


Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Problem dizajniranja mreže neograničenog kapaciteta<br />
105<br />
⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯<br />
Kao što se može videti iz tabele 6.2 u svim izvršavanjima za instance MA-<br />
MC dobijeno je isto rešenje (NDR). Pri izvršavanju MD instanci samo jednom je<br />
dobijeno rešenje lošije od NDR, a već pri primeni na ME instance veće<br />
dimenzije ovakva rešenja su dobijena u oko 50% slučajeva. Pri tome možemo<br />
uočiti da osim dobijanja rešenja lošijeg kvaliteta raste srednji broj generacija,<br />
kao i odgovarajuće vreme izvršavanja, u odnosu na instance manjih dimenzija.<br />
I pored toga možemo zaključiti da su dobijeni relativno dobri rezultati i da je<br />
GA pogodna metoda za rešavanje ovog problema (UNDP). Uz manje<br />
modifikacije i eventualnu hibridizaciju sa drugim metodama, možemo očekivati<br />
još bolje rezultate.<br />
6.5 Rezultati paralelnog izvršavanja<br />
Kao i u slučaju prethodnog problema i izvršavanje PGANP na UNDP<br />
instancama je izvršeno na istoj lokalnoj mreži. Takođe je Izvršavanje obavljeno<br />
na samo 2 instance manje dimenzije (MA1 i MC1). PGA je na isti način<br />
izvršavan po 10 puta na svakoj od njih, korišćenjem redom 1, 2, 4 i 8 procesora<br />
i takođe primenom virtuelne arhitekture hiperkocke. Jedini izuzetak je instanca<br />
MC1 koja je sa 4 procesora izvršavana 11 puta (u .BAT datoteci je omaškom<br />
ostavljeno jedno izvršavanje više). Kao i pri izvršavanju SPLP instanci, dolazilo<br />
je do tehničkih problema, pa je notiran samo broj uspešnih izvršavanja, i njihovi<br />
rezultati su predstavljeni u tabeli 6.3 .<br />
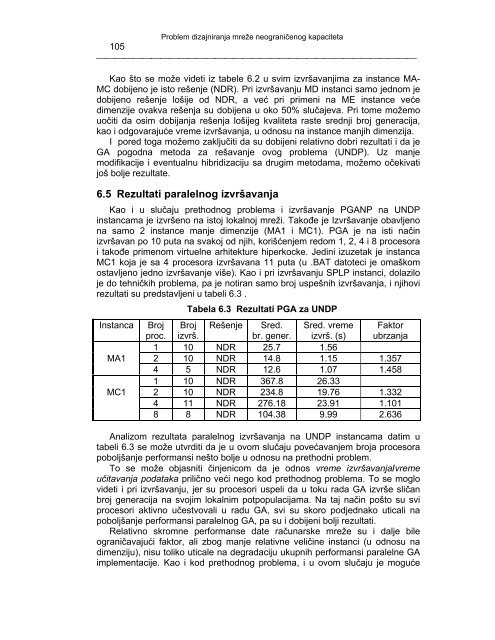
Tabela 6.3 Rezultati PGA za UNDP<br />
Instanca Broj<br />
proc.<br />
Broj<br />
izvrš.<br />
Rešenje Sred.<br />
br. gener.<br />
Sred. vreme<br />
izvrš. (s)<br />
Faktor<br />
ubrzanja<br />
1 10 NDR 25.7 1.56<br />
MA1 2 10 NDR 14.8 1.15 <strong>1.3</strong>57<br />
4 5 NDR 12.6 1.07 1.458<br />
1 10 NDR 367.8 26.33<br />
MC1 2 10 NDR 234.8 19.76 <strong>1.3</strong>32<br />
4 11 NDR 276.18 23.91 1.101<br />
8 8 NDR 104.38 9.99 2.636<br />
Analizom rezultata paralelnog izvršavanja na UNDP instancama datim u<br />
tabeli 6.3 se može utvrditi da je u ovom slučaju povećavanjem broja procesora<br />
poboljšanje performansi nešto bolje u odnosu na prethodni problem.<br />
To se može objasniti činjenicom da je odnos vreme izvršavanja/vreme<br />
učitavanja podataka prilično veći nego kod prethodnog problema. To se moglo<br />
videti i pri izvršavanju, jer su procesori uspeli da u toku <strong>rad</strong>a GA izvrše sličan<br />
broj generacija na svojim lokalnim potpopulacijama. Na taj način pošto su svi<br />
procesori aktivno učestvovali u <strong>rad</strong>u GA, svi su skoro podjednako uticali na<br />
poboljšanje performansi paralelnog GA, pa su i dobijeni bolji rezultati.<br />
Relativno skromne performanse date računarske mreže su i dalje bile<br />
ograničavajući faktor, ali zbog manje relativne veličine instanci (u odnosu na<br />
dimenziju), nisu toliko uticale na deg<strong>rad</strong>aciju ukupnih performansi paralelne GA<br />
implementacije. Kao i kod prethodnog problema, i u ovom slučaju je moguće













