solution(G) Average<br />
5 4.2 Time to Solution(G) Maximum<br />
6 2.9 Queue length # of events<br />
7 2.8 Queue length Maximum<br />
8 2.2 Queue length AMI<br />
9 1.2 Queue length Average<br />
10 1.1 Time to Solution(C) L_Expo<br />
(G): Generation, (C): Completion<br />
V. SITUATION IDENTIFICATION<br />
Results from preliminary experimentation shows that 10<br />
of the 38 behavioral parameters have better discriminating<br />
power in the stress space. By using them as features we<br />
identify the stress situations using k-nearest neighbor<br />
classification algorithm.<br />
A. k-nearest neighbor algorithm<br />
k-nearest neighbor algorithm, one of the instance-based<br />
learning methods, is conceptually straightforward. The<br />
summary reported here is based on [14]. In this algorithm<br />
learning is simply storing the training instances, in which<br />
each instance corresponds to a point in the n-dimensional<br />
feature space. Given a new query instance k nearest<br />
neighbors are retrieved from memory <strong>and</strong> used to classify<br />
the new query instance. The nearest neighbors of an instance<br />
are defined in terms of the st<strong>and</strong>ard Euclidean distance. One<br />
problem in this algorithm is the sensitivity to noise axes in<br />
high dimensional problems. One possible solution would be<br />
to normalize each feature. However, normalization does not<br />
resolve this problem because Euclidean distance can become<br />
very noisy for high dimensional problems where only a few<br />
of the features carry classification information. The solution<br />
to this problem is to modify the Euclidean metric by a set of<br />
weights that represents the information content or goodness<br />
of each feature. Therefore, given a set of weights w the<br />
distance between two normalized instances x i <strong>and</strong> x j with m<br />
features can be calculated as in (2).<br />
m<br />
∑<br />
d( x , x ) = w[<br />
k](<br />
x [ k]<br />
− x [ k])<br />
(2)<br />
i<br />
j<br />
k = 1<br />
B. Empirical results<br />
i<br />
We performed 200 experiments with the same<br />
experimental configuration as in Fig. 2 to construct the<br />
database of training instances. Each training instance is<br />
represented with the 10 behavioral parameters. In this<br />
experimentation each agent’s OpTempo (Low/High) <strong>and</strong> the<br />
number of agent 1 (0/1/2) are r<strong>and</strong>omly chosen. Given a<br />
new instance we select 20 nearest neighbors (10% of the<br />
population of training instances) from the database <strong>and</strong><br />
estimate the stress situations of the agents in the society by<br />
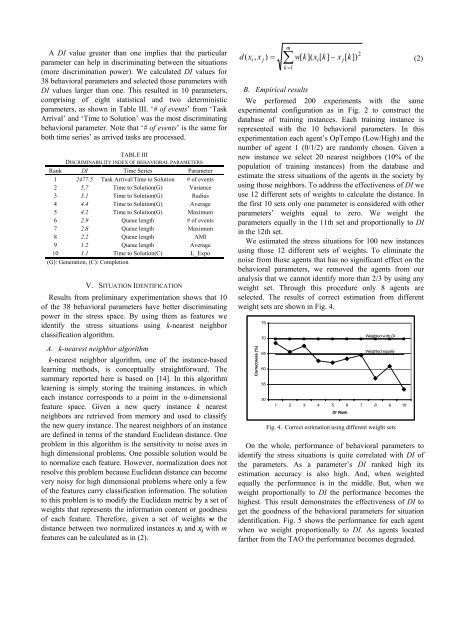
using those neighbors. To address the effectiveness of DI we<br />
use 12 different sets of weights to calculate the distance. In<br />
the first 10 sets only one parameter is considered with other<br />
parameters’ weights equal to zero. We weight the<br />
parameters equally in the 11th set <strong>and</strong> proportionally to DI<br />
in the 12th set.<br />
We estimated the stress situations for 100 new instances<br />
using those 12 different sets of weights. To eliminate the<br />
noise from those agents that has no significant effect on the<br />
behavioral parameters, we removed the agents from our<br />
analysis that we cannot identify more than 2/3 by using any<br />
weight set. Through this procedure only 8 agents are<br />
selected. The results of correct estimation from different<br />
weight sets are shown in Fig. 4.<br />
Correctness (%)<br />
75<br />
70<br />
65<br />
60<br />
55<br />
50<br />
1 2 3 4 5 6 7 8 9 10<br />
On the whole, performance of behavioral parameters to<br />
identify the stress situations is quite correlated with DI of<br />
the parameters. As a parameter’s DI ranked high its<br />
estimation accuracy is also high. And, when weighted<br />
equally the performance is in the middle. But, when we<br />
weight proportionally to DI the performance becomes the<br />
highest. This result demonstrates the effectiveness of DI to<br />
get the goodness of the behavioral parameters for situation<br />
identification. Fig. 5 shows the performance for each agent<br />
when we weight proportionally to DI. As agents located<br />
farther from the TAO the performance becomes degraded.<br />
j<br />
DI Rank<br />
2<br />
Weighted w ith DI<br />
Weighted equally<br />
Fig. 4. Correct estimation using different weight sets














