pdf - Universität zu Köln
pdf - Universität zu Köln
pdf - Universität zu Köln

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
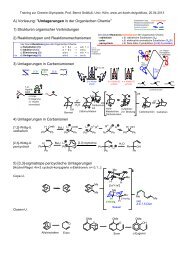
eschreibt mögliche Schreibvarianten des Namens . Dabei sorgt das Fragezeichen<br />
für ein optionales Erscheinen des vorhergehenden Zeichens. Die runden Klammern<br />
gruppieren Unterausdrücke. Das | steht für die Entweder-Oder-Alternative. So steht am<br />
Ende von passenden Zeichenketten entweder ein oder oder ein .<br />
Reguläre Ausdrücke eignen sich hervorragend für die Implementierung von phonologischen<br />
Regeln, da die Funktion beider recht ähnlich ist. Leider haben sich historisch<br />
bedingt mehrere Typen von regulären Ausdrücken entwickelt. Diese sind in der Mächtigkeit<br />
größtenteils äquivalent, unterscheiden sich jedoch in der Syntax. In den folgenden<br />
Verfahren werden die regulären Ausdrücke im Stil von Perl verwendet. Zum einen ist die<br />
Beispiel-Implementation in dieser Sprache verfasst, <strong>zu</strong>m anderen besitzt Perl eine hervorragende<br />
Integration von regulären Ausdrücken. Für andere Programmiersprachen existiert<br />
über die PCRE Library 68 die Möglichkeit, diese Ausdrücke direkt <strong>zu</strong> übernehmen.<br />
8.2 Silbenanzahl<br />
Einige der Verfahren, insbesondere die mit fest kodierter Schlüssellänge, liefern für kurze<br />
Anfragen viele falsche Ergebnisse. Wie sich nach kurzer Analyse zeigte ist ein Teil dieser<br />
Suchergebnisse offensichtlich <strong>zu</strong> lang. Erste Überlegungen für ein Kriterium <strong>zu</strong>r Filterung<br />
könnte somit ein Vergleich der Zeichenkettenlänge sein. So berichtet Kukich (1992) für<br />
das Englische, dass sich ähnlich ausgesprochene Wörter in der Länge der orthographischen<br />
Repräsentation meist unwesentlich unterscheiden. Da sich die Ähnlichkeit jedoch an<br />
der Aussprache orientieren sollte, wird im Folgenden versucht, die Anzahl der Silben <strong>zu</strong><br />
bestimmen.<br />
1,50<br />
1.24<br />
1,25<br />
1,00<br />
0,75<br />
0,50<br />
0,25<br />
0,00 koelner<br />
1.18<br />
exsoundex<br />
1.04<br />
phonix<br />
1.00<br />
soundex<br />
1.00<br />
phonem<br />
0.96<br />
dmeta<br />
0.66<br />
daitch<br />
0.58<br />
metaphone<br />
0.38<br />
phonet2<br />
0.36<br />
phonet<br />
Abbildung 39: Mittlere Anzahl von fehlerhaften Filterungen bei den 50 häufigsten Namen<br />
bei Annahme von Gleichheit der Silbenanzahl.<br />
Von den aus der Literatur bekannten Verfahren für eine Silbentrennung bot sich aufgrund<br />
der Einfachheit das Sonoritätsprinzip an. Ein entsprechender Algorithmus, ähnlich<br />
dem in Spencer (1996, S. 83ff ) beschriebenen, wurde implementiert und ist im Anhang <strong>zu</strong><br />
finden. Eine detailliertere Übersicht über die für die Silbentrennung nach Sonoritätsprinzip<br />
relevante Forschung gibt Niklfeld (1995). Komplexere Verfahren für eine Silbentrennung,<br />
wie z. B. clusterbasierte Ansätze in Müller (2000b) oder den schon in Kapitel 3.6.9<br />
68 siehe hier<strong>zu</strong> http://www.pcre.org<br />
55