

w26M2
w26M2
w26M2

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
Big-Data-Technologien – Wissen für Entscheider<br />
Blöcken, bestehend aus einer ganzen Gruppe von Datensätzen.<br />
Diese Blöcke konnten dann sequenziell gelesen<br />
werden, was bei Bändern und Festplatten verhältnismäßig<br />
schnell geht.<br />
In den letzten Jahren sind die Preise für Hauptspeicher<br />
jedoch so stark gefallen, dass es möglich ist, alle Daten<br />
einer Datenbank in den Hauptspeicher eines Computers<br />
oder mehrerer 187 Computer zu laden. Das hat gleich<br />
mehrere Vorteile, zuerst einmal wird der Zugriff auf die<br />
Daten enorm beschleunigt 188 und darüber hinaus können<br />
wesentlich effizientere Algorithmen verwendet werden,<br />
die nicht auf Blöcken, sondern auf den einzelnen Datensätzen<br />
arbeiten.<br />
Nicht nur die Verarbeitung, auch die Speicherung großer<br />
Datenmengen im Hauptspeicher hat in den letzten Jahren<br />
immer stärker an Bedeutung gewonnen. Gerade analytische<br />
Datenbanken – also Datenbanken, die hauptsächlich<br />
zur Analyse von Datenbeständen verwendet werden –<br />
benötigen schnellen Zugriff auf die zugrundeliegenden<br />
Datenbestände, da für die Analyse meist große Teile eines<br />
Datensatzes gelesen werden müssen. Die ist jedoch nur<br />
durch die Speicherung im Hauptspeicher gewährleistet.<br />
Datenbanken mit In-Memory Technologien gehen jedoch<br />
weit über die Speicherung der Daten im Hauptspeicher<br />
hinaus. Effizientere Algorithmen gepaart mit Datenstrukturen,<br />
die mit Blick auf Analysen optimiert wurden, bringen<br />
enorme Performanz-Gewinne gegenüber transaktionalen<br />
Datenbanksystemen. Einer besonderen Bedeutung<br />
kommt dabei die spaltenbasierte Speicherung zu. Sie<br />
ermöglicht eine besonders effiziente Datenspeicherung,<br />
die gezielt auf die Bedürfnisse von Analysen ausgerichtet<br />
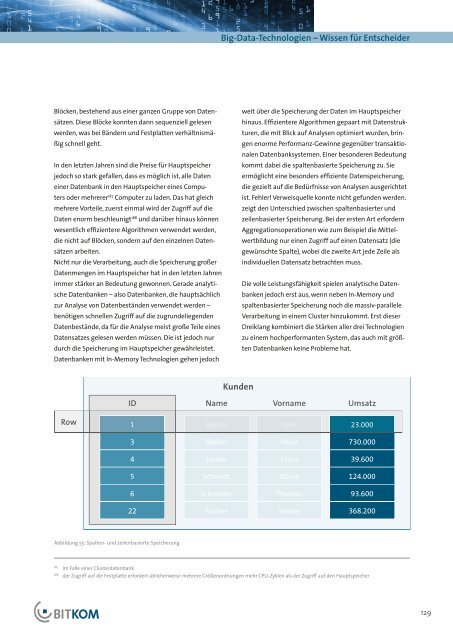
ist. Fehler! Verweisquelle konnte nicht gefunden werden.<br />
zeigt den Unterschied zwischen spaltenbasierter und<br />
zeilenbasierter Speicherung. Bei der ersten Art erfordern<br />
Aggregationsoperationen wie zum Beispiel die Mittelwertbildung<br />
nur einen Zugriff auf einen Datensatz (die<br />
gewünschte Spalte), wobei die zweite Art jede Zeile als<br />
individuellen Datensatz betrachten muss.<br />
Die volle Leistungsfähigkeit spielen analytische Datenbanken<br />
jedoch erst aus, wenn neben In-Memory und<br />
spaltenbasierter Speicherung noch die massiv-parallele<br />
Verarbeitung in einem Cluster hinzukommt. Erst dieser<br />
Dreiklang kombiniert die Stärken aller drei Technologien<br />
zu einem hochperformanten System, das auch mit größten<br />
Datenbanken keine Probleme hat.<br />
Kunden<br />
ID Name Vorname Umsatz<br />
Row<br />
1 Becker Hans 23.000<br />
3<br />
Weber<br />
Peter<br />
730.000<br />
4<br />
Huber<br />
Klaus<br />
39.600<br />
5<br />
Schmidt<br />
Maria<br />
124.000<br />
6<br />
Schneider<br />
Thomas<br />
93.600<br />
22<br />
Fischer<br />
Stefan<br />
368.200<br />
Abbildung 55: Spalten- und zeilenbasierte Speicherung<br />
187<br />
im Falle einer Clusterdatenbank<br />
188<br />
der Zugriff auf die Festplatte erfordert üblicherweise mehrere Größenordnungen mehr CPU-Zyklen als der Zugriff auf den Hauptspeicher<br />
129