ISCTE – ESCOLA DE GESTÃO - Universidade Técnica de Lisboa
ISCTE – ESCOLA DE GESTÃO - Universidade Técnica de Lisboa
ISCTE – ESCOLA DE GESTÃO - Universidade Técnica de Lisboa

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
250000<br />
200000<br />
150000<br />
100000<br />
50000<br />
0<br />
T5 T6 T7<br />
MW 1330 14640 161050<br />
MW+ST 1110 11110 111110<br />
MW+SC 1330 14640 226210<br />
MW+ST+SC 1110 11110 124960<br />
140000<br />
120000<br />
100000<br />
80000<br />
60000<br />
40000<br />
20000<br />
0<br />
Leituras<br />
Escritas<br />
T5 T6 T7<br />
MW 836 9596 66006<br />
MW+ST 616 6066 16066<br />
MW+SC 836 9596 126211<br />
MW+ST+SC 616 6066 24961<br />
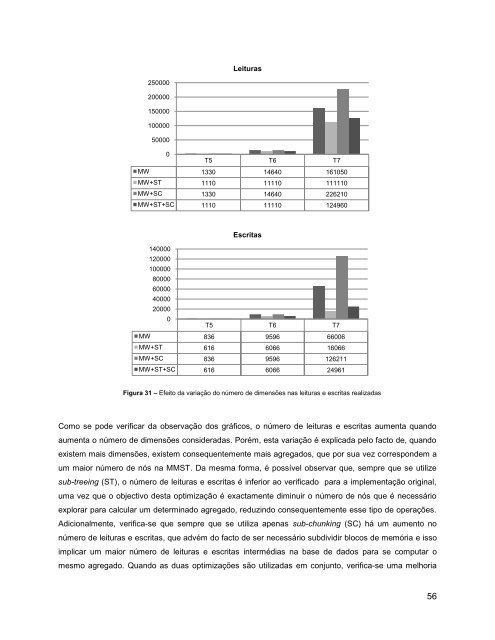
Figura 31 <strong>–</strong> Efeito da variação do número <strong>de</strong> dimensões nas leituras e escritas realizadas<br />
Como se po<strong>de</strong> verificar da observação dos gráficos, o número <strong>de</strong> leituras e escritas aumenta quando<br />
aumenta o número <strong>de</strong> dimensões consi<strong>de</strong>radas. Porém, esta variação é explicada pelo facto <strong>de</strong>, quando<br />
existem mais dimensões, existem consequentemente mais agregados, que por sua vez correspon<strong>de</strong>m a<br />
um maior número <strong>de</strong> nós na MMST. Da mesma forma, é possível observar que, sempre que se utilize<br />
sub-treeing (ST), o número <strong>de</strong> leituras e escritas é inferior ao verificado para a implementação original,<br />
uma vez que o objectivo <strong>de</strong>sta optimização é exactamente diminuir o número <strong>de</strong> nós que é necessário<br />
explorar para calcular um <strong>de</strong>terminado agregado, reduzindo consequentemente esse tipo <strong>de</strong> operações.<br />
Adicionalmente, verifica-se que sempre que se utiliza apenas sub-chunking (SC) há um aumento no<br />
número <strong>de</strong> leituras e escritas, que advém do facto <strong>de</strong> ser necessário subdividir blocos <strong>de</strong> memória e isso<br />
implicar um maior número <strong>de</strong> leituras e escritas intermédias na base <strong>de</strong> dados para se computar o<br />
mesmo agregado. Quando as duas optimizações são utilizadas em conjunto, verifica-se uma melhoria<br />
56