1036 THEORY AND PRACTICE IN LANGUAGE STUDIESdictionary mak<strong>in</strong>g <strong>and</strong> his pioneer<strong>in</strong>g work on corpus research (S<strong>in</strong>clair 1987, 1991, 2004) have been the start<strong>in</strong>g po<strong>in</strong>tfor many corpus-based approaches to language teach<strong>in</strong>g. Coxhead (2000) noted that vocabulary has been a major areaof corpus-based research <strong>in</strong>to academic language. Lam (2001) observed that academic or semi-technical vocabularydemonstrated semantic dist<strong>in</strong>ctions when occurr<strong>in</strong>g <strong>in</strong> general texts. Her recommendation was that such lexical termsshould be presented as a glossary of academic vocabulary with <strong>in</strong>formation of frequency of occurrences based on aspecialized corpus.In spite of a wide range of uses for the corpora, the right quality <strong>and</strong> type of the corpus has been the subject ofargumentation. Todd (2003), for <strong>in</strong>stance, made a strong case <strong>in</strong> the literature for the use of specialized corpora <strong>in</strong> ESPsett<strong>in</strong>gs (typically us<strong>in</strong>g much smaller corpora than those compiled for general reference purposes, such as the BNC).Tribble (2010, p.15) observed, „„if one wishes to <strong>in</strong>vestigate the lexis of a particular content doma<strong>in</strong> (e.g., health) aspecialist micro-corpus can often be much more useful than a much larger general corpus.‟‟ Similarly, Hafner &C<strong>and</strong>l<strong>in</strong> (2007) suggested that specialized corpora created for a particular purpose are better suited to underst<strong>and</strong><strong>in</strong>gcharacteristic lexical <strong>and</strong> grammatical features of academic or professional discourse than general reference corpora.On the other h<strong>and</strong>, there are arguments aga<strong>in</strong>st usefulness of the academic word list (AWL). Hyl<strong>and</strong> (2002, 2006)highlighted the complexities <strong>in</strong>volved <strong>in</strong> the <strong>in</strong>tricate dist<strong>in</strong>ctions <strong>in</strong> the communication patterns across discipl<strong>in</strong>es,rhetorical patterns, <strong>and</strong> even <strong>in</strong>tra-discipl<strong>in</strong>ary conventions characteriz<strong>in</strong>g the dom<strong>in</strong>ant patterns of scientificargumentation (see e.g. Samraj, 2002). Martínez, Beck & Panza (2009) believe thatDespite this important coverage, the efficiency of the AWL as an <strong>in</strong>strument for the development of academicvocabulary <strong>in</strong> specific purpose courses has been questioned recently, as it has been demonstrated that the lexicaldifferences that exist across dist<strong>in</strong>ct discipl<strong>in</strong>es may be greater than the similarities (p. 184).There is still another l<strong>in</strong>e of argument that doubts the efficacy of academic vocabulary. Chen & Ge, 2007, Hyl<strong>and</strong> &Tse, 2007, <strong>and</strong> Paquot (2007) all question the usefulness of the Academic Word List <strong>in</strong> ESP on the grounds that theacademic words are just too general <strong>and</strong> might be a source of overexposure for the learners who are expected to needmore specialized vocabulary.Other corpus-based studies have used various statistical measures to categorize collocations <strong>and</strong> word groups.Kennedy (2003) could identify most frequently occurr<strong>in</strong>g amplifiers (degree adverbs) <strong>in</strong> the British National Corpus(BNC). Nelson (2000) could identify bus<strong>in</strong>ess-related words regard<strong>in</strong>g their occurrence <strong>and</strong> frequency <strong>in</strong> BNC. Ratherthan pre-label<strong>in</strong>g the words as general, academic or specialized, this methodology not only provides an open-endedsupply of language data adapted to the learner‟s needs rather than simply a st<strong>and</strong>ard set of examples, but also promotesa learner-centered approach br<strong>in</strong>g<strong>in</strong>g flexibility of time <strong>and</strong> place <strong>and</strong> a discovery approach to learn<strong>in</strong>g (Krishnamurthy& Kosem, 2007).Follow<strong>in</strong>g the trend of studies <strong>in</strong> the literature, the present study addresses the issue of lexical words <strong>in</strong> psychologyresearch articles regard<strong>in</strong>g their frequency <strong>and</strong> a contextualized quantification of their difficulty level by concordanc<strong>in</strong>gtool. More specifically, the follow<strong>in</strong>g research questions were posed:R.Q. 1: What vocabulary items are typically used with a higher frequency <strong>in</strong> psychology research article<strong>in</strong>troductions?R.Q.2: Which sequential order of <strong>in</strong>struction can be derived from the psychology <strong>in</strong>troduction corpus?II. METHODA. MaterialsOur corpus consisted of 200 articles <strong>in</strong>troductions chosen r<strong>and</strong>omly from among 400 psychology research articlesus<strong>in</strong>g Science Direct <strong>and</strong> Oxford Journals data bases which were accessed through Central Library, University of Tabrizfrom December 2011 to September 2012. The articles had been published between the years 1998 to 2011.B. InstrumentationConcordanc<strong>in</strong>g tools are the key <strong>in</strong>struments for analyz<strong>in</strong>g corpora. A concordance is a list of occurrences (all or aselected number) of a word or a phrase <strong>in</strong> a corpus. The concordancer generally lays these occurrences out on the page(or on the computer screen) by the search word or phrase <strong>in</strong> the middle <strong>and</strong> 40-50 characters of context on both sides ofit. This layout is called KWIC (key word <strong>in</strong> context). In the KWIC format, a concordance highlights recurrentcomb<strong>in</strong>ations of the key word (the search word) <strong>in</strong> the middle with words or expressions around it. Any concordanc<strong>in</strong>gsoftware produces more or less the type of output to make statistical calculations (e.g. which words are most frequent <strong>in</strong>a corpus). The software that is used <strong>in</strong> this study is CONC330 which can makes wordlists <strong>and</strong> concordances from yourelectronic texts. The software used here (CONC330) has the follow<strong>in</strong>g features: a) mak<strong>in</strong>g wordlists, word frequencylists, <strong>and</strong> <strong>in</strong>dexes, b) mak<strong>in</strong>g full concordances to texts of any size, limited only by available disk space <strong>and</strong> memory, c)Make concordances straight from text, among many others.C. ProceduresFirst of all, twenty top frequency lexical words were chosen for frequency <strong>and</strong> determ<strong>in</strong><strong>in</strong>g the <strong>in</strong>structional order.This number of lexical words as the focus of the study was because most EP teachers who were consulted agreed that© 2013 ACADEMY PUBLISHER
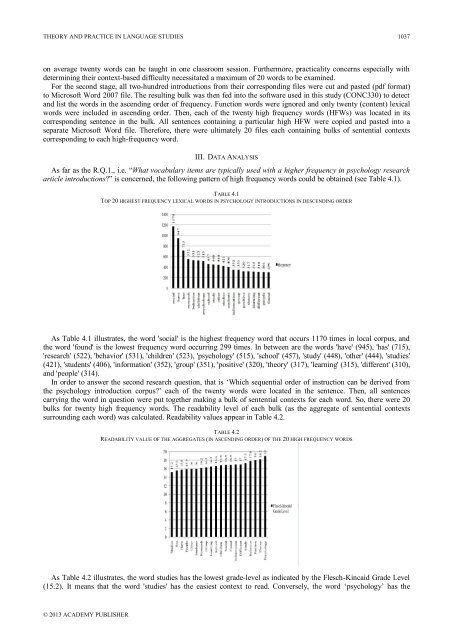
THEORY AND PRACTICE IN LANGUAGE STUDIES 1037on average twenty words can be taught <strong>in</strong> one classroom session. Furthermore, practicality concerns especially withdeterm<strong>in</strong><strong>in</strong>g their context-based difficulty necessitated a maximum of 20 words to be exam<strong>in</strong>ed.For the second stage, all two-hundred <strong>in</strong>troductions from their correspond<strong>in</strong>g files were cut <strong>and</strong> pasted (pdf format)to Microsoft Word 2007 file. The result<strong>in</strong>g bulk was then fed <strong>in</strong>to the software used <strong>in</strong> this study (CONC330) to detect<strong>and</strong> list the words <strong>in</strong> the ascend<strong>in</strong>g order of frequency. Function words were ignored <strong>and</strong> only twenty (content) lexicalwords were <strong>in</strong>cluded <strong>in</strong> ascend<strong>in</strong>g order. Then, each of the twenty high frequency words (HFWs) was located <strong>in</strong> itscorrespond<strong>in</strong>g sentence <strong>in</strong> the bulk. All sentences conta<strong>in</strong><strong>in</strong>g a particular high HFW were copied <strong>and</strong> pasted <strong>in</strong>to aseparate Microsoft Word file. Therefore, there were ultimately 20 files each conta<strong>in</strong><strong>in</strong>g bulks of sentential contextscorrespond<strong>in</strong>g to each high-frequency word.III. DATA ANALYSISAs far as the R.Q.1., i.e. “What vocabulary items are typically used with a higher frequency <strong>in</strong> psychology researcharticle <strong>in</strong>troductions?” is concerned, the follow<strong>in</strong>g pattern of high frequency words could be obta<strong>in</strong>ed (see Table 4.1).TABLE 4.1TOP 20 HIGHEST FREQUENCY LEXICAL WORDS IN PSYCHOLOGY INTRODUCTIONS IN DESCENDING ORDERAs Table 4.1 illustrates, the word 'social' is the highest frequency word that occurs 1170 times <strong>in</strong> local corpus, <strong>and</strong>the word 'found' is the lowest frequency word occurr<strong>in</strong>g 299 times. In between are the words 'have' (945), 'has' (715),'research' (522), 'behavior' (531), 'children' (523), 'psychology' (515), 'school' (457), 'study' (448), 'other' (444), 'studies'(421), 'students' (406), '<strong>in</strong>formation' (352), 'group' (351), 'positive' (320), 'theory' (317), 'learn<strong>in</strong>g' (315), 'different' (310),<strong>and</strong> 'people' (314).In order to answer the second research question, that is „Which sequential order of <strong>in</strong>struction can be derived fromthe psychology <strong>in</strong>troduction corpus?‟ each of the twenty words were located <strong>in</strong> the sentence. Then, all sentencescarry<strong>in</strong>g the word <strong>in</strong> question were put together mak<strong>in</strong>g a bulk of sentential contexts for each word. So, there were 20bulks for twenty high frequency words. The readability level of each bulk (as the aggregate of sentential contextssurround<strong>in</strong>g each word) was calculated. Readability values appear <strong>in</strong> Table 4.2.TABLE 4.2READABILITY VALUE OF THE AGGREGATES (IN ASCENDING ORDER) OF THE 20 HIGH FREQUENCY WORDSAs Table 4.2 illustrates, the word studies has the lowest grade-level as <strong>in</strong>dicated by the Flesch-K<strong>in</strong>caid Grade Level(15.2). It means that the word 'studies' has the easiest context to read. Conversely, the word „psychology‟ has the© 2013 ACADEMY PUBLISHER