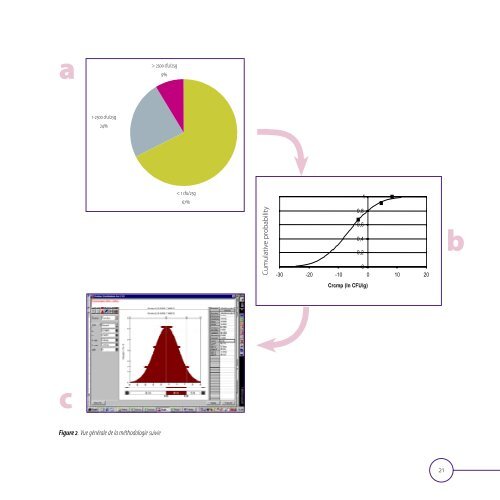
peut être utilisée pour établir une courbe dose/réponse 5 . Les auteurs <strong>de</strong> ce rapport signalent toutefois que différentes recherches <strong>de</strong>vraient être réalisées avant d’utiliser ce modèle pour l’étu<strong>de</strong> <strong>de</strong> l’évaluation <strong>de</strong>s <strong>risques</strong>. D’autres approches pour l’utilisation <strong>de</strong> <strong>la</strong> re<strong>la</strong>tion dose/réponse ont été étudiées <strong>dans</strong> le chapitre caractérisation du risque. Vous trouverez <strong>de</strong> plus amples informations sur l’approche <strong>de</strong> l’évaluation du risque <strong>dans</strong> l’Avis du CSH 7947 6 . Evaluation <strong>de</strong> l’exposition On a utilisé une approche probabiliste tenant compte <strong>de</strong> <strong>la</strong> variabilité au sein <strong>de</strong> <strong>la</strong> popu<strong>la</strong>tion. On tient donc ici compte <strong>de</strong>s distributions <strong>de</strong> données qui ont été évaluées, sur base <strong>de</strong> données <strong>de</strong> <strong>la</strong> littérature, pour <strong>la</strong> contamination croisée, le réchauffement insuffisant et les courbes dose-réponse. Les calculs sont établis avec le programme @RISK (Palisa<strong>de</strong>, UK). En guise d’ « input » pour le programme @RISK, on a utilisé les données (détermination <strong>de</strong> présence ou d’absence <strong>de</strong> Campylobacter <strong>dans</strong> le produit en question) recueillies lors <strong>de</strong>s étu<strong>de</strong>s <strong>de</strong> surveil<strong>la</strong>nce <strong>de</strong> l’AFSCA pour <strong>la</strong> pério<strong>de</strong> <strong>de</strong> 2002, à savoir : notamment 9% <strong>de</strong>s échantillons présentent un niveau <strong>de</strong> contamination > 100/g, <strong>dans</strong> 24% <strong>de</strong>s échantillons, Campylobacter est présent par 25 g <strong>de</strong> produit mais à un niveau < 100/g, et <strong>dans</strong> 67% <strong>de</strong>s échantillons analysés, Campylobacter n’est pas présent par 25 g <strong>de</strong> produit (Figure 2a). Du fait <strong>de</strong> l’absence <strong>de</strong> caractère quantitatif <strong>de</strong> ces données, les échantillons ne peuvent être répartis qu’en 3 catégories. Tout d’abord, les données disponibles re<strong>la</strong>tives à <strong>la</strong> contamination par Campylobacter <strong>de</strong> produits à base <strong>de</strong> poulet ont, comme susmentionné, d’abord été converties en probabilité cumu<strong>la</strong>tive <strong>de</strong> contamination et le logarithme népérien <strong>de</strong> <strong>la</strong> concentration <strong>de</strong> Campylobacter a été calculé (Figure 2b). Pour cette métho<strong>de</strong>, une distribution normale a été appliquée aux 3 points <strong>de</strong> mesures (qui déterminent les limites <strong>de</strong>s catégories), et celle-ci a été utilisée comme input <strong>dans</strong> le programme @RISK. Les situations 2, 3, 4, 5 et 6 sont dérivées <strong>de</strong> cette situation. Ces situations conservent une même valeur <strong>de</strong> moyenne mais resserrent <strong>de</strong> plus en plus <strong>la</strong> courbe en cloche <strong>de</strong> <strong>la</strong> distribution normale (Figure 2c). Alors que, pour <strong>la</strong> situation 1, il ressort <strong>de</strong> <strong>la</strong> distribution normale estimée que 7,45% <strong>de</strong>s échantillons ont un niveau <strong>de</strong> contamination > 100 ufc <strong>de</strong> Campylobacter jejuni /g, les situations 2, 3, 4, 5 et 6 correspon<strong>de</strong>nt à une réduction du nombre d’échantillons qui dépassent <strong>la</strong> limite <strong>de</strong> >100/g, réduction jusqu’à respectivement 4,5%, 1, 97%, 1,05%, 0,44% et 0,21%. Dans les situations 2 à 6 incluses, on tend donc à limiter le pourcentage d’échantillons avec les niveaux <strong>de</strong> contamination les plus élevés. 20
a > 2500 cfu/25g 9% 1-2500 cfu/25g 24% < 1 cfu/25g 67% Cumu<strong>la</strong>tive probability 1 0,8 0,6 0,4 0,2 -30 -20 -10 0 0 10 20 b Crcmp (ln CFU/g) c Figure 2. Vue générale <strong>de</strong> <strong>la</strong> méthodologie suivie 21