- Page 1 and 2:
www.dbeBooks.com - An Ebook Library
- Page 3 and 4:
A C.I.P. Catalogue record for this
- Page 5 and 6:
vi TABLE OF CONTENTS PART 1 - DATAB
- Page 7 and 8:
viii TABLE OF CONTENTS A WIRELESS A
- Page 9 and 10:
CONFERENCE COMMITTEE Honorary Presi
- Page 11 and 12:
Hung, P. (AUSTRALIA) Jahankhani, H.
- Page 13 and 14:
Invited Papers
- Page 15 and 16:
2 ENTERPRISE INFORMATION SYSTEMS VI
- Page 17 and 18:
4 ENTERPRISE INFORMATION SYSTEMS VI
- Page 19 and 20:
6 ENTERPRISE INFORMATION SYSTEMS VI
- Page 21 and 22:
8 ENTERPRISE INFORMATION SYSTEMS VI
- Page 23 and 24:
10 ENTERPRISE INFORMATION SYSTEMS V
- Page 25 and 26:
12 ENTERPRISE INFORMATION SYSTEMS V
- Page 27 and 28:
14 ENTERPRISE INFORMATION SYSTEMS V
- Page 29 and 30:
16 ENTERPRISE INFORMATION SYSTEMS V
- Page 31 and 32:
18 ENTERPRISE INFORMATION SYSTEMS V
- Page 33 and 34:
20 ENTERPRISE INFORMATION SYSTEMS V
- Page 35 and 36:
22 ENTERPRISE INFORMATION SYSTEMS V
- Page 37 and 38:
EVOLUTIONARY PROJECT MANAGEMENT: MU
- Page 39 and 40:
26 ENTERPRISE INFORMATION SYSTEMS V
- Page 41 and 42:
28 ENTERPRISE INFORMATION SYSTEMS V
- Page 43 and 44:
MANAGING COMPLEXITY OF ENTERPRISE I
- Page 45 and 46:
32 ENTERPRISE INFORMATION SYSTEMS V
- Page 47 and 48:
34 ENTERPRISE INFORMATION SYSTEMS V
- Page 49 and 50:
36 ENTERPRISE INFORMATION SYSTEMS V
- Page 51 and 52:
38 ENTERPRISE INFORMATION SYSTEMS V
- Page 53 and 54:
40 ENTERPRISE INFORMATION SYSTEMS V
- Page 55 and 56:
42 ENTERPRISE INFORMATION SYSTEMS V
- Page 57 and 58:
44 ENTERPRISE INFORMATION SYSTEMS V
- Page 59 and 60:
46 ENTERPRISE INFORMATION SYSTEMS V
- Page 61 and 62:
48 ENTERPRISE INFORMATION SYSTEMS V
- Page 63 and 64:
50 ENTERPRISE INFORMATION SYSTEMS V
- Page 65 and 66:
52 ENTERPRISE INFORMATION SYSTEMS V
- Page 67 and 68:
ASSESSING EFFORT PREDICTION MODELS
- Page 69 and 70:
ASSESSING EFFORT PREDICTION MODELS
- Page 71 and 72:
ASSESSING EFFORT PREDICTION MODELS
- Page 73 and 74:
ASSESSING EFFORT PREDICTION MODELS
- Page 75 and 76:
ORGANIZATIONAL AND TECHNOLOGICAL CR
- Page 77 and 78:
ORGANIZATIONAL AND TECHNOLOGICAL CR
- Page 79 and 80:
ASAP Processes W Project Kickoff A
- Page 81 and 82:
ORGANIZATIONAL AND TECHNOLOGICAL CR
- Page 83 and 84:
since it means changing the relevan
- Page 85 and 86:
ACME-DB: AN ADAPTIVE CACHING MECHAN
- Page 87 and 88:
ACME-DB: AN ADAPTIVE CACHING MECHAN
- Page 89 and 90:
Hit Rate (%) ACME-DB: AN ADAPTIVE C
- Page 91 and 92:
5.3.6 Effect on all Policies by Int
- Page 93 and 94:
ACKNOWLEDGEMENTS We would like to t
- Page 95 and 96:
This paper describes the data sampl
- Page 97 and 98:
The major limit A of the operation
- Page 99 and 100:
RELATIONAL SAMPLING FOR DATA QUALIT
- Page 101 and 102:
TOWARDS DESIGN RATIONALES OF SOFTWA
- Page 103 and 104:
((Brown et al., 1998), pp. 159-190,
- Page 105 and 106:
sive data filtering, presentation (
- Page 107 and 108:
• implementation changes in servi
- Page 109 and 110:
MEMORY MANAGEMENT FOR LARGE SCALE D
- Page 111 and 112:
Data Rate [bytes/sec] 1600000 14000
- Page 113 and 114:
E.g., DV Camcorder Camera Packets (
- Page 115 and 116:
Procedure CheckOptimal (n rs 1 ...n
- Page 117 and 118:
MEMORY MANAGEMENT FOR LARGE SCALE D
- Page 119 and 120:
PART 2 Artificial Intelligence and
- Page 121 and 122:
110 ENTERPRISE INFORMATION SYSTEMS
- Page 123 and 124:
112 ENTERPRISE INFORMATION SYSTEMS
- Page 125 and 126:
114 ENTERPRISE INFORMATION SYSTEMS
- Page 127 and 128:
DYNAMIC MULTI-AGENT BASED VARIETY F
- Page 129 and 130:
118 ENTERPRISE INFORMATION SYSTEMS
- Page 131 and 132:
120 ENTERPRISE INFORMATION SYSTEMS
- Page 133 and 134:
122 ENTERPRISE INFORMATION SYSTEMS
- Page 135 and 136:
124 ENTERPRISE INFORMATION SYSTEMS
- Page 137 and 138:
126 ENTERPRISE INFORMATION SYSTEMS
- Page 139 and 140:
128 ENTERPRISE INFORMATION SYSTEMS
- Page 141 and 142:
130 ENTERPRISE INFORMATION SYSTEMS
- Page 143 and 144:
132 ENTERPRISE INFORMATION SYSTEMS
- Page 145 and 146:
134 ENTERPRISE INFORMATION SYSTEMS
- Page 147 and 148:
136 ENTERPRISE INFORMATION SYSTEMS
- Page 149 and 150:
138 ENTERPRISE INFORMATION SYSTEMS
- Page 151 and 152:
140 ENTERPRISE INFORMATION SYSTEMS
- Page 153 and 154:
142 ENTERPRISE INFORMATION SYSTEMS
- Page 155 and 156:
144 ENTERPRISE INFORMATION SYSTEMS
- Page 157 and 158:
146 ENTERPRISE INFORMATION SYSTEMS
- Page 159 and 160:
148 ENTERPRISE INFORMATION SYSTEMS
- Page 161 and 162:
150 ENTERPRISE INFORMATION SYSTEMS
- Page 163 and 164:
152 ENTERPRISE INFORMATION SYSTEMS
- Page 165 and 166:
154 ENTERPRISE INFORMATION SYSTEMS
- Page 167 and 168:
156 ENTERPRISE INFORMATION SYSTEMS
- Page 169 and 170:
AN EXPERIENCE IN MANAGEMENT OF IMPR
- Page 171 and 172:
160 ENTERPRISE INFORMATION SYSTEMS
- Page 173 and 174: 162 ENTERPRISE INFORMATION SYSTEMS
- Page 175 and 176: 164 ENTERPRISE INFORMATION SYSTEMS
- Page 177 and 178: 166 ENTERPRISE INFORMATION SYSTEMS
- Page 179 and 180: ANALYSIS AND RE-ENGINEERING OF WEB
- Page 181 and 182: Module p0 Customer Itinerary Send I
- Page 183 and 184: departments: the marketing dept. se
- Page 185 and 186: • An acyclic module M is usable,
- Page 187 and 188: BALANCING STAKEHOLDER’S PREFERENC
- Page 189 and 190: The scenarios will provide an abstr
- Page 191 and 192: BALANCING STAKEHOLDER'S PREFERENCES
- Page 193 and 194: BALANCING STAKEHOLDER'S PREFERENCES
- Page 195 and 196: A POLYMORPHIC CONTEXT FRAME TO SUPP
- Page 197 and 198: A POLYMORPHIC CONTE XT FRAME TO SUP
- Page 199 and 200: A POLYMORPHIC CONTE XT FRAME TO SUP
- Page 201 and 202: A POLYMORPHIC CONTE XT FRAME TO SUP
- Page 203 and 204: FEATURE MATCHING IN MODEL-BASED SOF
- Page 205 and 206: combination of solution domains - a
- Page 207 and 208: • features for all the concepts:
- Page 209 and 210: Existence In both steps it is possi
- Page 211 and 212: matching strategies are maximal, mi
- Page 213 and 214: TOWARDS A META MODEL FOR DESCRIBING
- Page 215 and 216: elementary message (ae-message) can
- Page 217 and 218: problems on a pragmatic level, whic
- Page 219 and 220: TOWARDS A META MODEL FOR DESCRIBING
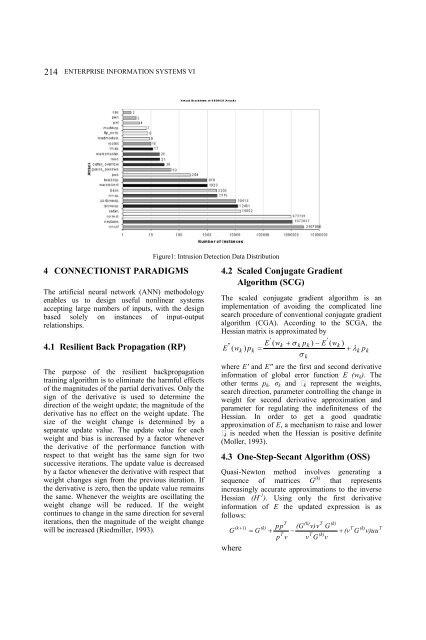
- Page 221 and 222: INTRUSION DETECTION SYSTEMS USING A
- Page 223: INTRUSION DETECTION SYSTEMS USING A
- Page 227 and 228: Table 5: Performance Comparison of
- Page 229 and 230: A USER-CENTERED METHODOLOGY TO GENE
- Page 231 and 232: carries out the second phase of the
- Page 233 and 234: 1 1 1 1 2 PROCESS STORE ENTITY EDGE
- Page 235 and 236: constraints rules. KOGGE (Ebert et
- Page 237 and 238: PART 4 Software Agents and Internet
- Page 239 and 240: 230 ENTERPRISE INFORMATION SYSTEMS
- Page 241 and 242: 232 ENTERPRISE INFORMATION SYSTEMS
- Page 243 and 244: 234 ENTERPRISE INFORMATION SYSTEMS
- Page 245 and 246: 236 ENTERPRISE INFORMATION SYSTEMS
- Page 247 and 248: 238 ENTERPRISE INFORMATION SYSTEMS
- Page 249 and 250: 240 ENTERPRISE INFORMATION SYSTEMS
- Page 251 and 252: 242 ENTERPRISE INFORMATION SYSTEMS
- Page 253 and 254: 244 ENTERPRISE INFORMATION SYSTEMS
- Page 255 and 256: 246 ENTERPRISE INFORMATION SYSTEMS
- Page 257 and 258: 248 ENTERPRISE INFORMATION SYSTEMS
- Page 259 and 260: 250 ENTERPRISE INFORMATION SYSTEMS
- Page 261 and 262: 252 ENTERPRISE INFORMATION SYSTEMS
- Page 263 and 264: 254 ENTERPRISE INFORMATION SYSTEMS
- Page 265 and 266: 256 ENTERPRISE INFORMATION SYSTEMS
- Page 267 and 268: 258 ENTERPRISE INFORMATION SYSTEMS
- Page 269 and 270: 260 ENTERPRISE INFORMATION SYSTEMS
- Page 271 and 272: 262 ENTERPRISE INFORMATION SYSTEMS
- Page 273 and 274: 264 ENTERPRISE INFORMATION SYSTEMS
- Page 275 and 276:
266 ENTERPRISE INFORMATION SYSTEMS
- Page 277 and 278:
268 ENTERPRISE INFORMATION SYSTEMS
- Page 279 and 280:
270 ENTERPRISE INFORMATION SYSTEMS
- Page 281 and 282:
272 ENTERPRISE INFORMATION SYSTEMS
- Page 283 and 284:
274 ENTERPRISE INFORMATION SYSTEMS
- Page 285 and 286:
CABA 2 L A BLISS PREDICTIVE COMPOSI
- Page 287 and 288:
y disables evidencing severe mental
- Page 289 and 290:
Figure 4: Symbols emission in DAR-H
- Page 291 and 292:
they evidence a generalization erro
- Page 293 and 294:
A METHODOLOGY FOR INTERFACE DESIGN
- Page 295 and 296:
and mobility loss coupled with redu
- Page 297 and 298:
Tradeoff: The default input is poss
- Page 299 and 300:
Sessions on the VABS which are held
- Page 301 and 302:
A CONTACT RECOMMENDER SYSTEM FOR A
- Page 303 and 304:
A CONTACT RECOMMENDER SYSTEM FOR A
- Page 305 and 306:
- "Going to the sources". The user
- Page 307 and 308:
Here are the matrix W and P for our
- Page 309 and 310:
EMOTION SYNTHESIS IN VIRTUAL ENVIRO
- Page 311 and 312:
theme turns out to be surprisingly
- Page 313 and 314:
6 FROM FEATURES TO SYMBOLS 6.1 Face
- Page 315 and 316:
sions are described by different em
- Page 317 and 318:
Electronic Imaging 2000 Conference
- Page 319 and 320:
to the accessibility problem for th
- Page 321 and 322:
Figure 3: Hierarchical View of the
- Page 323 and 324:
4 CONCLUSIONS AND FUTURE WORK On th
- Page 325 and 326:
PERSONALISED RESOURCE DISCOVERY SEA
- Page 327 and 328:
PERSONALISED RESOURCE DISCOVERY SEA
- Page 329 and 330:
profile, the user defines his curre
- Page 331 and 332:
PERSONALISED RESOURCE DISCOVERY SEA
- Page 333 and 334:
Abdelkafi, N. .....................