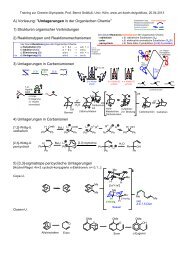
pdf - Universität zu Köln
pdf - Universität zu Köln
pdf - Universität zu Köln

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
und Schrifterkennung. Die vorgestellten Verfahren werden <strong>zu</strong>m Teil auch für die Erkennung<br />
ähnlicher Genomsequenzen in der Bioinformatik benutzt.<br />
4.2 Anwendungsmöglichkeit für eine Phonetische Suche<br />
Damerau-Levenshtein und Hamming-Distanz eignen sich nicht unbedingt für eine Phonetische<br />
Suche auf großen Datenbanken, da für eine Suche die Eingabezeichenkette mit<br />
dem gesamtem Datenbestand verglichen werden muss. Deshalb sind Kriterien für die Einschränkung<br />
der <strong>zu</strong> tätigenden Vergleiche wünschenswert. Bei kleineren Datenbanken kann<br />
dieser Aspekt vernachlässigt werden.<br />
Für N-Gram-basierte Verfahren ist eine Anwendung in relationalen Datenbanken denkbar.<br />
Für eine Suche muss jedoch ein Index der N-Gramme erstellt werden. Dies ist eine<br />
Aufgabe, die viel Speicherplatz benötigt. Somit sollte in großen Datenbanken erst eine<br />
Vorauswahl (Partitionierung) der Daten vorgenommen werden, bevor diese Klasse von<br />
Algorithmen angewendet wird. Dieser Punkt wird in Kapitel 8 noch einmal angesprochen<br />
werden.<br />
Hin<strong>zu</strong> kommt, dass bei Hamming-Distanz und Damerau-Levenshtein bei kurzen Zeichenketten<br />
die Wahrscheinlichkeit groß ist, daß mit wenigen Operationen eine vollkommenen<br />
andere Zeichenkette kurzer Länge gefunden werden. Dies macht die angegebenen<br />
Algorithmen sehr fehleranfällig und erfordert eine Gewichtung nach Länge der Zeichenkette.<br />
Das Auffinden einer optimalen Gewichtung für Zeichenlängen, wäre Aufgabe weiterer<br />
Untersuchungen.<br />
4.3 Hamming-Distanz<br />
Die Hamming-Distanz ist die einfachste Form des Stringvergleichs. Sie zählt die Anzahl<br />
der Zeichen gleicher Position in beiden Eingabezeichenketten, die unterschiedlich sind. Sie<br />
kann im Gegensatz <strong>zu</strong> den folgenden Verfahren schnell errechnet werden. Sie hat für den<br />
Einsatz im natürlichsprachigen Vergleich von Zeichenketten allerdings wenig Aussagekraft,<br />
da verschobene Teilzeichenketten nicht berücksichtigt werden, wie das Beispiel in Abbildung<br />
9 zeigt.<br />
M ü l l e r<br />
M ö l l e r<br />
0 1 0 0 0 0<br />
M ü l l e r<br />
M u e l l e r<br />
0 0 1 0 2 3 4<br />
Abbildung 9: Berechnung der Hamming-Distanz durch Aufaddieren der unterschiedlichen<br />
Buchstabenpositionen. Während eine Distanz von eins im linken Beispiel Müller<br />
vs. Möller ein ganz gutes Maß für Ähnlichkeit ist, ist die Distanz von vier im rechten<br />
Beispiel vs als Ähnlichkeitsmaß indiskutabel.<br />
23