

2013 09 22 20010 Projektbericht 5 Bezirke Berlin_final - SFBB
2013 09 22 20010 Projektbericht 5 Bezirke Berlin_final - SFBB
2013 09 22 20010 Projektbericht 5 Bezirke Berlin_final - SFBB

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
Bestimmung steuerungsrelevanter Wirkungsindikatoren HzE in <strong>Berlin</strong> (5 <strong>Bezirke</strong>)<br />
Abschlussbericht für das Gesamtprojekt Wirkungsevaluation (2010 bis <strong>2013</strong>)<br />
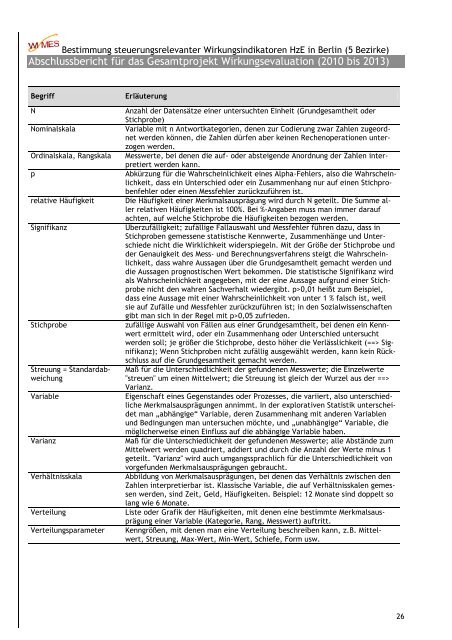
Begriff<br />
N<br />
Nominalskala<br />
Ordinalskala, Rangskala<br />
p<br />
relative Häufigkeit<br />
Signifikanz<br />
Stichprobe<br />
Streuung = Standardabweichung<br />
Variable<br />
Varianz<br />
Verhältnisskala<br />
Verteilung<br />
Verteilungsparameter<br />
Erläuterung<br />
Anzahl der Datensätze einer untersuchten Einheit (Grundgesamtheit oder<br />
Stichprobe)<br />
Variable mit n Antwortkategorien, denen zur Codierung zwar Zahlen zugeordnet<br />
werden können, die Zahlen dürfen aber keinen Rechenoperationen unterzogen<br />
werden.<br />
Messwerte, bei denen die auf- oder absteigende Anordnung der Zahlen interpretiert<br />
werden kann.<br />
Abkürzung für die Wahrscheinlichkeit eines Alpha-Fehlers, also die Wahrscheinlichkeit,<br />
dass ein Unterschied oder ein Zusammenhang nur auf einen Stichprobenfehler<br />
oder einen Messfehler zurückzuführen ist.<br />
Die Häufigkeit einer Merkmalsausprägung wird durch N geteilt. Die Summe aller<br />
relativen Häufigkeiten ist 100%. Bei %-Angaben muss man immer darauf<br />
achten, auf welche Stichprobe die Häufigkeiten bezogen werden.<br />
Überzufälligkeit; zufällige Fallauswahl und Messfehler führen dazu, dass in<br />
Stichproben gemessene statistische Kennwerte, Zusammenhänge und Unterschiede<br />
nicht die Wirklichkeit widerspiegeln. Mit der Größe der Stichprobe und<br />
der Genauigkeit des Mess- und Berechnungsverfahrens steigt die Wahrscheinlichkeit,<br />
dass wahre Aussagen über die Grundgesamtheit gemacht werden und<br />
die Aussagen prognostischen Wert bekommen. Die statistische Signifikanz wird<br />
als Wahrscheinlichkeit angegeben, mit der eine Aussage aufgrund einer Stichprobe<br />
nicht den wahren Sachverhalt wiedergibt. p>0,01 heißt zum Beispiel,<br />
dass eine Aussage mit einer Wahrscheinlichkeit von unter 1 % falsch ist, weil<br />
sie auf Zufälle und Messfehler zurückzuführen ist; in den Sozialwissenschaften<br />
gibt man sich in der Regel mit p>0,05 zufrieden.<br />
zufällige Auswahl von Fällen aus einer Grundgesamtheit, bei denen ein Kennwert<br />
ermittelt wird, oder ein Zusammenhang oder Unterschied untersucht<br />
werden soll; je größer die Stichprobe, desto höher die Verlässlichkeit (==> Signifikanz);<br />
Wenn Stichproben nicht zufällig ausgewählt werden, kann kein Rückschluss<br />
auf die Grundgesamtheit gemacht werden.<br />
Maß für die Unterschiedlichkeit der gefundenen Messwerte; die Einzelwerte<br />
"streuen" um einen Mittelwert; die Streuung ist gleich der Wurzel aus der ==><br />
Varianz.<br />
Eigenschaft eines Gegenstandes oder Prozesses, die variiert, also unterschiedliche<br />
Merkmalsausprägungen annimmt. In der explorativen Statistik unterscheidet<br />
man „abhängige“ Variable, deren Zusammenhang mit anderen Variablen<br />
und Bedingungen man untersuchen möchte, und „unabhängige“ Variable, die<br />
möglicherweise einen Einfluss auf die abhängige Variable haben.<br />
Maß für die Unterschiedlichkeit der gefundenen Messwerte; alle Abstände zum<br />
Mittelwert werden quadriert, addiert und durch die Anzahl der Werte minus 1<br />
geteilt. "Varianz" wird auch umgangssprachlich für die Unterschiedlichkeit von<br />
vorgefunden Merkmalsausprägungen gebraucht.<br />
Abbildung von Merkmalsausprägungen, bei denen das Verhältnis zwischen den<br />
Zahlen interpretierbar ist. Klassische Variable, die auf Verhältnisskalen gemessen<br />
werden, sind Zeit, Geld, Häufigkeiten. Beispiel: 12 Monate sind doppelt so<br />
lang wie 6 Monate.<br />
Liste oder Grafik der Häufigkeiten, mit denen eine bestimmte Merkmalsausprägung<br />
einer Variable (Kategorie, Rang, Messwert) auftritt.<br />
Kenngrößen, mit denen man eine Verteilung beschreiben kann, z.B. Mittelwert,<br />
Streuung, Max-Wert, Min-Wert, Schiefe, Form usw.<br />
26













