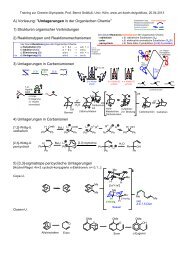
pdf - Universität zu Köln
pdf - Universität zu Köln
pdf - Universität zu Köln

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
So ist die Verbreitung von Doppelnamen relativ hoch. Bei der Beschreibung des Korpus<br />
in Kapitel 5 wird genauer darauf eingegangen. Es existieren aber auch eine Reihe von langen,<br />
aus verschiedenen Stämmen <strong>zu</strong>sammengesetzten Familiennamen. Je nach Benut<strong>zu</strong>ngskontext<br />
einer Phonetischen Suche ist nicht ab<strong>zu</strong>sehen, ob es sich um einen Doppelnamen<br />
(z. B. ) 19 oder einem <strong>zu</strong>sammengesetzten Namen (z. B. )<br />
handelt. Falls der Algorithmus Bindestriche oder Leerzeichen nicht entsprechend behandelt,<br />
ist es mit der jeweiligen Suchanfrage nicht möglich, den jeweils anderen Namen <strong>zu</strong><br />
finden.<br />
Noch komplizierter ist die Lage, wenn die Träger von Doppelnamen in der Datenbank<br />
nur mit einer Namenskomponente bekannt sind. Postel (1969) schlägt vor, sämtliche Namenskomponenten<br />
in allen Permutationen <strong>zu</strong> suchen. Dies ist in der Praxis jedoch schwer<br />
<strong>zu</strong> realisieren, wenn nicht eindeutig klar ist, was ein Doppelname ist und was nicht. Abhilfe<br />
könnte hier eine Silbentrennung und/oder morphologische Segmentierung schaffen. Ohne<br />
größeres Lexikon 20 wäre dies nur mit großer Fehlerquote <strong>zu</strong> realisieren. Fehlerfreier wäre<br />
eine optionale Silbifizierung oder Worttrennung durch den Anwender.<br />
3.6 Bekannte Verfahren für die Phonetische Suche<br />
Die Phonetische Suche ist ein Verfahren, deren erste Varianten schon seit dem letzten<br />
Jahrhundert bekannt sind. Ursprünglich wurden anhand der Schlüssel Karteikarten der<br />
amerikanischen Volkszählung sortiert. Zwar existieren seit den späten sechziger Jahren<br />
Ansätze für die deutsche Sprache, jedoch werden bis in die heutige Zeit hinein vorwiegend<br />
Algorithmen aus dem englichsprachigen Bereich eingesetzt, da der Zugang für Programmierer<br />
durch vielzählige Implementierungen und weite Verbreitung in der Informatikliteratur<br />
für Einsteiger 21 leichter ist.<br />
Es werden vor allem die Algorithmen Soundex, Phonix und Metaphone auch im deutschsprachigen<br />
Bereich eingesetzt, obwohl diese für eine englische/amerikanische Aussprache<br />
entwickelt wurden und somit nur eingeschränkt auf das Deutsche anwendbar sind. Speziell<br />
für die deutsche Sprache konzipiert wurden die ,,<strong>Köln</strong>er Phonetik”, PHONEM und Phonet.<br />
Der Algorithmus nach Daitch und Mokotoff legt seinen Schwerpunkt auf das Jüdische<br />
und auf osteuropäische Sprachen. Beide Sprachgruppen haben viele Eigenschaften,<br />
die dem Deutschen ähneln, weshalb dieser Algorithmus mit positiven Erwartungen in die<br />
Untersuchung aufgenommen wurde.<br />
19 Ein Test zeigte, dass im Korpus 2243 von solchen, allein in der Orthographie übereinstimmenden<br />
Kombinationen vorkommen. Wieviele Varianten gleicher Aussprache noch da<strong>zu</strong>kommen, ist nicht ohne<br />
weiteres ab<strong>zu</strong>schätzen. Ich vermute eine obere Grenze bei ca. 0,5 % der deutschen Namen.<br />
20 Soweit dem Autor bekannt, existieren keine verfügbaren Lexika, die in größerem Umfang Morpheme<br />
von Familiennamen enthalten.<br />
21 Dieser Trend wird durch Überset<strong>zu</strong>ngen englischsprachiger Fachliteratur verstärkt.<br />
11